Javascript的一种代码结构方式——插件式
Javascript的一种代码结构方式——插件式
上几周一直在做公司的webos的前端代码的重构,之中对javascript的代码进行了重构(之前的代码耦合严重、拓展、修改起来比较困难),这里总结一下当中使用的一种代码结构——插件式(听起来怎么像独孤九剑一样.....)。
代码结构
这直接上代码结构图(Javascript部分)
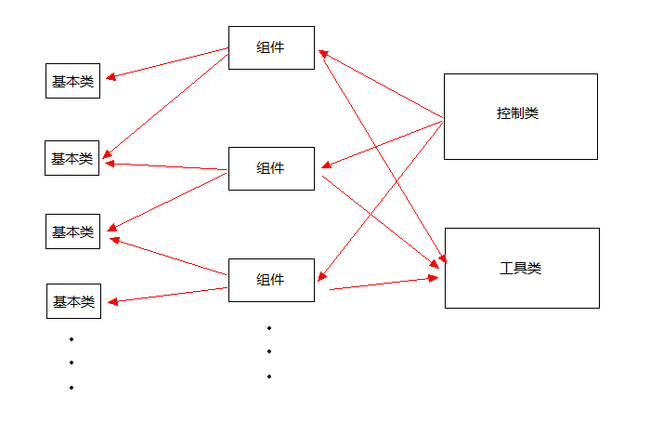
ps:箭头的指向A->B,表示A调用B
由上面可以看到四种类型的东西:
控制类:提供一个全局的命名空间、保存上下文信息、组件、组件提供的全局方法,负责调用组件初始化。
代码示例如下(不完整):
var webos= { context :{}, components : [], //所有组件 methods : {}, //组件提供的方法 //webos入口 load : function(webosContext) { webos._init(); webos._uiRender() ; webos._dataRender(); webos._eventRender(); }, //初始化 _init : function(){ $(webos.components).each(function(index, component){ component.init(webos.context) ; }); }, //ui渲染 _uiRender : function(){ }, //数据加载 _dataRender : function(){ }, //绑定事件 _eventRender : function(){ }, //注册全局方法 addGlobalMethod : function(methodName, method){ }, //调用全局方法 execGlobalMethod : function(methodName, params){ }, //注册组件 registerComponent : function(component) { webos.components.push(component); } };
工具类:提供工具方法,不属于组件和基础类的方法将会放在这里。
webos.utils = {
...
}
基本类:最基础的类,供给组件使用,原则上一个能称为对象的东西都应该写成一个类。
例,下面组件的接口实现类:
var IComponent = function() { this.init = function(context){}; this.uiRender = function(context){}; this.dataRender = function(context){}; this.eventRender = function(context){}; this.reload = function(){}; }
组件:例如导航栏、工具栏、任务栏、桌面组件,都是以一个组件形式存在。
在组件里面,组件的创建、初始化、数据渲染、事件绑定都自己解决(有点像自治区)。
//导航栏组件 ;(function(webos){ var NavBar = function() { }; //继承Component基类 NavBar.prototype = new IComponent(); NavBar.prototype.init = function(context) { }; //定位为构建基础的HTML NavBar.prototype.uiRender = function(context){ }; //加载数据 NavBar.prototype.dataRender = function(context){ }; NavBar.prototype.eventRender = function(context){ }; .... //注册组件 webos.registerComponent(new NavBar()); })(webos);
组件之间怎么联系呢?
组件与组件之间进行沟通的手段只有一个——就是将自己给其他组件使用的方法提供给控制器(调用控制器的addGlobalMethod),控制器保存你的方法,当其他组件使用你的方法时候,就向控制器要(调用控制器的execGlobalMethod )。
为啥这种结构叫插件式呢?
看过控制类和组件的代码就知道,控制类只负责帮助调用已经注册到控制类里的组件的初始化方法、组件完成关于自己的所有事。所以当我们需要做一个新的组件时候,只需完成自身的创建、渲染、事件绑定,然后注册到控制类里,控制类就会帮你初始化,组件间互不干涉,这就是插件式(好吧,这是我的理解,并没有这种官方的定义)!!!
优点?
1、组件的维护、拓展非常简单,因为都是独立开来
2、添加新组件对已存在的组件几乎没有影响(当然你写的组件也不要影响他其他组件、例如样式、HTML)
缺点!
1、这种结构有应用场景要求,更偏向富web应用使用
分布式系统设计(9)
避免我们不是在制造永动机,在分布式系统设计前,几个理论必须了解。CAP、BASE、ACID、一致性以及五分钟理论。
CAP

C: Consistency 一致性
A: Availability 可用性(指的是快速获取数据)
P: Tolerance of network Partition 分区容忍性(分布式)
CAP理论最早是在2000年7月19号,由Berkeley的Eric Brewer教授在ACM PODC会议上的一个开题演讲中提出,PPT在此。此后,MIT的Seth Gilbert和Nancy Lynch,理论上证明了Brewer猜想是正确的,CAP理论在学术上正式作为一个定理出现了。
NoSQL一定程度上就是基于这个理论提出来的,因为传统的SQL数据库(关系型数据库)都是都是具有ACID属性,对一致性要求很高,因此降低了A(availability)和P(partion tolerance),因此,为了提高系统性能和可扩展性,必须牺牲C(consistency),推翻关系型数据库中ACID这一套。
依据CAP理论,从应用的需求不同,我们对数据库时,可以从三方面考虑:
· 考虑CA,这就是传统上的关系型数据库(RMDB).
· 考虑CP,主要是一些Key-value数据库,典型代表为google的Big Table
· 考虑AP,主要是一些面向文档的适用于分布式系统的数据库,如SimpleDB。
而对大型网站尤其是SNS网站,对于数据的短期存储,可用性与分区容忍性优先级要高于数据一致性,一般会尽量朝着 A、P 的方向设计,而对于数据的持久存储,可以通过传统的SQL来保证一致性(最终一致性)。
CAP理论出现后,很多大规模的网站,尤其是SNS网站的数据库设计都利用其思想,包括Amazon,Facebook和Twitter这几个新兴的IT巨头,因此,一定程度上来讲,他们都是CAP的信徒。另一方面,他们从实践上证明了CAP理论的正确性。
各个系统在CAP理论中的详细体现可以参考上一节的图:
http://www.cnblogs.com/jacksu-tencent/p/3426605.html
ACID和BASE
有趣的是,ACID的意思是酸,而BASE却是碱的意思,因此这是一个对立的东西。其实,从本质上来讲,酸(ACID)强调的一致性(CAP中的C),而碱(BASE)强调是可用性(CAP中的A)。
传统关系型数据库系统的事务都有ACID的属性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。英文为:
· Atomic: Everything in a transaction succeeds or the entire transaction is rolled back.
· Consistent: A transaction cannot leave the database in an inconsistent state.
· Isolated: Transactions cannot interfere with each other.
· Durable: Completed transactions persist, even when servers restart etc.
中译为:
· 原子性: 整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
· 一致性: 在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
· 隔离性: 两个事务的执行是互不干扰的,一个事务不可能看到其他事务运行时,中间某一时刻的数据。 两个事务不会发生交互。
· 持久性: 在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
在数据库系统中,事务的ACID属性保证了数据库的一致性,比如银行系统中,转账就是一个事务,从原账户扣除金额,以及向目标账户添加金额,这两个数据库操作的总和构成一个完整的逻辑过程,不可拆分,为原子,从而保证了整个系统中的总金额没有变化。
然而,这些ACID特性对于大型的分布式系统来说,适合高性能不兼容的。比如,你在网上书店买书,任何一个人买书这个过程都会锁住数据库直到买书行为彻底完成(否则书本库存数可能不一致),买书完成的那一瞬间,世界上所有的人都可以看到熟的库存减少了一本(这也意味着两个人不能同时买书)。这在小的网上书城也许可以运行的很好,可是对Amazon这种网上书城却并不是很好。
而对于Amazon这种系统,他也许会用cache系统,剩余的库存数也许是之前几秒甚至几个小时前的快照,而不是实时的库存数,这就舍弃了一致性。并且,Amazon可能也舍弃了独立性,当只剩下最后一本书时,也许它会允许两个人同时下单,宁愿最后给那个下单成功却没货的人道歉,而不是整个系统性能的下降。
其实,上面的思想是从CAP理论得到的启发,在CAP理论中:
在设计分布式服务中,通常需要考虑三个应用的属性:一致性、可用性以及分区宽容性。但是在实际的设计中,不可能这三方面同时做的很好。
由于CAP理论的存在,为了提高性能,出现了ACID的一种变种BASE:
· Basic Availability:基本可用
· Soft-state :软状态/柔性事务,可以理解为”无连接”的, 而 “Hard state” 是”面向连接”的
· Eventual consistency:最终一致性,最终整个系统(时间和系统的要求有关)看到的数据是一致的。
在BASE中,强调可用性的同时,引入了最终一致性这个概念,不像ACID,并不需要每个事务都是一致的,只需要整个系统经过一定时间后最终达到是一致的。比如Amazon的卖书系统,也许在卖的过程中,每个用户看到的库存数是不一样的,但最终买完后,库存数都为0。再比如SNS网络中,C更新状态,A也许可以1分钟才看到,而B甚至5分钟后才看到,但最终大家都可以看到这个更新。
一致性
为了更好的描述客户端一致性,我们通过以下的场景来进行,这个场景中包括三个组成部分:
• 存储系统
存储系统可以理解为一个黑盒子,它为我们提供了可用性和持久性的保证。
• Process A
ProcessA主要实现从存储系统write和read操作
• Process B 和ProcessC
ProcessB和C是独立于A,并且B和C也相互独立的,它们同时也实现对存储系统的write和read操作。
下面以上面的场景来描述下不同程度的一致性:
• 强一致性
强一致性(即时一致性) 假如A先写入了一个值到存储系统,存储系统保证后续A,B,C的读取操作都将返回最新值
• 弱一致性
假如A先写入了一个值到存储系统,存储系统不能保证后续A,B,C的读取操作能读取到最新值。此种情况下有一个“不一致性窗口”的概念,它特指从A写入值,到后续操作A,B,C读取到最新值这一段时间。
• 最终一致性
最终一致性是弱一致性的一种特例。假如A首先write了一个值到存储系统,存储系统保证如果在A,B,C后续读取之前没有其它写操作更新同样的值的话,最终所有的读取操作都会读取到最A写入的最新值。此种情况下,如果没有失败发生的话,“不一致性窗口”的大小依赖于以下的几个因素:交互延迟,系统的负载,以及复制技术中replica的个数(这个可以理解为master/salve模式中,salve的个数),最终一致性方面最出名的系统可以说是DNS系统,当更新一个域名的IP以后,根据配置策略以及缓存控制策略的不同,最终所有的客户都会看到最新的值。
I/O的五分钟法则
在1987 年,Jim Gray 与Gianfranco Putzolu 发表了这个"五分钟法则"的观点,简而言之,如果一条记录频繁被访问,就应该放到内存里,否则的话就应该待在硬盘上按需要再访问。这个临界点就是五分钟。 看上去像一条经验性的法则,实际上五分钟的评估标准是根据投入成本判断的,根据当时的硬件发展水准,在内存中保持1KB 的数据成本相当于硬盘中存据400 秒的开销(接近五分钟)。这个法则在1997 年左右的时候进行过一次回顾,证实了五分钟法则依然有效(硬盘、内存实际上没有质的飞跃),而这次的回顾则是针对SSD 这个"新的旧硬件"可能带来的影响。