HtmlParser的使用-爬虫学习(三)
关于这个HtmlParser的学习资料,网上真的很匮乏,这个好用的东西不要浪费啊,所以我在这里隆重的介绍一下。
HtmlParser是一个用来解析HTML文件的Java包,主要用于转换盒抽取两个方面。
利用HtmlParser,你可以实现下面的内容的抽取:
a.文本抽取 b.链接抽取 c.资源抽取。可以搜集到图像和声音文件等资源
d.链接检查。保证链接是有用的 e.站点检查,可以查看页面不同版本之间的差异
利用HtmlParser,你可以利用它的转换功能,主要体现在几个方面:
a.URL重写。能够修正页面中的错误链接 b.广告清楚。清除页面中的广告内容和指向广告的链接
c.将HTML页面转化成XML页面 d.HTML页面的清理
我们开始学习了,我们先来看看这个包中的类的大体框架:
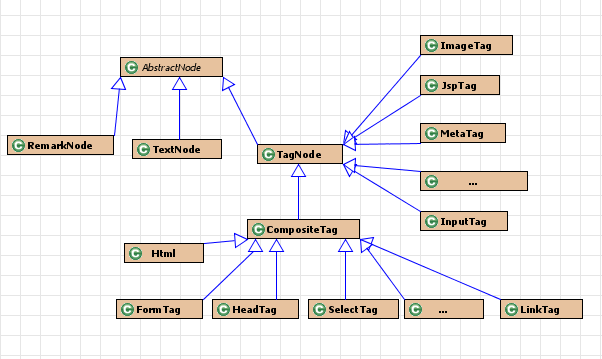
在org.htmlparser包下,有几个接口和类:
Parser类:这个是HtmlParser的核心类,主要的完成对Html页面的分析工具,通过这个类我们可以得到这个页面的各种信息。
Parser():无参数的构造方法。
Parser(String resource):根据String参数构建对象,这个参数可以是URL或者本地文件的路径。
Parser(URLConnection connection):根据一个URLConnection对象构建对象。
createParser(String html, String charset):通过路径名创建对象,并且设置编码格式。
elements():返回这个类的元素节点的迭代器,通过这个迭代器我们遍历页面的节点。
setURL():设置这个Parser类要解析的页面的地址。
parset():根据一个NodeFilter,也就是一个过滤器去获取过滤剩下的页面信息。
visitAllNodeWith(NodeVisitor visitor):通过一个NodeVisitor去遍历所有的节点。
小试牛刀(这个只是简单的使用,具体的类看下面的介绍):
@Test public void testVisitAllNodeWith() throws Exception { Parser parser = new Parser(); parser.setURL("http://www.google.cn"); parser.setEncoding(parser.getEncoding()); NodeVisitor visitor = new NodeVisitor() { public void visitTag(Tag tag) { System.out.println("*************************"); System.out.println(tag.getTagName()); System.out.println("*************************"); } }; parser.visitAllNodesWith(visitor); } @Test public void testElements() throws Exception { Parser parser = new Parser(); parser.setURL("http://www.google.cn"); parser.setEncoding(parser.getEncoding()); NodeIterator iterator = parser.elements(); while(iterator.hasMoreNodes()) { Node node = iterator.nextNode(); System.out.println("*************************"); System.out.println(node.getText()); System.out.println("*************************"); } }
Node接口:这个接口就好像定义了一颗树来表示一个HTML页面,定义获取父子兄弟节点的方法,定义了节点到对应节点的html文本的方法,从上面的图中我们看到有AbstractNode这个类,这个是Node的实现类,起到形成树形结构的作用,在HTML页面中有三种类型的Node,RemarkNode代表html中的注释,TagNode代表标签节点,TextNode代表文本节点。
getChildren():获取子节点,返回一个NodeList对象。
getFirstChildren():获取第一个子节点,返回一个Node对象。
getLastChildren():获取最后一个子节点,返回一个Node对象。
getPreviousSibling():获取前一个兄弟节点。
getNextSibling():获取后一个兄弟节点。
getParent():获取父节点。
getText():获得文本内容。
toPlainTextString():获取纯文本信息。
toHtml():获取Html信息。
accept(NodeVisitor visitor):对这个node应用visitor。
为了方法大家观看,还是自己写一个Html,然后练练方法:
node.html
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <title>Title Node</title> </head> <body> <!-- remark --> <h1>H1 Node</h1> <div id="d1"> <div id="d2"> <a>Div Node</a> </div> </div> </body> </html>
测试方法:
@Test public void testNode() throws Exception { Parser parser = new Parser(); parser.setURL("src/node.html"); parser.setEncoding(parser.getEncoding()); NodeIterator iterator = parser.elements(); while(iterator.hasMoreNodes()) { Node node = iterator.nextNode(); System.out.println("*************************"); System.out.println("Text:" + node.getText()); System.out.println("PlainText:" + node.toPlainTextString()); System.out.println("ToHtml:" + node.toHtml()); System.out.println("*************************"); } }
Remark接口:这个接口代表了注释。实现类有RemarkNode,这个类代表了注释节点。
getText():获取文本。
setText():设置文本。
Tag接口:这个接口就代表了Html页面的标签,实现类有TagNode,就是标签节点。
getAttribute(String name):根据name拿到该标签的属性,当然有对应的setAttribute方法。
getTagName():拿到这个标签的名字。
toTagHtml():返回这个标签的html。
Text接口:这个接口代表Html的文本,实现类有TextNode,就是文本节点。
getText():拿到文本值。
setText():设置文本值。
NodeFilter接口:这个接口定义的是过滤器,通过各种各样的过滤器可以筛选出特定的节点,具体的应用看下面的org.htmlparser.filters包下的类的应用,
accept(Node node):这个方法的返回值是boolean,方法的作用就是判断要不要保留这个节点。
在org.htmlparser.visitors包下,有一个很重要的类NodeVisitor,下面讲解一下:
NodeVisitor类:通过这个visitor我们可以遍历树的每一个节点,对于一个符合条件的节点,我们还可以进行适当的处理。
visitRemarkNode(Remark remark):访问remark类型的节点,通过重写这个方法可以实现对这个remark类型节点的特定操作。
visitStringNode(Text text):访问Text类型的节点,通过重写这个方法可以实现对这个Text类型节点的特定操作。
visitTag(Tag tag):访问Tag类型的节点,通过重写这个方法可以实现对这个Tag类型节点的特定操作。
小试牛刀:
public class MyVisitor extends NodeVisitor{ public MyVisitor() { } public void visitTag(Tag tag) { if(tag.getTagName().equals("BODY")) System.out.println("**********body**************"); System.out.println("TagName:" + tag.getTagName()); } public void visitStringNode(Text text) { System.out.println("text" + text.getText()); } public static void main(String[] args) throws Exception{ Parser parser = new Parser("src/node.html"); MyVisitor visitor = new MyVisitor(); parser.visitAllNodesWith(visitor); } }
在org.htmlparset.filters包下,有着很多过滤器,每个过滤器类都有自己特定的作用:
判断类Filter:
TagNameFilter
HasAttributeFilter
HasChildFilter
HasParentFilter
HasSiblingFilter
IsEqualFilter
逻辑运算Filter:
AndFilter
NotFilter
OrFilter
XorFilter
其他Filter:
NodeClassFilter
StringFilter
LinkStringFilter
LinkRegexFilter
RegexFilter
CssSelectorNodeFilter
下面是一个关于TagNameFilter的小试牛刀:
@Test public void testTagNameFilter() throws Exception{ Parser parser = new Parser("src/node.html"); NodeFilter filter = new TagNameFilter("DIV"); NodeList nodeList = parser.extractAllNodesThatMatch(filter); if(nodeList != null) { for(int i = 0; i < nodeList.size(); i++) { Node node = nodeList.elementAt(i); System.out.println("Text:" + node.getText()); System.out.println("****************************"); } } }