如何判断一个Http Message的结束——python源码解读
HTTP/1.1 默认的连接方式是长连接,不能通过简单的TCP连接关闭判断HttpMessage的结束。
以下是几种判断HttpMessage结束的方式:
1. HTTP协议约定status code 为1xx,204,304的应答消息不能包含消息体(Message Body), 直接忽略掉消息实体内容。
[适用于应答消息]
Http Message =Http Header
2. 如果请求消息的Method为HEAD,则直接忽略其消息体。[适用于请求消息]
Http Message =Http Header
3. 如果Http消息头部有“Transfer-Encoding:chunked”,则通过chunk size判断长度。
4. 如果Http消息头部有Content-Length且没有Transfer-Encoding(如果同时有Content-Length和Transfer-Encoding,则忽略Content-Length),
则通过Content-Length判断消息体长度。
5. 如果采用短连接(Http Message头部Connection:close),则直接可以通过服务器关闭连接来确定消息的传输长度。
[适用于应答消息,Http请求消息不能以这种方式确定长度]
6. 还可以通过接收消息超时判断,但是不可靠。Python Proxy实现的http代理服务器用到了超时机制,源码地址见References[7],仅100多行。
HTTP协议规范RFC 2616的4.4 Message Length中对相关内容有较多的描述(https://tools.ietf.org/html/rfc2616#section-4.4)。

一个实例,Python标准库httplib.py源码解读(http协议客户端的实现)
httplib最简单的使用方法:
import httplib
conn = httplib.HTTPConnection("google.com")
conn.request('GET', '/')
print conn.getresponse().read()
conn.close()
但是一般不直接使用httplib,而是使用更高层的封装urllib,urllib2
conn = httplib.HTTPConnection("google.com")创建HTTPConnection对象,指定要请求的webserver.
conn.request('GET', '/')向google.com发送http请求,Method为GET
conn.getresponse()创建HTTPResponse对象,接收并读取http应答消息头,read()读取应答消息体。
函数调用关系:
getresponse()->[创建HTTPResponse对象response]-> response.begin()->response.read()
重点是begin()和read(),begin()完成了4件事:
(1)创建HTTPMessage对象并解析Http应答消息的头部。
(2)查看头部是否有“Transfer-Encoding:chunked”。
(3)查看接收完应答消息后是否关闭TCP连接(调用_check_close())。
(4)如果头部有“Content-Length”并且没有“Transfer-Encoding:chunked”,则获取消息体长度。
_check_close()判断若Http应答消息头部有“Connection:close”则接收完应答消息后关闭TCP连接,同时还有一些向后兼容HTTP/1.0的代码。HTTP/1.1默认是“Connection:Keep-Alive”,即使头部中没有。
read()根据Content-Length或chunked分块方式读取Http应答消息体,可一次全部读取也可以指定要读取的字节数。如果是chunked方式,调用_read_chunked()读取。
_read_chunked()根据chunksize读取chunks,当读取完最后一个chunk(最后一个chunk的chunksize = 0)后就完成了Http应答消息的接收。相关的HTTP协议规范参考RFC2616 3.6.1,RFC2616 19.4.6
RFC 2616 19.4.6 有一段如何解析 chunked 方式的 Http 消息的伪代码:
length:= 0
readchunk-size, chunk-extension (if any) and CRLF
while(chunk-size > 0) {
read chunk-data and CRLF
append chunk-data to entity-body
length := length + chunk-size
read chunk-size and CRLF
}
readentity-header
while(entity-header not empty) {
append entity-header to existing headerfields
read entity-header
}
Content-Length:= length
Remove"chunked" from Transfer-Encoding
来看一下begin(),_check_close(),read(),_read_chunked()的主要代码:
(1) begin():
def begin(self):
......
self.msg = HTTPMessage(self.fp, 0)
# don't let the msg keep an fp
self.msg.fp = None
# are we using the chunked-style of transfer encoding?
tr_enc = self.msg.getheader('transfer-encoding')
if tr_enc and tr_enc.lower() == "chunked":
self.chunked = 1
self.chunk_left = None
else:
self.chunked = 0
# will the connection close at the end of the response?
self.will_close = self._check_close()
# do we have a Content-Length?
# NOTE: RFC 2616, S4.4, #3 says we ignore this if tr_enc is "chunked"
length = self.msg.getheader('content-length')
if length and not self.chunked:
try:
self.length = int(length)
except ValueError:
self.length = None
else:
if self.length < 0: # ignore nonsensical negative lengths
self.length = None
else:
self.length = None
# does the body have a fixed length? (of zero)
# NO_CONTENT = 204, NOT_MODIFIED = 304
#判断Http Response Message 结束,见本文开头总结的第1点
if (status == NO_CONTENT or status == NOT_MODIFIED or
100 <= status < 200 or # 1xx codes
self._method == 'HEAD'):
self.length = 0
# if the connection remains open, and we aren't using chunked, and
# a content-length was not provided, then assume that the connection
# WILL close.
#判断Http Response Message 结束,如果没有chunked和Content-Length都没有使用,就关闭连接
if not self.will_close and \
not self.chunked and \
self.length is None:
self.will_close = 1
(2)_check_close():
def _check_close(self):
#判断Http Response Message 结束,见本文开头总结的第5点
conn = self.msg.getheader('connection')
if self.version == 11:
# An HTTP/1.1 proxy is assumed to stay open unless
# explicitly closed.
conn = self.msg.getheader('connection')
if conn and "close" in conn.lower():
return True
return False
# Some HTTP/1.0 implementations have support for persistent
# connections, using rules different than HTTP/1.1.
# For older HTTP, Keep-Alive indicates persistent connection.
if self.msg.getheader('keep-alive'):
return False
# At least Akamai returns a "Connection: Keep-Alive" header,
# which was supposed to be sent by the client.
if conn and "keep-alive" in conn.lower():
return False
# Proxy-Connection is a netscape hack.
pconn = self.msg.getheader('proxy-connection')
if pconn and "keep-alive" in pconn.lower():
return False
# otherwise, assume it will close
return True
(3) read():
def read(self, amt=None):
if self.fp is None:
return ''
if self._method == 'HEAD':
self.close()
return ''
if self.chunked:
return self._read_chunked(amt)
if amt is None:
# unbounded read
if self.length is None:
s = self.fp.read()
else:
try:
s = self._safe_read(self.length)
except IncompleteRead:
self.close()
raise
self.length = 0
self.close() # we read everything
return s
if self.length is not None:
if amt > self.length:
# clip the read to the "end of response"
amt = self.length
# we do not use _safe_read() here because this may be a .will_close
# connection, and the user is reading more bytes than will be provided
# (for example, reading in 1k chunks)
s = self.fp.read(amt)
if not s:
# Ideally, we would raise IncompleteRead if the content-length
# wasn't satisfied, but it might break compatibility.
self.close()
if self.length is not None:
#计算剩余长度,供下次读取
self.length -= len(s)
if not self.length:
self.close()
return s
(4) _read_chunked():
def _read_chunked(self, amt):
assert self.chunked != _UNKNOWN
# self.chunk_left is None when reading chunk for the first time(see self.begin())
#chunk_left :bytes left in certain chunk
#chunk_left = None means that reading hasn't been started.
chunk_left = self.chunk_left
value = []
while True:
if chunk_left is None:
# read a new chunk
line = self.fp.readline(_MAXLINE + 1)
if len(line) > _MAXLINE:
raise LineTooLong("chunk size")
i = line.find(';')
if i >= 0:
line = line[:i] # strip chunk-extensions
try:
chunk_left = int(line, 16)
except ValueError:
# close the connection as protocol synchronisation is
# probably lost
self.close()
raise IncompleteRead(''.join(value))
if chunk_left == 0:
##RFC 2661 3.6.1 last-chunk chunk_left = 0
break
if amt is None:
value.append(self._safe_read(chunk_left))
elif amt < chunk_left:
value.append(self._safe_read(amt))
self.chunk_left = chunk_left - amt
return ''.join(value)
elif amt == chunk_left:
value.append(self._safe_read(amt))
self._safe_read(2) # toss the CRLF at the end of the chunk
self.chunk_left = None
return ''.join(value)
else:
value.append(self._safe_read(chunk_left))
amt -= chunk_left
# we read the whole chunk, get another
self._safe_read(2) # toss the CRLF at the end of the chunk
chunk_left = None
......
# we read everything; close the "file"
self.close()
return ''.join(value)
另一个实际的源码,PythonProxy中,到达超时时间后停止接收消息。_read_write()读取和写入已打开的socket。
def _read_write(self):
time_out_max = self.timeout/3
socs = [self.client, self.target]
count = 0
while 1:
count += 1
# time_out = 3
(recv, _, error) = select.select(socs, [], socs, 3)
if error:
break
if recv:
for in_ in recv:
data = in_.recv(BUFLEN)
if in_ is self.client:
out = self.target
else:
out = self.client
if data:
out.send(data)
count = 0
#连续time_out_max次未接收到数据就停止接收和发送[超时了]
if count == time_out_max:
break
有了上面的分析和源码,这个问题应该很好回答了:
当HTTP采用keepalive模式,当服务器响应客户端的请求后,客户端如何判断接收到的Http ResponseMessage已经接收完成?
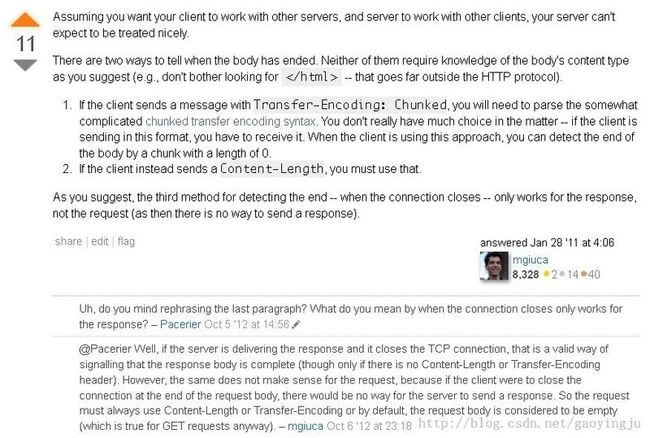
最后,再附上stackoverflow上一个关于如何判断Http Message结束的回答:
References
[1]Hypertext Transfer Protocol -- HTTP/1.1
https://tools.ietf.org/html/rfc2616
[2]Detect end of HTTP request body
http://stackoverflow.com/questions/4824451/detect-end-of-http-request-body
[3]Detect the end of a HTTP packet
http://stackoverflow.com/questions/3718158/detect-the-end-of-a-http-packet
[4] 判断Keep-Alive模式的HTTP请求的结束
http://blog.quanhz.com/archives/141
[5] 这样被判了死刑!
http://www.cnblogs.com/skynet/archive/2010/12/11/1903347.html
[6]杂谈Nginx与HTTP协议
http://blog.xiuwz.com/tag/content-length/
[7]Python Proxy- A Fast HTTP proxy
https://code.google.com/p/python-proxy/
[8] python基于http协议编程:httplib,urllib和urllib2
http://www.cnblogs.com/chenzehe/archive/2010/08/30/1812995.html