word2vec并行实现小记

word2vec能将文本中出现的词向量化,其原理建立在Mikolov的博士论文成果及其在谷歌的研究经验的基础上。与潜在语义分析(Latent Semantic Index, LSI)、潜在狄立克雷分配(Latent Dirichlet Allocation)的经典过程相比,word2vec利用了词的上下文,语义信息更加地丰富。word2vec并不是Mikolov某一天拍拍脑袋就给想出来的,也是站在牛人的肩膀上。大牛Bengio(NIPS 2001)借着深度学习的东风提出了一种可并行的神经网络模型;Morin(2005)为了加快神经网络语言模型(Neural Network Language Model,NNLM)的概率输出Softmax的计算,提出了Hierarchical Softmax;Mikolov同学慢慢地注意到神经网络在语言模型中的作用,早年的论文多在语音领域,其博士论文总结并优化了循环神经网络(Recurrent Neural Network),之后到了谷歌做研究,才总算提出了word2vec。这一段历史可进一步查看licstar的博客:词向量与语言模型。本文的重点在于描述word2vec是如何并行的,或者说是哪个部分并行的。相关实现代码在gitHub/siegfang/word2vec。
并行前的准备
并行训练前需要遍历一遍所有的训练的语料,统计词频,并依据词频构建一颗哈夫曼树(Huffman Tree)。一般来说,在海量语料的情况下,词频非常小的词一般不予以考虑。这里面大概有两个原因:
- 只出现一次或两次的词往往会非常之多,得到的词汇表非常庞大,后续所需的内存空间(包括哈夫曼树和词向量)也将非常庞大,训练时间也会相应地延长;
- 词频极低的词由于出现次数少,在神经网络训练中往往得不到充分地训练,其词向量可能会与邻近词相近,这会降低训练效果。
一个例子就是“奥巴马与主席夫人彭丽...”中的“彭丽”。由于新闻抓取错误或人名缺失等问题,会产生很多莫名其妙的低频词。深度学习等一切机器学习都不是万能的,去掉或替换这些噪声,能使得训练更好地进行。
并行ing
并行的关键在于如何分割好并行的任务和如何达成任务之间的良好通信?具体到word2vec来说,需要做的是将训练的语料分成若干份,依次交给并行的线程、进程或分布式机器等并行运行载体进行Skip-Gram或CBow-Gram模型训练,在各个独立的并行空间中,语料是不相同的,但训练的神经网络、词向量和哈夫曼是共享的,训练中使用的学习率等参数需要更新,在结束训练后需要计算。
Hierarchical Softmax
Hierarchical Softmax使用以词作为叶子的二叉树(这里即为哈夫曼树)来计算每个词出现的概率。每个词都可以由根结点经过某一路径到达,设L(w)是这条路径的长度,n(w,j)是这条路径上的第j个结点。显然n(w,1)即为根结点(root),n(w,L(w))是词所在的叶子结点。除了叶子结点,对于整棵树中包括根在内的其它结点,ch(n)表示结点n所分支的某一子结点。以输入词向量$w_I$预测输出向量$w_O$的概率计算公式为:
$$p\left( w_O | w_I \right) = \prod_{j = 1}^{L(w) - 1} \sigma \left( [n(w,j+1) = ch(n(w,j))] \centerdot v_{n(w,j)}^{\top} v_{w_I} \right)$$
其中[x]为指示函数,当x为真时,[x]的值为1,否则为-1;$\sigma(x)=1/(1+exp(-x))$。拿Skip-Gram模型来说,就是要以一个词的向量去预测其上下文的词的向量,而CBow-Gram则是先将上下文的词的向量和来预测中间词的向量,如下图所示:

word2vec中通过最小化交叉熵来对哈夫曼树节点向量和词向量进行更新。从根结点到词结点的路径可以看作是不断地从父结点选择一个子结点的过程,要使得路径正确就必须使得每次子结点的选择正确,也就是选择正确子结点的概率比错误的高。哈夫曼树从根结点开始的边要么以0标记,要么以1标记,这里使用交叉熵来使得每次选择都能尽可能地正确,正确选择的概率p(c)及交叉熵H如下
$$\begin{align*} p(c) &= \frac{\exp(v_{n(w,j)} \cdot v_{w_I} )}{1 + \exp(v_{n(w,j)} \cdot v_{w_I})} \\ H(v_{n(w,j)},v_{w_I}) &= - c\log p(c) - (1-c)\log (1-p(c)) \\ \end{align*}$$
其中c为正确选择的标记。最小化交叉熵可以通过梯度下降法迭代实现,偏导如下式所示:
$$\begin{align*} \underset{v_{n(w,j)},v_{w_I}}{\min} &H(v_{n(w,j)},v_{w_I}) \\ \frac{\partial H}{\partial v_{w_I}} &= (c - p(c))v_{n(w,j)} \\ \frac{\partial H}{\partial v_{n(w,j)}} &= (c - p(c))v_{w_I} \\ \end{align*}$$
Mikolov在其实现中使用1-c,这其实是一样的。之前我不是很明白为什么这么做?直到我用CBow-Gram做了一次主客观分类和褒贬分类时,我发现使用1-c会比使用c,准确率、召回率都会高1%,算是个小经验(trick)吧~
站在巨人的肩膀上
参考了其它语言和大牛的实现方法,包括:
- Tomas Mikolov的C实现 Google Code
- jdeng的C++实现 GitHub
- piskvorky的Python实现 GibHub
- ansj的Java实现(串行) GitHub
为啥不实现Negative Sampling
Negative Sampling在Mikolov自个儿的C代码中是有实现的,但ansj和piskvorky就没有,jdeng实现了但用宏(define)置代码无法执行。我挨个遍历了没有实现的大牛,问是不是因为词向量的质量在即使没Negative Sampling的情况下也足够好?
- jdeng issue#2:Right. The performance improvement was not observed but I am not sure if my implementation is accurate.
- piskvorky issue#156:See issue #130 : negative sampling is waiting for someone to implement it.
- ansj issue#4:一直没有回复
内存
我使用ansj的串行实现对比我的并行实现,分别做了在77M网络小说数据和1G新闻数据的对比。内存变化图如下:
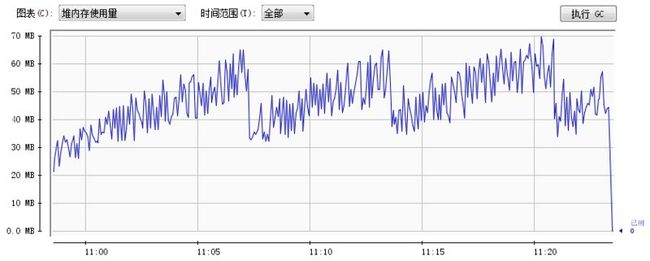
77M文本数据串行训练堆内存变化图

77M文本数据并行训练堆内存变化图
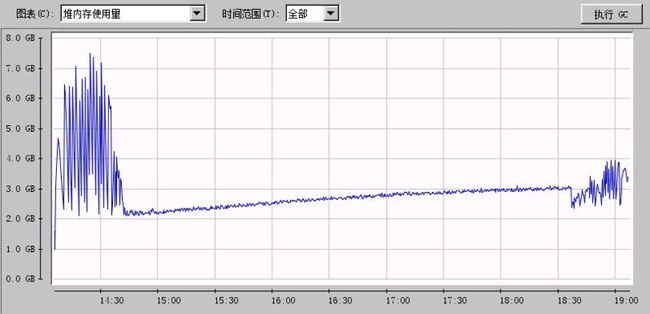
1G文本数据串行训练堆内存变化图

1G文本数据并行训练堆内存变化图
参考文献
- Bengio Y, Ducharme R, Vincent P, et al. A Neural Probabilistic Language Model[J]. Journal of Machine Learning Research, 2003, 3: 1137-1155.
- Morin F, Bengio Y. Hierarchical probabilistic neural network language model[C]//Proceedings of the international workshop on artificial intelligence and statistics. 2005: 246-252.
- Mikolov T. Statistical Language Models Based on Neural Networks}[D]. Ph. D. thesis, Brno University of Technology, 2012.
- Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[J]. arXiv preprint arXiv:1310.4546, 2013.
- Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[J]. arXiv preprint arXiv:1301.3781, 2013.
- word2vec演示:http://thisplusthat.me/