Javascript多线程引擎(九)
Javascript多线程引擎(九)--垃圾回收
垃圾回收这个话题对Programer来说是非常老旧的话题, 从手动的malloc/free 到半自动的 引用计数 再到全自动的 mark-sweep 算法 最后进化到 分代回收, 可以发现程序员越来越懒了^_^.
从繁琐的内存管理解放出来 对业务逻辑开发为主的程序员来说是非常有必要的事情, So Java 等高级语言变成了现今的主流语言(当然也和它的跨平台和异常强大的类库相关).
作为Javascript引擎, 当然也不能少了垃圾回收的功能, Google V8 , TraceMonkey 等都带有一个非常牛掰的垃圾回收机制外加JIT功能, 使得它们摇身一边就成了服务器引擎.
而这个项目的垃圾回收在前期决定不添加该功能, 到后期发现少了垃圾回收对内存的消耗太过于厉害(原先估算1MB的内存能干很久了, 结果发现短短几分钟就被吃掉了), 所以在写前一篇文章的时候, 进入了深入的思考, 如何把垃圾回收添加到该引擎上.
开发过程中遇到的问题有很多(主要的问题是关系图完整性的确定):
1. 如何最小化的侵入原有代码中(使用mark-sweep)
2. 如何同步 EVAl线程和 Async线程(EVAL 线程为运行Js代码的线程, Async线程相当于AJAX的线程, 这个线程的内存控制不受VM管理, 在结束Async线程的时候需要把必要的数据同步到VM 的GC管理器中),
3. 如何选择一个时机来进行垃圾回收, 对于多线程同时进行申请内存如何进行快速的分配而不因为加锁而导致效率下降(记录新的内存申请需要把该内存申请记录到GC中)
4. 如何快速的插入新申请内存的记录到GC管理中(以内存地址为hashcode插入到Hashtable中实现了O(1)的时间),....
为了解决这些问题, 翻阅了lua代码,jamvm(Java 的解释器版本不带有JIT等该机特性). 归纳了如下的解决方案:
1. 每条线程都附带一个HashTable进行管理该线程进行GC Malloc的内存记录, 在线程结束的时候, 把TLS中关于GC的内存记录 Commit 到主存
2. 垃圾回收的地点发生在主存, 对于TLS中的申请记录即使没有被Mark到也不进行回收(这是为了线程运行中的那些临时数据), 这也保证了Async线程Malloc的内存不会被回收.
3. 只有当VM所有Engine都处于IDLE状态的时候才进行垃圾回收, 这保证了EVAL中的临时数据不会被破坏.
4. 为了保证关系图的完整性 , 如一次链表的插入, A->B 的关系中, 需要变成 A->C->B的关系, 期间有可能临时变化为 A C->B 这种引用关系, 而如果期间再发生GC的话, 就发生灾难性后果, B以及链接在B的子对象被回收, 所以选择了在线程结束(这个时候不可能有不完整的关系图 )或者一次手动Commit()内存到主存的API给程序员控制(调用该API需要确保关系图的完整性).
如下是GC的测试结果:
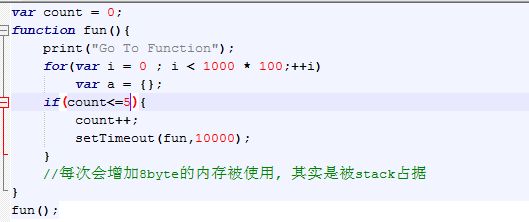
每次运行fun函数, 会申请 1000* 100 = 10W 个对象
然后由调用setTimeout() 等待10s的时间, 来使得Engine都处于IDLE状态, GC线程进行工作.
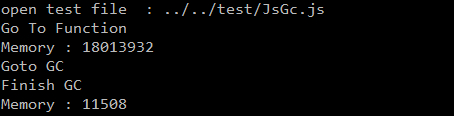
(以上单位是字节)
运行完毕后, 10w个对象相当于使用了 17MB的内存, GC 过后, 只有11KB的内存被占用这, 这部分内存其中有10KB左右被预置对象[Global, Thread, Object, Function ... ]和VM必要数据占用, 而剩余的1KB则是运行文件后, 产生fun函数对象记录到Global中就不会被释放掉了。
所以垃圾回收模块可以算是完成了, 性能也不错, 开启虚拟机 到申请10w个对象,完成17MB内存的回收只用了 5秒左右, GC的时间差不多为0.5s 左右, 不过这个性能和JVM相比还是不好的, JVM可以在Engine不打断执行的情况下完成垃圾回收, 具体的做法就是把完整性确定的时间进行细分, 使得可以在运行Java代码的时候回收内存.
现在这个项目可以算是比较完整了^_^ , 就是缺少了一些应用比如说 web服务等, 这些等下一个版本再做。
接下来就是万恶的毕业季了, 找工作Style。。。。
项目地址:
github.com/darkgem/js-engine
谢谢大家的支持~