简单的光线跟踪
昨天搞了本数<<GPU高性能编程CUDA实战>>感觉不错花了一个下午+晚上才看了100页,其中有个超简单光线跟踪算法,试了下感觉不错。
原理如下图(是那本数上的):
其中没有考虑到摄像机模型,基本就是平面上一一个像素点发送平行与Z轴光线看能与哪些点球碰撞,并计算出像素值,计算过程中我重新使用了TBB来加速,CUDA还是很郁闷的,只能用在NVIDIA的显卡特定上.图像部分直接使用的是OpenCV的接口,封装成CPUBitmap,虽然自己重新写下也没有太多的代码(http://www.thecodeway.com/blog/?p=409),可是谁让咱懒呢.
代码如下:
#include <tbb/tbb.h> #include <math.h> #include <stdlib.h> #include <highgui.h> #include <time.h> #pragma comment(lib,"opencv_core231.lib") #pragma comment(lib,"opencv_highgui231.lib") #define INF 2e10f #define SPHERES 20 #define rnd(x) (x*rand()/RAND_MAX) #define DIM 640 struct Sphere { float r,b,g; float radius; float x,y,z; float hit(float ox,float oy,float *n) { float dx = ox - x; float dy = oy - y; if(dx * dx + dy*dy < radius*radius){ float dz = sqrtf(radius*radius - dx*dx - dy*dy); *n = dz / sqrtf(radius*radius); return dz + z; } return -INF; } }; class CPUBitmap { public: CPUBitmap(int dimx,int dimy) { img = cvCreateImage(cvSize(dimx,dimy),8,3); } ~CPUBitmap() { if(img) cvReleaseImage(&img); } unsigned char *get_ptr() { return (unsigned char *)img->imageDataOrigin; } void display_and_exit() { cvShowImage("CPUBitmap",img); cvWaitKey(0); } private: IplImage *img; }; struct ray_kernel { ray_kernel(Sphere* s,int num,unsigned char* ptr,int dimx): sp(s),number(num), ptr(ptr),dimx(dimx) { } void operator()(const tbb::blocked_range2d<int,int>& r)const { for(int y = r.rows().begin();y<r.rows().end();y++) { for(int x = r.cols().begin();x < r.cols().end();x ++) { int offset = x + y*dimx; float ox = (x - dimx/2); float oy = (y - dimx/2); float r= 0,g = 0,b = 0; float maxz = -INF; for(int i = 0;i<number;i++) { float n; float t = sp[i].hit(ox,oy,&n); if(t > maxz) { float fscale = n; r = sp[i].r * fscale; g = sp[i].g * fscale; b = sp[i].b * fscale; } } ptr[offset*3 + 0] = (int)(b*255); ptr[offset*3 + 1] = (int)(g*255); ptr[offset*3 + 2] = (int)(r*255); } } } int number; int dimx; Sphere *sp; unsigned char *ptr; }; int main() { Sphere *s; tbb::task_scheduler_init init; srand(time(NULL)); CPUBitmap bitmap(DIM,DIM); s = new Sphere[SPHERES]; for(int i = 0;i<SPHERES;i++){ s[i].r = rnd(1.0f); s[i].g = rnd(1.0f); s[i].b = rnd(1.0f); s[i].x = rnd(1000.0f) - 500; s[i].y = rnd(1000.0f) - 500; s[i].z = rnd(1000.0f) - 500; s[i].radius = rnd(100.0f) + 20; } tbb::blocked_range2d<int,int> range2d(0,DIM,0,DIM); tbb::parallel_for(range2d,ray_kernel(s,SPHERES,bitmap.get_ptr(),DIM)); bitmap.display_and_exit(); delete[] s; return 0; }
代码基本是直译的书上的代码,不过它用的是CUDA,我用的是TBB而已.
效果如下:

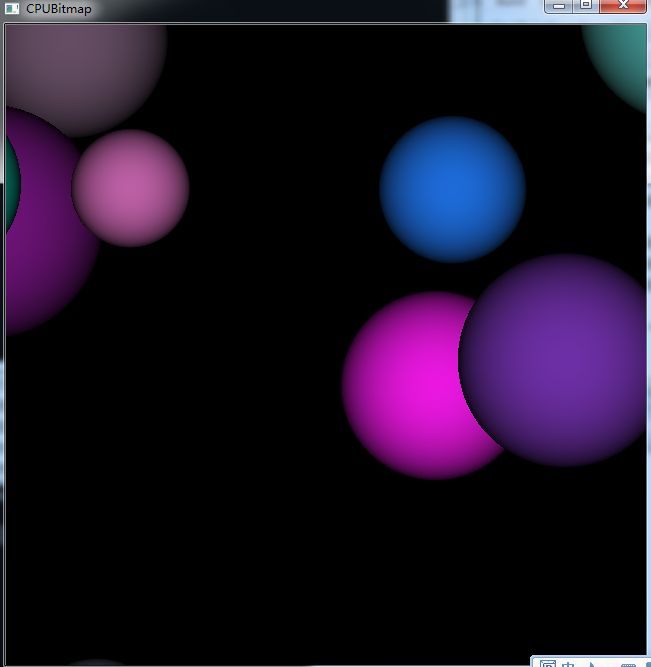
ps:1.不知道怎么回事,CUDA3.2的开发包可用使用,但是CUDA4.0的有问题(新版本的可以使用nvidia的thrust库<-官方说某些情况下比tbb快200倍)
2.CUDA的代码带我的电脑上编译不是一般的慢,而是特慢.
3.早上敲了个CUDA的代码,直接把电脑搞死机(蓝屏?!)了.
不知道哪个高手能够解答下.....