大数据处理
参考:http://blog.csdn.net/v_july_v/article/details/7382693
set/map/multiset/multimap都是基于RB-tree之上,所以有自动排序功能,而hash_set/hash_map/hash_multiset/hash_multimap都是基于hashtable之上,所以不含有自动排序功能,至于加个前缀multi_无非就是允许键值重复而已。
注:10亿 约等于 1G. (实际10亿约为0.93G)
基本思路:分而治之/Hash映射 + Hash统计 + 堆/快速/归并排序
下面是10个用这种思路的例子。
1、海量日志数据,提取出某日访问百度次数最多的那个IP。
- 分而治之/hash映射:针对数据太大,内存受限,只能是:把大文件化成(取模映射)小文件,即16字方针:大而化小,各个击破,缩小规模,逐个解决
- hash统计:当大文件转化了小文件,那么我们便可以采用常规的hash_map(ip,value)来进行频率统计。
- 堆/快速排序:统计完了之后,便进行排序(可采取堆排序),得到次数最多的IP。
具体而论,则是: “首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map对那1000个文件中的所有IP进行频率统计,然后依次找出各个文件中频率最大的那个IP)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。”
2、寻找热门查询,300万个查询字符串中统计最热门的10个查询。
- 分而治之/hash映射:顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为x0,x1,...x4999)中。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。
- hash统计:对每个小文件,采用trie树/hash_map等统计每个文件中出现的词以及相应的频率。
- 堆/归并排序:取出出现频率最大的100个词(可以用含100个结点的最小堆)后,再把100个词及相应的频率存入文件,这样又得到了5000个文件。最后就是把这5000个文件进行归并(类似于归并排序)的过程了。
注:可考虑用字典树。
3、 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
- 分而治之/hash映射:遍历文件a,对每个url求取
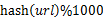 ,然后根据所取得的值将url分别存储到1000个小文件(记为
,然后根据所取得的值将url分别存储到1000个小文件(记为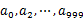 ,这里漏写个了a1)中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为
,这里漏写个了a1)中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为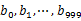 )。这样处理后,所有可能相同的url都在对应的小文件(
)。这样处理后,所有可能相同的url都在对应的小文件(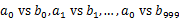 )中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。 - hash统计:求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
4、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
5、海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10。
6、有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
7、怎么在海量数据中找出重复次数最多的一个?
8、上千万或上亿数据(有重复),统计其中出现次数最多的钱N个数据。
9、一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
可用字典树解。
10. 1000万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串。请怎么设计和实现?
总结:这类题的特征是求海量数据中满足最大、最多的记录。
Bloom filter/Bitmap
上面是用hash统计元素的,Bloom filter/Bitmap也是用来统计元素的,它采用位数组和k个相互独立的hash函数相结合的方法,比单纯的hash节省存储空间。
Bloom filter
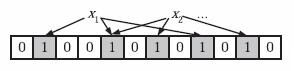
下面我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。

为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位,即第二个“1“处)。
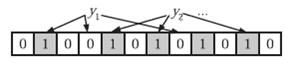
在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有hi(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素(因为y1有一处指向了“0”位)。y2或者属于这个集合,或者刚好是一个false positive。
Bit-map
所谓的Bit-map就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。
如:已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。 (可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话)
腾讯面试题:给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
用位图/Bitmap的方法,申请512M的内存,一个bit位代表一个unsigned int值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
Trie树/数据库/倒排索引
Trie树
即字典树,又称单词查找树或键树。Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
它有3个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
举个在网上流传颇广的例子,如下:
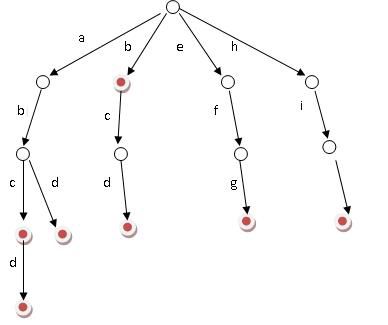
题目:给你100000个长度不超过10的单词。对于每一个单词,我们要判断他出没出现过,如果出现了,求第一次出现在第几个位置。
好比假设有b,abc,abd,bcd,abcd,efg,hii 这6个单词,我们构建的树就是如下图这样的:
倒排索引(Inverted index)
存储单词的位置,以查找句子。
以英文为例,下面是要被索引的文本:
T0 = "it is what it is"
T1 = "what is it"
T2 = "it is a banana"
我们就能得到下面的反向文件索引:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
如果要搜索句子what is it 时,即单词what 、is和it所在集合的交集。