Deepseek API+Python测试用例一键生成与导出-V1
在实际使用场景中,可能只需要获取需求文档中的部分内容,例如特定标题的正文部分、特定段落的表格内容,或者指定图片中的内容。为了满足这一需求,可以对文档清理工具进行优化,支持按标题提取内容、按章节提取表格和图片,并结合阿里云百炼 DeepSeek-R1 的流式 API 进行对话生成测试用例等功能。而且上个版本的小工具貌似并没有很好的将目录清洗掉,这次也一并优化。
去除目录
此次更新从Word 文档(.docx 文件)中智能化地去除目录,可以使用 Python 的 python-docx 库。以下是一种方法,可以遍历文档中的所有段落,识别并删除目录。
代码示例
from docx import Document
def remove_toc(self, docx_path):
"""
去除 Word 文档中的目录
:param docx_path: docx 文件路径
"""
doc = Document(docx_path)
paragraphs_to_remove = []
# 遍历段落,识别目录
for paragraph in doc.paragraphs:
if "TOC" in paragraph.style.name: # 检查样式名称
paragraphs_to_remove.append(paragraph)
elif paragraph.text.strip() and (paragraph.text[0].isdigit() or paragraph.text.startswith("1.")):
# 检查是否为目录条目
paragraphs_to_remove.append(paragraph)
# 删除标记的段落
for paragraph in paragraphs_to_remove:
p = paragraph._element
p.getparent().remove(p)
# 保存修改后的文档
file_name = 'modified_' + docx_path.split('\\')[-1]
new_path = docx_path.split('\\')[0] + os.sep + file_name
doc.save(new_path)
return new_path
说明
-
识别目录:
- 通过检查段落的样式名称来识别目录。通常,目录的样式名称以 “TOC” 开头(如 “TOC 1”, “TOC 2” 等),可以根据具体文档样式进行调整。
-
删除段落:
- 使用
p.getparent().remove(p)方法来从文档中删除标记的段落。
- 使用
-
保存文档:
- 将修改后的文档保存为新的文件,避免覆盖原始文档。

注意事项
- 确保安装了
python-docx库,如果没有,可以使用以下命令安装:pip install python-docx - 根据具体文档的样式调整目录识别的逻辑。如果目录使用了不同的样式,可以修改条件以适应实际情况。
提取指定标题下的正文内容
下面给出实现按标题提取正文内容,并说明如何实现和微调以下功能:
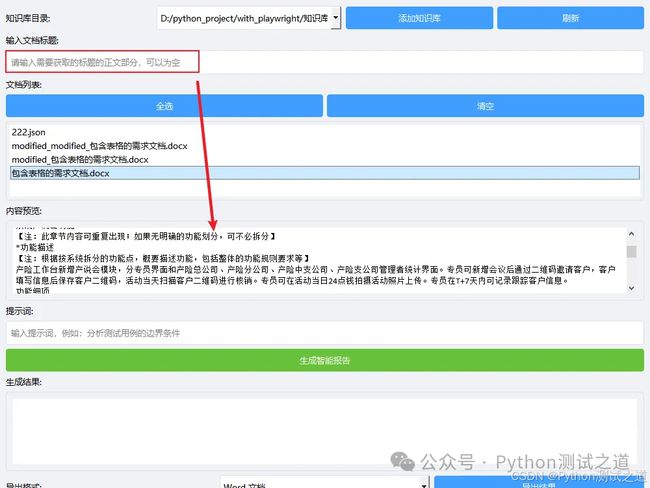
- 按标题提取正文内容:用户可以通过输入标题关键字(如“4.1 功能描述”),提取指定范围的正文。
- 按标题提取图片与表格:支持提取特定章节的图片和表格,并单独存储图片,用于后续处理。
- 图片内容识别:利用 OCR 技术识别图片中的文字,并结合阿里云百炼 DeepSeek-R1 的流式 API 进行对话生成测试用例。
- 灵活微调:通过修改正则表达式、章节匹配规则和 API 参数,满足用户的个性化需求。
功能实现方案
以下是针对需求文档部分内容提取的解决方案以及实现代码。
1. 提取指定标题的正文内容
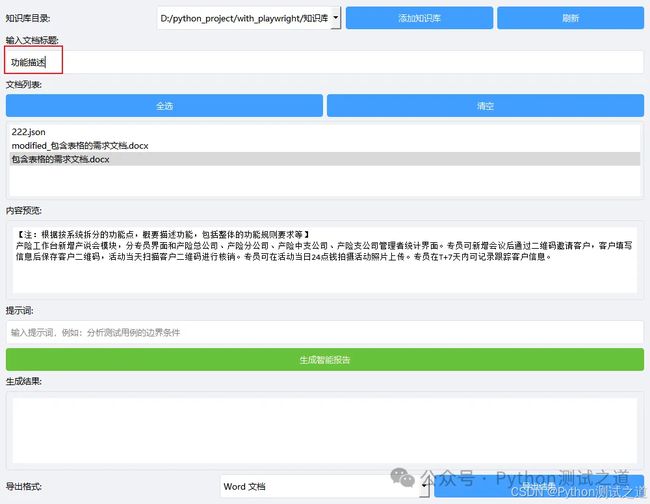
功能描述
通过用户输入的标题关键字(如“4.1 功能描述”),提取从该标题开始到下一个同级标题之间的正文。

注:如果不指定,则还是按原逻辑进行清洗展示。
实现代码
def extract_text_by_title(docx_path, title_keyword):
"""
根据标题关键字提取正文内容
:param docx_path: docx 文件路径
:param title_keyword: 标题关键字(如 "4.1 功能描述")
:return: 提取的正文内容
"""
doc = Document(docx_path)
content = []
capture = False # 标记是否开始捕获正文
for paragraph in doc.paragraphs:
text = paragraph.text.strip()
# print(f"当前段落文本: {text}")
# 匹配标题,判断是否开始捕获
if title_keyword in text and 'toc' not in paragraph.style.name:
capture = True
print("开始捕获正文内容")
# print(paragraph.style.name)
continue
# 如果捕获正文,遇到下一个标题则停止
if capture:
# print(paragraph.style.name)
if re.match(r"^\d+(\.\d+)*\s+.+", text): # 匹配新的标题
print("遇到新的标题,停止捕获")
break
elif "标题" in paragraph.style.name: # 遇到下一个标题则停止获取
print("遇到新的标题,停止捕获")
break
if text: # 只在文本非空时添加
content.append(text)
return "\n".join(content)
2. 提取指定标题的图片和表格(待实现)
功能描述
用户可以指定标题关键字(如“4.4.1.1 界面UI图”),提取从该标题开始的图片和表格,并分别存储到文件夹中。
3. 图片内容识别与智能对话生成测试用例(待实现)
功能描述
提取图片后,利用 OCR 技术识别图片中的文字并结合阿里云百炼 DeepSeek-R1 的流式 API 进行对话生成测试用例。
微调手法
1. 按标题提取正文内容
-
修改标题匹配规则:通过优化正则表达式,兼容不同的标题格式。例如:
# 支持 "4.1 功能描述" 和 "4.1 - 功能描述" re.match(rf"^{re.escape(title_keyword)}(\s+|[-])", text) -
限制正文范围:如果需要提取多级标题之间的内容,可以调整捕获规则。例如:
# 仅捕获 4.1 开头的内容 re.match(r"^4\.1(\.\d+)*\s+.+", text)
2. 提取表格和图片
- 图片格式兼容:支持提取 PNG、JPEG 等不同格式的图片,并统一保存为指定格式。
- 表格格式优化:将表格内容存储为二维数组(列表嵌套列表),并支持导出为 Excel 文件。
3. 图片内容识别与测试用例生成
-
OCR 语言支持:通过
pytesseract添加多语言支持。例如:pytesseract.image_to_string(image, lang="chi_sim") # 简体中文 -
增强对话生成逻辑:为流式 API 添加更多上下文信息,提升生成测试用例的准确性。例如:
payload = {"prompt": f"{prompt}\n上下文:{context}", "content": content}
总结
通过本文的优化,实现了针对需求文档的部分内容提取功能:
- 按标题提取正文:支持提取特定章节的正文内容。
- 按标题提取图片与表格:支持提取特定章节的图片和表格,并分别存储。
- 图片内容识别与测试用例生成:结合 OCR 和阿里云百炼 API,实现从图片到测试用例的智能生成。
这些功能可根据实际需求进行微调,满足不同场景下的需求文档清理和测试用例生成。源码已上传云盘,冰冻三尺非一日之寒,每日新增一点点!~欢迎反馈意见