SQL存储原理及聚集索引、非聚集索引、唯一索引、主键约束的关系(新)
一、堆(Heap)
之所以这个结构称为堆,是因为它不以任何人为指定的逻辑顺序进行排列。而是按照分区组队数据进行组织。也就是说,是按照磁盘的物理顺序。只要需要读取的数据文件没有文件系统碎片(注意和下面提到的索引的碎片区分),这个读取过程在磁盘中就可以连续的进行,没有多余的磁盘臂移动。而磁盘臂移动是I/O操作中开销最大的操作。
堆使用一个bitmap结构来管理数据的分配。也就是它会告诉你两个结果,这个区是分配了,还是没有分配。每一个区中的物理顺序如下图。
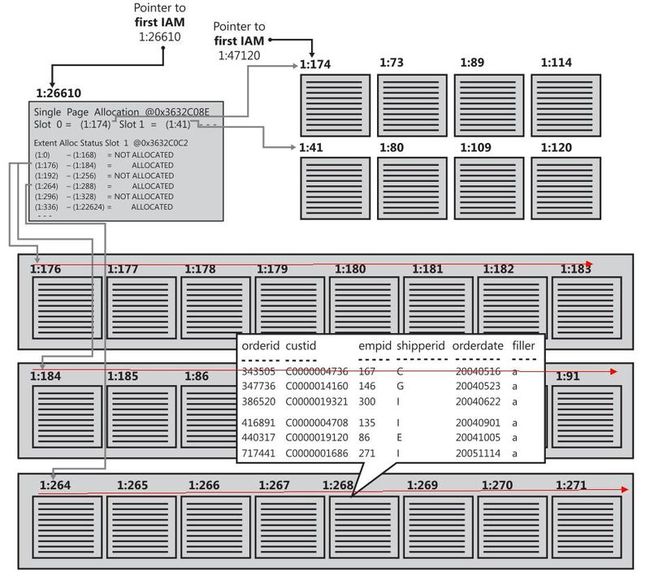
(此图倒数第二行的数字有错误,应该加1)
对于新插入的数据,堆只管在最后一条数据的后面的一个空闲位置保存新插入的数据,不保持任何的逻辑顺序。比如拿order表举例,如果先插入orderid 4,5,6, 假设在位置1:176、 1:177、1:178这三个位置。这时再插入1,这时保存的数据就变味4,5,6,1, 1保存在 1:179的位置。
PS:IAM链知识
Sytem_internals_allocation_units表存放第一个数据页和第一个IAM页的指针。IAM按照数据页的顺序存放数据页的指针。数据页之间并无直接链接。
接下来查看IAM的信息,如下:
Slot 0 = (1:79) Slot 1 = (1:89) Slot 2 = (1:90)
Slot 3 = (1:93) Slot 4 = (1:94) Slot 5 = (1:109)
Slot 6 = (1:110) Slot 7 = (1:114)
IAM: Extent Alloc Status Slot 1 @0x592EC0C2
(1:0) - (1:176) = NOT ALLOCATED
(1:184) - (1:192) = ALLOCATED
(1:200) - (1:376) = NOT ALLOCATED
加亮部分表明了IAM对应的分区信息,以及第一个数据页面指针指向79页。这与我们查询出的first_page值是一致的。一个IAM页面对应8个数据页,当超过8个数据页时,系统会从其对应的4GB空间(约512000个页面)中分配统一区的页面。当数据页超过可分配的页面数时,建立新的IAM页。
这里只有8个slot,8个临时存放数据页,当分配数据页超过8个混合分区后,系统会为数据表分配统一分区。(这里的每一个分配区间都是从区的第一个开始算的,比如说192那个指的是192-199)
每一个指针都指向一个数据页。当分配数据页超过8个混合分区后,系统会为数据表分配统一分区。这里,系统为数据表分配184~191, 192~199两个统一分区。每个分区包含8页,加上8个混合分区的页面,一共是25个页面。这25个页面中,使用了19个数据页,加上1个IAM页共使用了20个页面。因为统一分区是顺序分配的, 所以可以计算出从195~199的页面没有被使用。用DBCC可以验证这个推算。
下面我们把插入的数据删除,然后再查看IAM的页面分配情况,发现页面分配不会因为数据删除而改变,数据页内仅仅是将数据清空而已。
关于页头部需要注意:
- 正如我们所期望的——页类型为10 ,。
- 前页和后页指针都为NULL, 因为在IAM 链中没有其他的IAM 页。
- slot 数目为2 :一个是IAM 头记录;另一个是位图。
- 页几乎满了
IAM 页头有下面的字段:
- sequenceNumber
- 这是IAM 页在IAM 链中的位置值。每一个IAM 页加入到IAM 链时该值增加1 。
- status
- 未用
- objectId
- indexId
- 在SQL SERVER 2000 及以前版本,这是IAM 页所属的对象和索引的ID ;2005 和以后的版本这两个字段未用。
- page_count
- 字段未用——原来是用来跟踪单页分配数组中页数目。
- start_pg
- IAM 页映射了一个GAM 区间。这个字段存储了映射区间的首页ID.
- 单页分配数组( Single Page Allocations array )
- 这些是从混合分区中分配的页的数组。这个数组只存在IAM 链中的第一个页中(因为整个IAM 链中只需要跟踪8 个单独分配的页)。
位图占用IAM 页剩下的空间,每一位表示GAM 区间中的每一个区。如果区被分配给该实体,那么对应位就置1 ,否则为0 。很明显,为不同实体映射同一GAM 区域的两个IAM 页不可能有相同的位被置上——DBCC CHECKDB 会检查这个。在上面的DBCC PAGE 输出中,你可以看出没有区分配给表。你会发现输出最多到272 页所在的区—— 这是因为数据文件就这么大。
关于IAM 页还要注意两件事:
- IAM 页是从混合区中分配而来的,且这些页不受监控。
- 一个文件中分配的IAM 也可以用来跟踪另一个文件的区。
IAM 链
如果我们一直增大文件并往表中插入数据,最终我们将需要另一个IAM 页来映射下一个GAM 区间。这就是IAM 链的由来。IAM 链表用来跟踪单个实体上的空间分配。这个链表是不排序的——IAM 页按添加的顺序加入链表中,每个IAM 页有一个数值,同样是以添加顺序增加的。
“实体”的定义。到底是谁使用IAM 链?这个概念在SQL SERVER 2000 和2005 中区别很大。
在SQL Server2000 中,下面每个实体都有一个IAM 链表:
- 堆或聚集索引
- 一个表只能选其一,不能两者皆有。它们的索引ID 分别为0 和 1 。
- 非聚集索引
- 它的索引ID 从2 到250 (就是说只有249 个索引)。
- 表的完整LOB 存储
- 对于堆或者聚集索引中的LOB 列,有时也被称为“ 文本索引” ,它拥有一个固定的索引ID 值255 。
SQL SERVER 2000 及以前版本中每个兑现最多251 链表。我常总结为:在SQL SERVER 2000 中,每一个索引一个IAM 链(如果你还记得IAM 叫“ 索引分配映射” 的话,我觉得还是很贴切的)。
分配单元(SQL SERVER 2005 及以后版本)
现在在SQL SERVER 2005 及以后版本中,发生了一些变化。虽然IAM 链和IAM 页与以前是一模一样的,但是它们所对应的东西变了,而且现在一个表可以拥有750000 条IAM 链!现在IAM 链为三类东西映射分配空间:
1 .堆和B 树(B 树是系统用来存储索引的内部结构)
2 .LOB 数据
3 .行溢出数据
我们称这些分配空间的单元为分配单元(allocation units ),这三类分配单元的相应的内部名称为:
1 .HOBT 分配单元(发音和指环王中的霍比特人一样)
2 .LOB 分配单元
3 .SLOB 分配单元(SMALL –LOB)
对应的外部名称为:
1 .IN_ROW_DATA 分配单元
2 .LOB_DATA 分配单元
3 .ROW_OVERFLOW_DATA 分配单元
严格来说,它们不能再被称为IAM 链了,因为它们不再跟踪索引的分配空间了。只是它们还是IAM 页的链表,所以还被称为IAM 链,现在它跟踪的单元叫分配单元(allocation unit )。除了这些,和以前没有任何区别。关于IAM链的更多用途参考:http://blog.csdn.net/misterliwei/article/details/5943447
我们已经知道SQL Server IO最小的单位是页,连续的8个页是一个区。SQL Server需要一种方式来知道其所管辖的数据库中的空间使用情况,这就是GAM页和SGAM页。GAM(全局分配位图)是用于标识SQL Server空间使用的位图的页。位于数据库的第3个页,也就是页号是2的页。
我们看到页内的数据通过16进制表示。也就是一个数字是4比特,两个是一字节。其中前4个字节0000381f是系统信息,slot1的后10个字节也是系统信息。其余的每位表示SQL Server的一个区的状态,0表示已分配,1表示未分配。下面我们就通过图1所示的GAM页来计算一下这个数据库所占的空间。
我们可以看到,由于数据库刚刚创建,分配的空间在第4-8个字节就能表示,也就是0001c0ff。下面将0001c0ff由16进制化为2进制。结果是
0000 0000 0000 0001 1100 0000 1111 1111
通过计算,可以看出,上面的bit中有21个0,也就是目前数据库已经分配了21个区,我们知道每个区是8*8k=64K。因此算出这个数据库占用空间(21*64)/1024=1.3125MB≈1.31MB。
那可能大家会有疑问了,那如果数据库增长超过一个GAM所能表示的区的范围那该怎么办?答案很简单,就是再创建一个GAM页,第二个GAM页的位置也可以通过图1中的信息进行计算。图1中slot1有7992个字节,其中前四个字节用于存储系统信息,后面7988字节用于表示区的情况,因此所能表示的区是7988*8=63904,横跨的页的范围是511232,所以第511232+1页应该是下一个GAM页,而页号就会是511232页。这个区间也就是所谓的GAM Interval,接近4GB。
Shared Global Allocation Map Page
通过GAM页可知,分配空间的最小单位是区。但假如一个非常小的索引或是表只占1KB,但要分给其64K的空间就显得过于奢侈了。所以当几个表或索引都很小时,可以让几个表或索引公用一个区,这类区就是混合区。而只能让一个表或索引使用的区就是统一区。SGAM位于数据库的第四页,也就是GAM的下一个页。页号为3。通过和GAM相同位置的bit组合,就能知道空间的状态。所能表示的几种状态如表1所示。
| GAM | SGAM位 | |
| 未分配 | 1 | 0 |
| 统一区或空间使用完的混合区 | 0 | 0 |
| 含有可分配空间的混合区 | 0 | 1 |
表1.SGAM和GAM
通过SGAM和GAM的组合,SQL Server就能知道该从哪里分配空间。
第二个SGAM页位于第二个GAM页之后,也就是页号为511233的页。依此类推。
二、回归正题: 聚集索引(Clustered Index)
聚集索引以B树的方式保存数据。由于在另一篇文章中已经详细的分析了B树,这里就不再详细说明。
(PS:B-树
是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
如:(M=3)
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
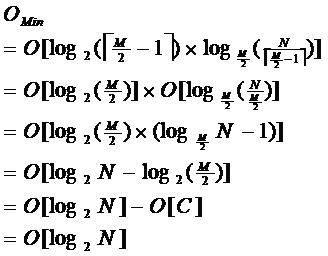
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率,其最底搜索性能为:
其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并
B+树
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)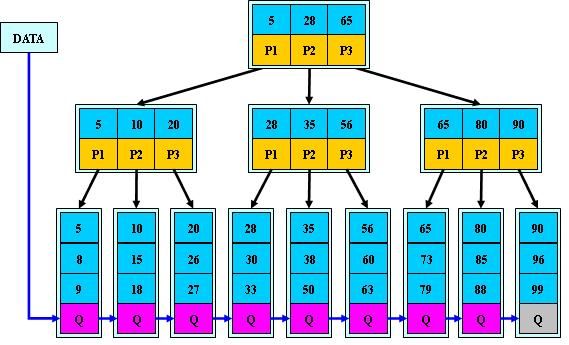
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
小结
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
)
继续拿Order表举例,Order表中的全部数据都保存在B树中的叶层(leaf level)中,其他层只是起到一个索引的作用,并不包含任何数据。叶层是一个双向链表结构,并按照聚集索引的主键的逻辑顺序排列。因此逻辑顺序是用指针来维护。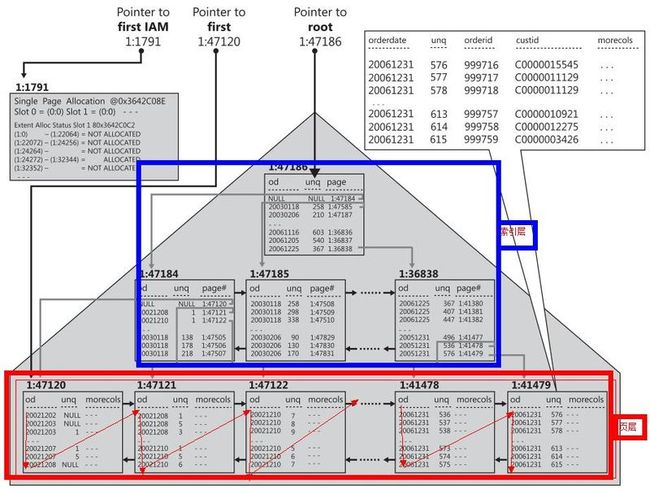
我们在图中页层所见到是逻辑顺序,和上图堆中所展示的物理顺序要区分开来。
为什么我一再强调逻辑顺序和物理顺序?因为理解这很重要。
如图所示,聚集索引中除了B树之外,仍然维护了一个IAM结构,而这个结构就能保证在需要的时候,我们能按照物理顺序而不是逻辑顺序去在叶层中读取数据。
那么什么时候才需要呢?先看什么是索引碎片。(除了IAM之外,还有一个指向逻辑上第一块数据的指针,IAM保存物理顺序,页层保存逻辑顺序,若通过物理顺序访问,速度最快,可使用IAM,若使用逻辑顺序带排序,则使用指向头的指针。)
2.1 索引碎片
数据库中之所以会出现碎片,是因为B树的页拆分造成的。具体页拆分请参考数据结构,这里要说的是由于拆分所产生的新页不保证一定就会在被拆分的页的后面,而是可能出于文件的任何位置。这就是“无序页”。换句话说,也就是在列表中处于后面位置的元素,在物理文件中却排在前面。如果你明白指针的定义的话,这句话并不难理解。因为叶层的双向列表就是以指针来维护逻辑顺序。
因此在按逻辑顺序读取的时候,由于无序页的存在,可能造成磁臂频繁的摆动。别忘记,磁盘摆动是I/O中开销最大的操作。而I/O往往是一个系统的瓶颈所在。
如果按照物理顺序来读取,也就是unordered读取,就会避免上面所产生的问题。再次强调,unordered是指不按逻辑顺序读取,所以叫unordered。
(PS:页拆分http://www.cnblogs.com/TeyGao/p/3649982.html
很多同行会问起页拆分的相关的问题,自己对页拆分页迷迷糊糊,有点云里雾里的感觉,今天来测试测试。
首先生成测试数据
--========================================= --使用TestDB数据库来测试 USE TestDB GO DROP TABLE TB01 GO --======================================= --创建测试表TB01 CREATE TABLE TB01 ( ID INT PRIMARY KEY, C1 NVARCHAR(MAX) ) GO --======================================= --插入420条数据,所有数据存放在一个8KB的数据页中 INSERT INTO TB01(ID,C1) SELECT T.RID,N'C' FROM ( SELECT ROW_NUMBER()OVER(ORDER BY object_id) AS RID FROM sys.all_columns ) AS T WHERE T.RID<422 AND T.RID<>418 --====================================
现在表TB01上有一个数据页(接近填满),使用DBCC查看

然后尝试插入数据导致页拆分:
--====================================
--插入一行数据
INSERT INTO TB01(ID,C1)
SELECT 418,REPLICATE(N'1',4000)
--====================================
--查看数据页
DBCC IND('TestDB','TB01',1)
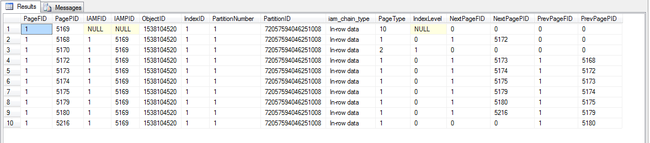
我们可以很清楚地发现,在插入一行数据后,数据页由原来的一页变成了9页(一个非叶子节点页和8个叶子节点页),是不是很不科学呢? 新插入的数据只需要一个数据页来存放,加上原来的数据,只需要2个数据库便可以存放,为什么会造成这么多页面使用呢?
通过上面的图,可以清楚看到数据有两层,非叶子节点(也是根节点)页是5170,使用该页来查看数据分布情况:
--===================================
--查看非叶子节点来查看数据和页的对应情况
DBCC PAGE('TestDB',1,5170,3)

观察上图的ID,我们可以发现以下规律
211=1+420/2
316=211+420/2/2
368=316+420/2/2/2
394=368+420/2/2/2/2
407=394+420/2/2/2/2/2

从上面的数据不难看出,每页数据逐渐一半一半地减少。再通过sys.fn_dblog(NULL,NULL)来查看事务,最后一次插入操作引发1次插入事务和8个页拆分事务。
由此,我们推断出在上面的插入过程中,发生了以下操作:
1. 新事务开始,一行新数据需要插入到数据页中,该数据行不是数据页最尾数据行
2. 判断页中剩余空间,发现数据页不能存放新插入行,需要页拆分
3. 开启一个新事务,将页中一半数据移动到一个新的页面,关闭事务
4. 循环第2步和第3步,直到有一数据页能存放新插入的行
5. 插入数据,提交事务
到此,很多人就会疑问,拆分一半到底是数据行数的一半还是数据占用空间大小的一半呢?
让我们再做一个实验
--========================================== --清除表中数据 TRUNCATE TABLE TB01 --======================================= --插入198条数据,所有数据存放在一个8KB的数据页中 --前99条数据和后99天数据的大小不相同 INSERT INTO TB01(ID,C1) SELECT T.RID,N'C' FROM ( SELECT ROW_NUMBER()OVER(ORDER BY object_id) AS RID FROM sys.all_columns ) AS T WHERE T.RID<100 INSERT INTO TB01(ID,C1) SELECT T.RID,N'CCCCCCCCCCCC' FROM ( SELECT ROW_NUMBER()OVER(ORDER BY object_id) AS RID FROM sys.all_columns ) AS T WHERE T.RID>100 AND T.RID<200 --==================================== --插入一行数据导致页拆分 INSERT INTO TB01(ID,C1) SELECT 100,REPLICATE(N'1',2000)
同样适用根节点来数据分布:

由于后99行数据占用的空间大小较大,在页拆分时,没有将后99条全部拆分到新的数据页上,因此我们得出结论,页拆分时是按照数据占用空间大小来拆分的,与数据行数无关。
--=====================================================================================================
总结:
1.发现在页拆分时,会按照页中数据占用空间的情况,将占用空间一半的数据移动到新的数据页上
2.如果拆分后仍无法存放新数据,则继续页拆分,知道有数据页可以存放新数据为止,因此一次插入操作可能会引起多次页拆分。
3.每次页拆分会被当成一个事务处理,页拆分的事务单独提交(在提交插入事务之前已提交),及时插入失败,页拆分的事务也不会回滚。
4.更新导致的页拆分情况与插入导致的页拆分类似
PS:
1. 在测试中,未发现没有按照一半空间拆分的情况,但没有找到相关官方文档来证明。
总之就是为了让逻辑顺序和聚集索引键顺序一致,有时候需要在非连续区域放置某一条记录,为了让这条记录满足顺序,必须把原连续记录拆分出来,改变新纪录所在页的前后指针来满足顺序。
)
2.2 索引的层数
索引的层数,也就是B树的高度,直接表明了一次查找操作在页面读取方面的开销。一些执行计划如Nested loop联接会多次调用查找操作。因此理解这个概念很重要。
树的高度主要和以下几个因素相关
- 表的总行数。
- 平均一行保存数据的大小。
- 页的平均密度。因为不是每一页都应该填充满数据,这样可以减少页拆分的次数。
- 一页所能容纳的行数。
具体公式也很简单,3级索引大概能容纳4百万行,4级索引大概能容纳4亿行数据。因此通常一张表的索引层数通常为3到4级。
3、非聚集索引(NonClustered Index)
非聚集索引也是以B树组织的。和聚集索引的区别就在于它的叶层并不包含所有的数据。在默认情况下它只包含了键列的数据,并包含了一个行定位符(row locator)。这个行定位符的具体内容取决于它建立在以堆形式的表还是以B树组织的表,换句话说也就是这张表是否建立了聚集索引会影响到非聚集索引的行定位符。如果是建立了聚集索引,那么这个行定位符就是一个聚集键,我们通过这个聚集键再次查找聚集索引上的数据。
聚集索引上的非聚集索引

如果表是堆组织结构的,那么它就是一个直接指向数据所在行的物理指针。
下图是建立在堆上的非聚集索引

3.1 如果非聚集索引包含了我们需要查找的所有数据
这种情况我们通常叫做索引覆盖。
正因为非聚集索引有着和索引一样的结构,并且由于非聚集索引所包含的列少,因此数据量就小,使得叶层的一页能包含更多的行,因此进行一次I/O页读取的动作的时候,就能读取进更多的行。因此查找效率是最高的。
举个不恰当的例子,美女征婚,应征人员的个人信息表有 “姓名、 德、 智、 体 、美、 劳、 高、 富、 帅”这几列,按姓名排序。美女只关注“高、 富、 帅”这三列的内容,为了更快的筛选,我们帮美女按照个人信息表的内容重新制作了一张表,这张表忽略了其他信息,只保留了高、富、帅和姓名,筛选效率当然就比原来关注更多内容时要高。
3.2 如果非聚集索引不包含我们需要查找的所有数据
通俗的说这时我们就需要从非聚集索引中所包含的线索去包含所有数据的表中去找。
按照我们之前的定义换句话来说,就是通过非聚集索引中的行定位符去聚集索引或者堆中去查找所需的数据。
二、通过实例来说明上述概念
我们创建一张Order表,表上建立了几个索引
1.为orderdate列创建了聚集索引
2.为orderid列创建了非聚集索引
1.1.1 只为获取整张表的数据,对数据顺序不关心
SELECT [orderid]
,[custid]
,[empid]
,[shipperid]
,[orderdate]
,[filler]
FROM [Performance].[dbo].[Orders]
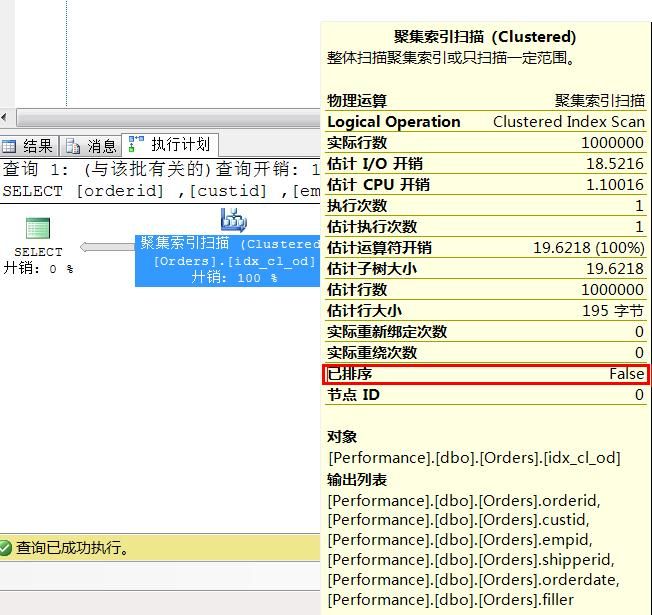
分析:由于我们需要获取整张表的数据,因此不需要任何筛选也不需要任何排序。因此我们按照磁盘物理顺序读取出所有数据无疑是最快的选择。 所以已排序为False. 再次说明这里的已排序的顺序是聚集键的逻辑顺序,和物理顺序不同。
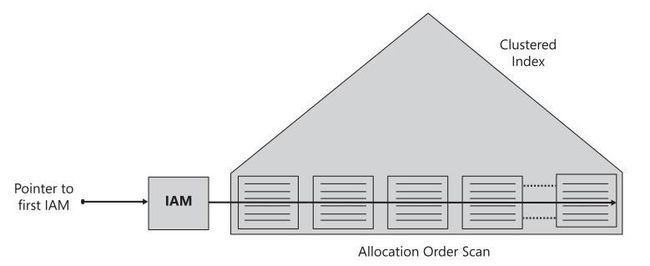
通过IAM在聚集索引的叶层扫描。在这种情况下无论表是以堆或者B树的形式组织情况都类似。
不管是堆还是B树,都是用IAM来保存的,IAM里分区,区里有页,页里可以放数据,也可以放索引,在扫描时只用检查其类型,排除非数据即可按物理顺序读取,速度较快。
(1000000 行受影响)
表'Orders'。扫描计数1,逻辑读取25081 次,物理读取5 次,预读23545 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
1.1.2 按聚集键顺序获取整张表的数据
对于Orders表,以orderdate为聚集键,因此如果我们使用顺序查询,就可以直接获取所需要的数据。

这是我们就不再通过IAM来对叶层进行扫描,而是通过叶节点的指针来进行扫描。

1.1.3 如果不按照聚集键,而是按照其他列的顺序来获取整张表
我们并没有把orderid设置成聚集索引的键,而是把它设成了非聚集索引的键。因此在返回整张表的内容时:
1.非聚集索引键列orderid对我们没有意义,因为我们期望返回的是整张表的内容,而非聚集索引只包含键列的内容。
2.聚集键列orderdate的顺序在这里对我们是没有什么用的。
由上面的推论可以知道,这时我们所创建的索引对我们都没有任何帮助。因此,与其按照逻辑顺序返回,不如按照最快速的无序返回,再把返回的结果集排序。而计划证明了我们的猜想。

1.1.4 如果我们要查询的内容,正好在非聚集索引里面就已经包含了
和上面查询基本类似,区别在于我们在查询结果中把非聚集索引中不包含的列全部删除了,这时非聚集索引就形成了覆盖。我们就可以利用非聚集索引进行查询。

一些索引建议:
1.对于长字符串,比如VARCHAR(80)这种类型的索引要比更为紧凑数据类型的索引大很多。同样地,你也不太可能对长字符串列进行全匹配查找。
http://www.cnblogs.com/lwzz/archive/2012/08/05/2620824.html
补充:在基于聚集索引的非聚集索引上,叶子节点存放的是聚集索引的键,所以在找到之后还要通过聚集索引键来查找,之所以不能用物理地址是因为,聚集索引的数据物理地址是不固定的,可能被页拆分而改变地址,所以用键来保存是比较稳妥的做法。(至于修改聚集索引键做的操作就需要再查查了)