- Nginx的核心!!! 负载均衡、反向代理
確定饿的猫
nginx负载均衡
目录负载均衡1.轮询2.最少连接数3.IP哈希4.加权轮询5.最少时间6.一致性哈希反向代理测试之前讲过Nginx的简介和正则表达式,那些都是Nginx较为基础的操作,Nginx最重要的最核心的功能,当属反向代理和负载均衡了。负载均衡负载均衡可能好理解一点,从字面上来看,就是某个服务器不堪重负的时候,将它的请求均衡一下,前提是有多个后端服务器,如果只有一个那自然均衡不了,一般情况下都不会单挂的。N
- 深入讲解 Memcached
杨哥带你写代码
memcached数据库缓存
深入讲解Memcached目录Memcached的数据存储机制Memcached的一致性哈希Memcached的内存管理Memcached的集群架构Memcached与Redis对比高级使用技巧性能优化Memcached的数据存储机制Memcached采用了key-value存储模型,所有数据以键值对的形式存储在内存中。数据存储过程如下:键值对的存储键:键是唯一标识数据的字符串,最大长度为250字
- 深入理解nginx一致性哈希负载均衡模块[下]
码农心语
nginx学习LINUXc++开发nginx哈希算法负载均衡upstream一致性哈希
上接深入理解nginx一致性哈希负载均衡模块[上]3.源码分析 nginx的一致性哈希功能是通过ngx_http_upstream_hash_module来提供的,下面来整体通过ngx_http_upstream_hash_module来学习一下一致性哈希算法的实现原理。3.1配置指令分析 要启用Nginx的一致性哈希负载均衡算法,你需要使用ngx_http_upstream_hash_mod
- 论文阅读-基于动态权重的一致性哈希微服务负载均衡优化
向来痴_
负载均衡论文论文阅读微服务负载均衡
论文名称:基于动态权重的一致性哈希微服务负载均衡优化摘要随着互联网技术的发展,互联网服务器集群的负载能力正面临前所未有的挑战。在这样的背景下,实现合理的负载均衡策略变得尤为重要。为了达到最佳的效率,可以利用一致性哈希算法对集群负载均衡系统进行负载分配。针对微服务架构的服务器集群场景,本文分析了集群负载均衡的特性,并提出了一种基于虚拟节点的一致性哈希环设计与分割方法,以及基于动态权值的分配策略。在一
- 得物面试:Redis用哈希槽,而不是一致性哈希,为什么?
40岁资深老架构师尼恩
面试面试redis哈希算法系统架构架构java大数据
尼恩说在前面在40岁老架构师尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题:Redis为何用哈希槽而不用一致性哈希?最近有小伙伴在面试网易,又遇到了相关的面试题。小伙伴懵了,因为没有遇到过,所以支支吾吾的说了几句,面试官不满意,面试挂了。所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛
- 哈希函数和哈希表
哈希算法算法数据结构
哈希函数和哈希表1.哈希函数和运用2.哈希表的时间复杂度3.布隆过滤器4.一致性哈希和负载均衡1.哈希函数和运用哈希函数指将哈希表中元素的关键键值映射为元素存储位置的函数。哈希函数有有一些性质,是可以运用的,元素经过哈希函数映射到一个有限的集合中,这些数在集合中的分布是均匀的,就像沙子均匀散落在盘中一样。常见的哈希函数有MD5和Shal两种。MD5它哈希值的范围是0~264-1,Shal它的哈希值
- 分布式存储系统学习笔记(三)—分布式键值系统(1)—Amazon Dynamo
不会算命的赵半仙
架构分布式分布式系统
1.概述Dynamo以很简单的键值方式存储数据,不支持复杂的查询。Dynamo中存储的是数据值的原始形式,不解析数据的具体内容。Dynamo主要用于Amazon购物车和S3云存储服务。Dynamo通过组合P2P的各种技术打造了线上可运行的分布式键值系统,下表列出了Dynamo设计时面临的问题及最终采取的解决方案:2.数据分布Dynamo采用一致性哈希将数据分布到多个存储节点中(博文:一天不学习我浑
- Redis(九)集群(cluster)
Lucky_Turtle
Javaredis数据库缓存
文章目录概述作用1.redis集群的槽位slot2.redis集群的分片3.第1,2点的优势:**最大优势,方便扩缩容和数据分派查找**4.slot槽位映射,一般业界有3种解决方案第一种:哈希取余分区第二种:一致性哈希算法分区第三种:哈希槽分区为什么redis集群的最大槽数是16384个?注意点案例1、配置2、集群读写3、主从容错迁移4、主从扩容5、主从缩容集群常用命令和CRC16命令不在同一个s
- [转载]一个速度快内存占用小的一致性哈希算法
gensmusic
转载自:http://colobu.com/2016/03/22/jump-consistent-hash/一个速度快内存占用小的一致性哈希算法JumpConsistentHash一致性哈希最早由MIT的Karger提出,在发表于1997年的论文ConsistentHashingandRandomTrees:DistributedCachingProtocolsforRelievingHotSpo
- 论文阅读-在分布式数据库环境中对哈希算法进行负载均衡基准测试
向来痴_
分布式数据库负载均衡论文阅读
论文名称:BenchmarkingHashingAlgorithmsforLoadBalancinginaDistributedDatabaseEnvironment摘要现代高负载应用使用多个数据库实例存储数据。这样的架构需要数据一致性,并且确保数据在节点之间均匀分布很重要。负载均衡被用来实现这些目标。几乎所有负载均衡系统的核心都是哈希算法。自经典一致性哈希引入以来,已经为此目的设计了许多算法。负
- Docker进阶篇-reids集群
陪我养猪吧
docker运维linuxdocker容器redis
一、集群存储算法分布式存储的常见算法:哈希取余分区一致性哈希算法分区哈希槽分区1、哈希取余分区描述:每次读写操作都是根据公式:Hash(key)%N(其中,key是要存入Redis的键名,N是Redis集群的机器台数),计算出哈希值,用来决定数据映射到哪一个节点。优点:简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分
- 第10章 集群
leon4ever
1.数据分布1.1数据分布理论哈希分区:离散度好,数据分布业务无关顺序分区:离散度易倾斜,数据分布业务相关,可顺序访问节点取余分区:hash(key)%N,当节点数量变化时,映射关系需重新计算,会导致数据迁移,通常翻倍扩容一致性哈希分区:为系统中每个节点分配一个token,构成一个哈希环加减节点会造成部分数据失效不适合少量节点普通的一致性哈希分区在增加节点时要增加一倍或减去一半才能保证数据负载均衡
- Kong工作原理 - 负载均衡 - 负载均衡算法
费曼乐园
Kongkonggateway
负载均衡器支持以下负载均衡算法:1.轮询(Round-robin)2.一致性哈希(ConsistentHashing)3.最少连接(LeastConnections)4.延迟(Latency)这些算法仅在使用upstream实体时可用,详见高级负载均衡。注意:对于所有这些算法,重要的是要了解如何设置每个后端的权重和端口。轮询轮询算法将以加权方式进行。它在结果上与基于DNS的负载均衡相同,但由于它是
- Kong工作原理 - 负载均衡 - 基于DNS的负载均衡
费曼乐园
Kongkonggateway
Kong提供多种请求负载均衡到多个后端服务的方式:默认的基于DNS的方法,以及使用Upstream实体的一组高级负载均衡算法。默认情况下启用DNS负载均衡器,仅限于循环调度负载均衡。Upstream实体还具有健康检查和断路器功能,除了更高级的算法,如最小连接数、一致性哈希和最低延迟。根据您的基础设施,请参考相应的DNS注意事项。每个使用主机名(而不是IP地址)定义的服务,如果该名称解析为多个IP地
- MySQL集群架构(三):分库分表
一白丁
Mysql
分库分表前言拆分方式垂直拆分垂直拆分优点垂直拆分缺点水平拆分水平拆分优点水平拆分缺点主键策略UUIDCOMB(UUID变种)SNOWFLAKE数据库ID表Redis生成ID分片分片概念分片策略基于范围分片哈希取模分片一致性哈希分片扩容方案停机扩容平滑扩容总结前言之前介绍了mysql集群中的高可用双主模式,本节将介绍缓解数据库压力的分库分表策略。互联网系统需要处理大量用户的请求。比如微信日活用户破1
- 浅析一致性哈希算法
秋慕云
一、分布式算法在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括:轮循算法(RoundRobin)、哈希算法(HASH)、最少连接算法(LeastConnection)、响应速度算法(ResponseTime)、加权法(Weighted)等。其中哈希算法是最为常用的算法。典型的应用场景:有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均分发到每台服务器上,每台机器负责1/N的服
- 一致性Hash详解
萧十一郎君
哈希算法算法一致性哈希Java
引言在分布式系统中,数据的分布和负载均衡是非常重要的问题。传统的哈希算法在增加或删除节点时,会导致大量的数据迁移,影响系统的性能和可用性。为了解决这个问题,一致性哈希算法应运而生。本文将详细介绍一致性哈希算法的原理,并描述该算法的应用场景。1.哈希环一致性哈希算法的核心思想是将节点和数据都映射到一个哈希环上。哈希环是一个虚拟的环形空间,节点和数据在环上均匀分布。具体的映射方式可以使用哈希函数将节点
- Dubbo的几个负载均衡类--最短响应时间
黄国海Argo
Dubbodubbo负载均衡
-----------------看过之前一致性哈希和最少活跃书的可以跳过-----------------链接在此:Dubbo的几个负载均衡类--一致性哈希Dubbo的几个负载均衡类--最少活跃数Dubbo的几个负载均衡类--轮询Dubbo的几个负载均衡类--随机消费者发起调用过程中涉及如下几步1:接口调用,比如DemoService.demoMethod2:InvokerInvocationH
- Dubbo的几个负载均衡类-随机
黄国海Argo
Dubbodubbo负载均衡
-----------------看过之前一致性哈希和最少活跃书的可以跳过-----------------链接在此:Dubbo的几个负载均衡类--一致性哈希Dubbo的几个负载均衡类--最少活跃数消费者发起调用过程中涉及如下几步1:接口调用,比如DemoService.demoMethod2:InvokerInvocationHandler.invoker:消费端启动时,通过JavassistP
- Dubbo的几个负载均衡策略-轮询
黄国海Argo
Dubbodubbo负载均衡
-----------------看过之前一致性哈希的可以跳过-----------------链接在此:Dubbo的几个负载均衡类--一致性哈希Dubbo的几个负载均衡类--最少活跃数Dubbo的几个负载均衡类--随机消费者发起调用过程中涉及如下几步1:接口调用,比如DemoService.demoMethod2:InvokerInvocationHandler.invoker:消费端启动时,通
- Dubbo的几个负载均衡类--最少活跃数
黄国海Argo
Dubbodubbo负载均衡
-----------------看过之前一致性哈希的可以跳过-----------------链接在此:Dubbo的几个负载均衡类--一致性哈希消费者发起调用过程中涉及如下几步1:接口调用,比如DemoService.demoMethod2:InvokerInvocationHandler.invoker:消费端启动时,通过JavassistProxyFactory.getProxy反射获取代理
- 【Redis】正确回答RDB-AOF持久化策略面试问题
GitHub质检员
优质好文分享redis面试数据库
一、关于Redis的面试真题:如何用Redis实现分布式锁?简要说说你对RDB-AOF持久化策略的理解?RDB-AOF持久化策略的优缺点在哪?经典问题:先更新数据库,还是先更新缓存?失效策略:缓存过期都有哪些策略?负载均衡:一致性哈希解决了哪些问题?缓存高可用:缓存如何保证高可用?redis集群模式的工作原理能说一下么?在集群模式下,redis的key是如何寻址的?分布式寻址都有哪些算法?了解一致
- Nginx 负载均衡(轮询、一致性哈希、加权哈希)
JaYthon
轮询按照请求时间依次分配到后端服务器中,宕掉的服务器可以自动剔除一致性哈希使用一致性哈希算法进行负载均衡可以提高弹性,减少缩容扩容带来的影响加权哈希如果服务器的性能不一致的话,可以采用加权哈希进行负载均衡。性能好的则权重设置高,承担更多的请求,反之亦然
- glusterFS
MoonSoin
k8s云原生glusterFS文件存储kubernetes
一.概念1.介绍gluster是一个横向扩展的分布式文件系统,可将来自多个服务器的磁盘存储资源整合到一个全局名称空间中,可以根据存储消耗需求快速调配额外的存储。它将自动故障转移作为主要功能.分布式存储系统.集群式NAS存储.无集中式元数据服务,采用Hash算法定位.一致性哈希DHT.Hash值落在哪个范围内,数据就存储在哪里.弹性卷管理.自动做了raid.2.优点缩放到几PB.处理数千个客户.开源
- 2022Java最新真实面试题汇总
一头狒狒
javajava开发语言面试架构职场和发展
一、面经适当夸夸面试官(或所在公司)不会有坏处如果某个问题完全不会(或稍微懂点),直接承认(或略作回答)并把话题引导向类似话题(redis集群的槽机制->一致性哈希)第二条如果完全不会,可以在表达自己不会之后给与面试官一点反问,表现出自己的求知欲与关注度所有话题都可以适当性的发散,不要太发散以免显得有备而来所有问题(熟悉或不熟悉)的回答不要太快,给面试官反应与打断的时间,同时方便自己梳理逻辑,显得
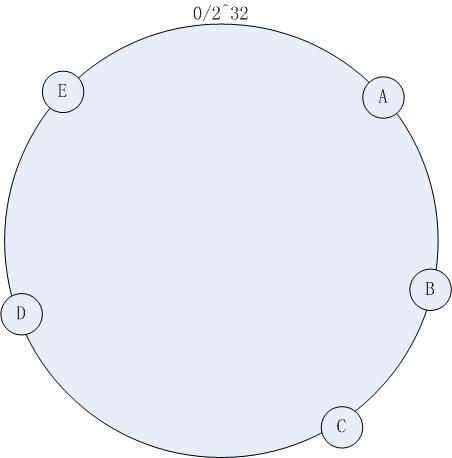
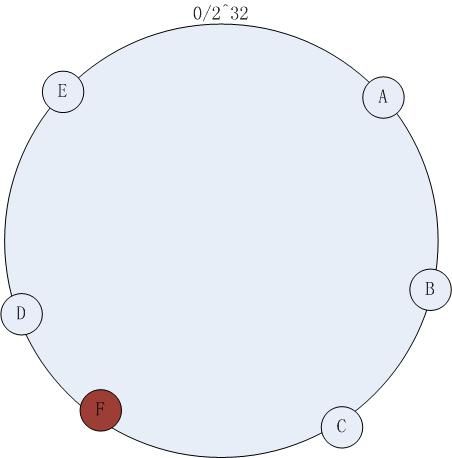
- 图解一致性哈希算法,全网(小区局域网)最通俗易懂
码农小光
来自公众号:后端技术学堂作者:LemonCoder正文共5558字,预计阅读时长8分钟好久不见小伙伴们,最近都快忙晕了,后端技术学堂差点停课,不过还是抽时间写了这篇文章带大家一起学习一致性哈希算法。很多同学应该都知道什么是哈希函数,在后端面试和开发中会遇到「一致性哈希」,那么什么是一致性哈希呢?名字听起来很厉害的样子,其实原理并不复杂,这篇文章带你彻底搞懂一致性哈希!进入主题前,先来一场紧张刺激的
- 数据结构与算法面试分享(二十二):一致性Hash算法
之乎者也·
数据结构与算法算法面试哈希算法
目录一致性Hash算法引入一致性Hash算法简介一致性Hash算法Hash环删除节点增加节点不平衡的问题虚拟节点一致性Hash算法引入在分布式集群中,对机器的添加删除,或者机器故障后自动脱离集群这些操作是分布式集群管理最基本的功能。如果采用常用的hash(object)%N算法,那么在有机器添加或者删除后,很多原有的数据就无法找到了,这样严重的违反了单调性原则。一致性Hash算法简介一致性哈希算法
- Redis——Cluster
黄金矿工00七
为什么需要集群?高并发:大数据:集群分区方式数据分区顺序分区哈希分区节点取余分区客户端分片:进行哈希+取余节点取余扩容:存在问题:当需要扩充节点的时候,需要进行大量的数据迁移(解决方案:翻倍扩容,会降低数据的迁移量)图片.png一致性哈希分区一致性哈希分区采用一致性哈希算法进行分区,由客户端计算并且提供一致性hash,基本步骤如下;客户端分片:进行哈希+(顺时针)优化取余首先求出Redis服务器(
- 微信红包业务,为什么采用轮询算法?
敲代码的程序狗
Java算法程序员算法服务器java负载均衡程序员
目录前言基本的负载算法平滑加权轮询算法一致性哈希算法最小活跃数算法最优响应算法总结前言负载均衡这个概念,几乎在所有支持高可用的技术栈中都存在,例如微服务、分库分表、各大中间件(MQ、Redis、MyCat、Nginx、ES)等,也包括云计算、云调度、大数据中也是炙手可热的词汇。负载均衡策略主要分为静态与动态两大类:**静态调度算法:**指配置后只会依据配置好的策略进行请求分发的算法。**动态调度算
- Redis部署-集群
正经程序猿
redisredisjava数据库
目录集群数据分片算法哈希求余一致性哈希算法哈希槽分区算法redis集群搭建1.创建目录和配置.2.将上述redis节点.构建成集群3.使用客户端连接集群集群模式下的故障转移流程1.故障判定2.故障迁移集群扩容集群广义上的集群,只要是多个机器,构成了分布式系统,都可以称为是一个"集群".前面的主从模式和哨兵模式也可以称为是广义的集群.狭义的集群,redis提供的集群模式,在这个集群模式之下,主要是姐
- 项目中 枚举与注解的结合使用
飞翔的马甲
javaenumannotation
前言:版本兼容,一直是迭代开发头疼的事,最近新版本加上了支持新题型,如果新创建一份问卷包含了新题型,那旧版本客户端就不支持,如果新创建的问卷不包含新题型,那么新旧客户端都支持。这里面我们通过给问卷类型枚举增加自定义注解的方式完成。顺便巩固下枚举与注解。
一、枚举
1.在创建枚举类的时候,该类已继承java.lang.Enum类,所以自定义枚举类无法继承别的类,但可以实现接口。
- 【Scala十七】Scala核心十一:下划线_的用法
bit1129
scala
下划线_在Scala中广泛应用,_的基本含义是作为占位符使用。_在使用时是出问题非常多的地方,本文将不断完善_的使用场景以及所表达的含义
1. 在高阶函数中使用
scala> val list = List(-3,8,7,9)
list: List[Int] = List(-3, 8, 7, 9)
scala> list.filter(_ > 7)
r
- web缓存基础:术语、http报头和缓存策略
dalan_123
Web
对于很多人来说,去访问某一个站点,若是该站点能够提供智能化的内容缓存来提高用户体验,那么最终该站点的访问者将络绎不绝。缓存或者对之前的请求临时存储,是http协议实现中最核心的内容分发策略之一。分发路径中的组件均可以缓存内容来加速后续的请求,这是受控于对该内容所声明的缓存策略。接下来将讨web内容缓存策略的基本概念,具体包括如如何选择缓存策略以保证互联网范围内的缓存能够正确处理的您的内容,并谈论下
- crontab 问题
周凡杨
linuxcrontabunix
一: 0481-079 Reached a symbol that is not expected.
背景:
*/5 * * * * /usr/IBMIHS/rsync.sh
- 让tomcat支持2级域名共享session
g21121
session
tomcat默认情况下是不支持2级域名共享session的,所有有些情况下登陆后从主域名跳转到子域名会发生链接session不相同的情况,但是只需修改几处配置就可以了。
打开tomcat下conf下context.xml文件
找到Context标签,修改为如下内容
如果你的域名是www.test.com
<Context sessionCookiePath="/path&q
- web报表工具FineReport常用函数的用法总结(数学和三角函数)
老A不折腾
Webfinereport总结
ABS
ABS(number):返回指定数字的绝对值。绝对值是指没有正负符号的数值。
Number:需要求出绝对值的任意实数。
示例:
ABS(-1.5)等于1.5。
ABS(0)等于0。
ABS(2.5)等于2.5。
ACOS
ACOS(number):返回指定数值的反余弦值。反余弦值为一个角度,返回角度以弧度形式表示。
Number:需要返回角
- linux 启动java进程 sh文件
墙头上一根草
linuxshelljar
#!/bin/bash
#初始化服务器的进程PId变量
user_pid=0;
robot_pid=0;
loadlort_pid=0;
gateway_pid=0;
#########
#检查相关服务器是否启动成功
#说明:
#使用JDK自带的JPS命令及grep命令组合,准确查找pid
#jps 加 l 参数,表示显示java的完整包路径
#使用awk,分割出pid
- 我的spring学习笔记5-如何使用ApplicationContext替换BeanFactory
aijuans
Spring 3 系列
如何使用ApplicationContext替换BeanFactory?
package onlyfun.caterpillar.device;
import org.springframework.beans.factory.BeanFactory;
import org.springframework.beans.factory.xml.XmlBeanFactory;
import
- Linux 内存使用方法详细解析
annan211
linux内存Linux内存解析
来源 http://blog.jobbole.com/45748/
我是一名程序员,那么我在这里以一个程序员的角度来讲解Linux内存的使用。
一提到内存管理,我们头脑中闪出的两个概念,就是虚拟内存,与物理内存。这两个概念主要来自于linux内核的支持。
Linux在内存管理上份为两级,一级是线性区,类似于00c73000-00c88000,对应于虚拟内存,它实际上不占用
- 数据库的单表查询常用命令及使用方法(-)
百合不是茶
oracle函数单表查询
创建数据库;
--建表
create table bloguser(username varchar2(20),userage number(10),usersex char(2));
创建bloguser表,里面有三个字段
&nbs
- 多线程基础知识
bijian1013
java多线程threadjava多线程
一.进程和线程
进程就是一个在内存中独立运行的程序,有自己的地址空间。如正在运行的写字板程序就是一个进程。
“多任务”:指操作系统能同时运行多个进程(程序)。如WINDOWS系统可以同时运行写字板程序、画图程序、WORD、Eclipse等。
线程:是进程内部单一的一个顺序控制流。
线程和进程
a. 每个进程都有独立的
- fastjson简单使用实例
bijian1013
fastjson
一.简介
阿里巴巴fastjson是一个Java语言编写的高性能功能完善的JSON库。它采用一种“假定有序快速匹配”的算法,把JSON Parse的性能提升到极致,是目前Java语言中最快的JSON库;包括“序列化”和“反序列化”两部分,它具备如下特征:
- 【RPC框架Burlap】Spring集成Burlap
bit1129
spring
Burlap和Hessian同属于codehaus的RPC调用框架,但是Burlap已经几年不更新,所以Spring在4.0里已经将Burlap的支持置为Deprecated,所以在选择RPC框架时,不应该考虑Burlap了。
这篇文章还是记录下Burlap的用法吧,主要是复制粘贴了Hessian与Spring集成一文,【RPC框架Hessian四】Hessian与Spring集成
- 【Mahout一】基于Mahout 命令参数含义
bit1129
Mahout
1. mahout seqdirectory
$ mahout seqdirectory
--input (-i) input Path to job input directory(原始文本文件).
--output (-o) output The directory pathna
- linux使用flock文件锁解决脚本重复执行问题
ronin47
linux lock 重复执行
linux的crontab命令,可以定时执行操作,最小周期是每分钟执行一次。关于crontab实现每秒执行可参考我之前的文章《linux crontab 实现每秒执行》现在有个问题,如果设定了任务每分钟执行一次,但有可能一分钟内任务并没有执行完成,这时系统会再执行任务。导致两个相同的任务在执行。
例如:
<?
//
test
.php
- java-74-数组中有一个数字出现的次数超过了数组长度的一半,找出这个数字
bylijinnan
java
public class OcuppyMoreThanHalf {
/**
* Q74 数组中有一个数字出现的次数超过了数组长度的一半,找出这个数字
* two solutions:
* 1.O(n)
* see <beauty of coding>--每次删除两个不同的数字,不改变数组的特性
* 2.O(nlogn)
* 排序。中间
- linux 系统相关命令
candiio
linux
系统参数
cat /proc/cpuinfo cpu相关参数
cat /proc/meminfo 内存相关参数
cat /proc/loadavg 负载情况
性能参数
1)top
M:按内存使用排序
P:按CPU占用排序
1:显示各CPU的使用情况
k:kill进程
o:更多排序规则
回车:刷新数据
2)ulimit
ulimit -a:显示本用户的系统限制参
- [经营与资产]保持独立性和稳定性对于软件开发的重要意义
comsci
软件开发
一个软件的架构从诞生到成熟,中间要经过很多次的修正和改造
如果在这个过程中,外界的其它行业的资本不断的介入这种软件架构的升级过程中
那么软件开发者原有的设计思想和开发路线
- 在CentOS5.5上编译OpenJDK6
Cwind
linuxOpenJDK
几番周折终于在自己的CentOS5.5上编译成功了OpenJDK6,将编译过程和遇到的问题作一简要记录,备查。
0. OpenJDK介绍
OpenJDK是Sun(现Oracle)公司发布的基于GPL许可的Java平台的实现。其优点:
1、它的核心代码与同时期Sun(-> Oracle)的产品版基本上是一样的,血统纯正,不用担心性能问题,也基本上没什么兼容性问题;(代码上最主要的差异是
- java乱码问题
dashuaifu
java乱码问题js中文乱码
swfupload上传文件参数值为中文传递到后台接收中文乱码 在js中用setPostParams({"tag" : encodeURI( document.getElementByIdx_x("filetag").value,"utf-8")});
然后在servlet中String t
- cygwin很多命令显示command not found的解决办法
dcj3sjt126com
cygwin
cygwin很多命令显示command not found的解决办法
修改cygwin.BAT文件如下
@echo off
D:
set CYGWIN=tty notitle glob
set PATH=%PATH%;d:\cygwin\bin;d:\cygwin\sbin;d:\cygwin\usr\bin;d:\cygwin\usr\sbin;d:\cygwin\us
- [介绍]从 Yii 1.1 升级
dcj3sjt126com
PHPyii2
2.0 版框架是完全重写的,在 1.1 和 2.0 两个版本之间存在相当多差异。因此从 1.1 版升级并不像小版本间的跨越那么简单,通过本指南你将会了解两个版本间主要的不同之处。
如果你之前没有用过 Yii 1.1,可以跳过本章,直接从"入门篇"开始读起。
请注意,Yii 2.0 引入了很多本章并没有涉及到的新功能。强烈建议你通读整部权威指南来了解所有新特性。这样有可能会发
- Linux SSH免登录配置总结
eksliang
ssh-keygenLinux SSH免登录认证Linux SSH互信
转载请出自出处:http://eksliang.iteye.com/blog/2187265 一、原理
我们使用ssh-keygen在ServerA上生成私钥跟公钥,将生成的公钥拷贝到远程机器ServerB上后,就可以使用ssh命令无需密码登录到另外一台机器ServerB上。
生成公钥与私钥有两种加密方式,第一种是
- 手势滑动销毁Activity
gundumw100
android
老是效仿ios,做android的真悲催!
有需求:需要手势滑动销毁一个Activity
怎么办尼?自己写?
不用~,网上先问一下百度。
结果:
http://blog.csdn.net/xiaanming/article/details/20934541
首先将你需要的Activity继承SwipeBackActivity,它会在你的布局根目录新增一层SwipeBackLay
- JavaScript变换表格边框颜色
ini
JavaScripthtmlWebhtml5css
效果查看:http://hovertree.com/texiao/js/2.htm代码如下,保存到HTML文件也可以查看效果:
<html>
<head>
<meta charset="utf-8">
<title>表格边框变换颜色代码-何问起</title>
</head>
<body&
- Kafka Rest : Confluent
kane_xie
kafkaRESTconfluent
最近拿到一个kafka rest的需求,但kafka暂时还没有提供rest api(应该是有在开发中,毕竟rest这么火),上网搜了一下,找到一个Confluent Platform,本文简单介绍一下安装。
这里插一句,给大家推荐一个九尾搜索,原名叫谷粉SOSO,不想fanqiang谷歌的可以用这个。以前在外企用谷歌用习惯了,出来之后用度娘搜技术问题,那匹配度简直感人。
环境声明:Ubu
- Calender不是单例
men4661273
单例Calender
在我们使用Calender的时候,使用过Calendar.getInstance()来获取一个日期类的对象,这种方式跟单例的获取方式一样,那么它到底是不是单例呢,如果是单例的话,一个对象修改内容之后,另外一个线程中的数据不久乱套了吗?从试验以及源码中可以得出,Calendar不是单例。
测试:
Calendar c1 =
- 线程内存和主内存之间联系
qifeifei
java thread
1, java多线程共享主内存中变量的时候,一共会经过几个阶段,
lock:将主内存中的变量锁定,为一个线程所独占。
unclock:将lock加的锁定解除,此时其它的线程可以有机会访问此变量。
read:将主内存中的变量值读到工作内存当中。
load:将read读取的值保存到工作内存中的变量副本中。
- schedule和scheduleAtFixedRate
tangqi609567707
javatimerschedule
原文地址:http://blog.csdn.net/weidan1121/article/details/527307
import java.util.Timer;import java.util.TimerTask;import java.util.Date;
/** * @author vincent */public class TimerTest {
- erlang 部署
wudixiaotie
erlang
1.如果在启动节点的时候报这个错 :
{"init terminating in do_boot",{'cannot load',elf_format,get_files}}
则需要在reltool.config中加入
{app, hipe, [{incl_cond, exclude}]},
2.当generate时,遇到:
ERROR