GUID和INT自增做主键的测试
测试机器:dell2850,2cpu,2G内存,数据库为简单模式,避免日志记录影响(不过似乎一般的应用场景都是完整模式)
Int自增表
 Code
GUID表
Code
GUID表
Code
顺序GUID表
Code
测试插入的脚本:
Code
Int表插入1w条记录是61626微妙,61560微妙,两次测试结果相差不大。
GUID表插入1w条记录是63156微妙,62436微妙。
基于上两次测试没有测试OGUID表了。
每次测试均truncate了表。
再测试10w条记录的插入情况:
10w
int 620330 618093
GUID
686923 667780
OGUID
635436 642013
从数据能看出int是最快的,其次是顺序化的GUID插入,再次是无序GUID。
再测试一下全表扫描的IO:
set statistics time on
set statistics io on
checkpoint;
dbcc dropcleanbuffers;
select * from [int];
select * from [guid];
select * from [oguid];
统计情况如下:
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 2 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 66 毫秒。
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 12 毫秒。
(100000 行受影响)
表 'Int'。扫描计数 1,逻辑读取 411 次,物理读取 1 次,预读 450 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 78 毫秒,占用时间 = 2095 毫秒。
(100000 行受影响)
表 'GUID'。扫描计数 1,逻辑读取 823 次,物理读取 2 次,预读 862 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 94 毫秒,占用时间 = 2487 毫秒。
(100000 行受影响)
表 'OGUID'。扫描计数 1,逻辑读取 564 次,物理读取 1 次,预读 552 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 63 毫秒,占用时间 = 1511 毫秒。
从IO上看,GUID表是int的一倍,OGUID是int的120%。
再看聚集索引查找:
set statistics time on
set statistics io on
checkpoint;
dbcc dropcleanbuffers;
select * from [int] where intID = 99999;
select * from [guid] where guidid = 'F0EE26A1-9F55-4D7B-B580-7F7164ECA028';
select * from [oguid] where oguidid = 'D29145E7-957D-DE11-B7EE-001143D7A3BE';
结果如下:
从计划以及统计信息上来看,在10w单位这个层次上,树的高度是一致的,所以在查找上,性能没有差异。
再来看看连表查询:
set statistics time on
set statistics io on
checkpoint;
dbcc dropcleanbuffers;
select * from [int] with(index(0)) inner join int2 on int.intid = int2.intid;
select * from [guid] inner join guid2 on guid.guidid = guid2.guidid;
输出如下:
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 64 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 61 毫秒。
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 2 毫秒。
(1000 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Int'。扫描计数 1,逻辑读取 411 次,物理读取 1 次,预读 450 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'int2'。扫描计数 1,逻辑读取 7 次,物理读取 1 次,预读 8 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(1 行受影响)
SQL Server 执行时间:
CPU 时间 = 47 毫秒,占用时间 = 1576 毫秒。
(1000 行受影响)
表 'GUID'。扫描计数 1,逻辑读取 823 次,物理读取 2 次,预读 862 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'guid2'。扫描计数 1,逻辑读取 8 次,物理读取 0 次,预读 5 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(1 行受影响)
SQL Server 执行时间:
CPU 时间 = 46 毫秒,占用时间 = 4850 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。

如果没有索引提示的情况:
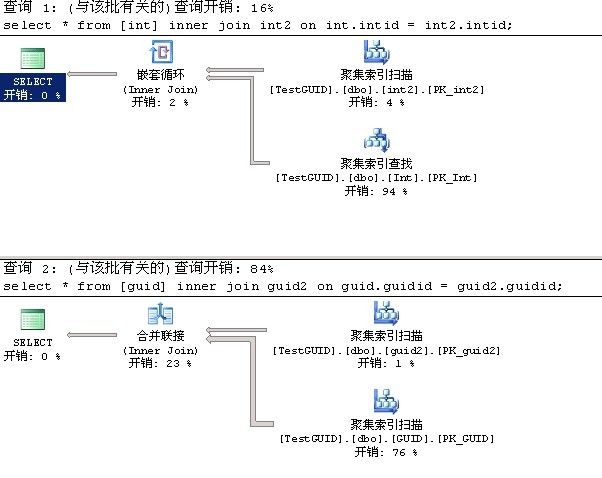
所以在连表查找方面无论是哪种情况性能也是相差不少。
可能还有其他的应用场景我就没有再一一测试了,不过我自己调优数据库经验来看,主要是还是要分应用场景,对于性能只是相差几倍的,没有必要调优,除非不是在一个数量级。另外,要看应用场景的执行频繁度,如果这个sql平均每秒执行1000次,而你节省他每次10个IO,都是很有意义的,比起N长时间才执行一次,你花大力气去调优节省它1wIO,也是毫无意义的。
另外从需求上来说,有些应用场景比如数据迁移,不能让外部猜测下一个ID(比如你的用户ID,不想让别人知道你的网站用户增长速度),都有可能是GUID的应用场景。当然也有可能是有些场景需要用户有一个简而易记的ID,比如订单号,当当的订单号如果是个GUID,那我每次打电话跟他们客服沟通,都需要念半天号码。
总而言之,仅从性能考虑,GUID肯定是不如INT,但是天生我才必有用,总有他适合的场景。
Int自增表
测试插入的脚本:
GUID表插入1w条记录是63156微妙,62436微妙。
基于上两次测试没有测试OGUID表了。
每次测试均truncate了表。
再测试10w条记录的插入情况:
10w
int 620330 618093
GUID
686923 667780
OGUID
635436 642013
从数据能看出int是最快的,其次是顺序化的GUID插入,再次是无序GUID。
再测试一下全表扫描的IO:
set statistics time on
set statistics io on
checkpoint;
dbcc dropcleanbuffers;
select * from [int];
select * from [guid];
select * from [oguid];
统计情况如下:
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 2 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 66 毫秒。
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 12 毫秒。
(100000 行受影响)
表 'Int'。扫描计数 1,逻辑读取 411 次,物理读取 1 次,预读 450 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 78 毫秒,占用时间 = 2095 毫秒。
(100000 行受影响)
表 'GUID'。扫描计数 1,逻辑读取 823 次,物理读取 2 次,预读 862 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 94 毫秒,占用时间 = 2487 毫秒。
(100000 行受影响)
表 'OGUID'。扫描计数 1,逻辑读取 564 次,物理读取 1 次,预读 552 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 63 毫秒,占用时间 = 1511 毫秒。
从IO上看,GUID表是int的一倍,OGUID是int的120%。
再看聚集索引查找:
set statistics time on
set statistics io on
checkpoint;
dbcc dropcleanbuffers;
select * from [int] where intID = 99999;
select * from [guid] where guidid = 'F0EE26A1-9F55-4D7B-B580-7F7164ECA028';
select * from [oguid] where oguidid = 'D29145E7-957D-DE11-B7EE-001143D7A3BE';
结果如下:
从计划以及统计信息上来看,在10w单位这个层次上,树的高度是一致的,所以在查找上,性能没有差异。
再来看看连表查询:
set statistics time on
set statistics io on
checkpoint;
dbcc dropcleanbuffers;
select * from [int] with(index(0)) inner join int2 on int.intid = int2.intid;
select * from [guid] inner join guid2 on guid.guidid = guid2.guidid;
输出如下:
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 64 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 61 毫秒。
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 2 毫秒。
(1000 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Int'。扫描计数 1,逻辑读取 411 次,物理读取 1 次,预读 450 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'int2'。扫描计数 1,逻辑读取 7 次,物理读取 1 次,预读 8 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(1 行受影响)
SQL Server 执行时间:
CPU 时间 = 47 毫秒,占用时间 = 1576 毫秒。
(1000 行受影响)
表 'GUID'。扫描计数 1,逻辑读取 823 次,物理读取 2 次,预读 862 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'guid2'。扫描计数 1,逻辑读取 8 次,物理读取 0 次,预读 5 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(1 行受影响)
SQL Server 执行时间:
CPU 时间 = 46 毫秒,占用时间 = 4850 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
如果没有索引提示的情况:
所以在连表查找方面无论是哪种情况性能也是相差不少。
可能还有其他的应用场景我就没有再一一测试了,不过我自己调优数据库经验来看,主要是还是要分应用场景,对于性能只是相差几倍的,没有必要调优,除非不是在一个数量级。另外,要看应用场景的执行频繁度,如果这个sql平均每秒执行1000次,而你节省他每次10个IO,都是很有意义的,比起N长时间才执行一次,你花大力气去调优节省它1wIO,也是毫无意义的。
另外从需求上来说,有些应用场景比如数据迁移,不能让外部猜测下一个ID(比如你的用户ID,不想让别人知道你的网站用户增长速度),都有可能是GUID的应用场景。当然也有可能是有些场景需要用户有一个简而易记的ID,比如订单号,当当的订单号如果是个GUID,那我每次打电话跟他们客服沟通,都需要念半天号码。
总而言之,仅从性能考虑,GUID肯定是不如INT,但是天生我才必有用,总有他适合的场景。