黑客 专题一 常用工具
一.HTTrack 网站复制
1.1安装
apt-get install httrack webhttrack
1.2 常用命令
httrack http://www.documentfoundation.org -* +*.htm* +*.pdf -O /home/floeff/websites httrack http://www.leiyanhui.com/ -O E:\test\ -r15 -E3600 -m2000000,300000 -M1000000000 --ext-depth 1 -o0 -s0 -F "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1)" -%F "" -*.* +*.htm* +*.shtm* +*.php* +*.asp* +*.do +*.jsp +*.css +*.swf +*.js +*.jp* +*.gif +*.bmp +*.png -N100 常用存放规则 -N100 直接放到目录根下面,默认站点结构,并且外部站点也放进去 -N1004 直接放到目录根下面,文件根据后缀放置,并且外部站点的文件也一起放进去 -N1005 直接放到目录下,html放到html文件夹,其他文件也按照后缀放到单独文件夹,并且外部站点的文件也一起放进去 文件过滤(白名单): -*.* +*.htm* +*.shtm* +*.cgi +*.py +*.php* +*.phtm* +*.asp* +*.do +*.jsp +*.css +*.swf +*.js +*.jp* +*.gif +*.bmp +*.png 注意,多个任务不能放置到同一个目录里面,不然会提示文件夹锁定 另外 对css中 background:#fff url(images/head_bg.gif) repeat-x; 不能识别其中的图片 js和swf中的图片 几乎全部无法识别 小技巧: 在命令行正在执行的时候,连续按下2-4次回车可以看到滚动日志 限制类参数 -r50 50层 -E3600 限制时间为3600秒之内 -m50000000 限制非html文件为50m以内 -m50000000,100000 限制非html文件为50M html文件为100K -M1000000000 限制总体积为1G -A100000000 限制速度为100m/s -G100000000 下载1G后暂停 %e1 前面没有横线,限制外链深度为5层;不知道为何无效,所以用 --ext-depth 1的方法替代了 性能参数 -%c20 每秒20个连接 -c128 文件句柄限制,文档说与操作系统有关系,不一定越大越好 -T30 连接超时选项 -R5 重试次数限制,暂时不确定超限后是终止任务还是终止文件 -J10 速度不到10b/s的时候 放弃下载 -H0 不终止任务 -H1 超时的时候终止任务 -H2 速度太慢的时候 -H3 速度太慢或者超时 镜像参数 -N "%h%p/%n.%t" 文件保存路径 -L1 |--long-names禁止使用长文件名,防止url过长或者文件系统不支持 -K 保存原来的链接,禁止修改链接地址 -x 好像是说外部链接替换成提示消息,应该是和允许下载外链有冲突 -o0 智能识别404页面,防止保存大量没用的404页面地址 %x0 include 好像是说可以通过md5校验,避免重复的文件 蜘蛛参数 -b0 禁用cookis 默认是启用 -s0 忽略meta-tags and robots.txt -s1和-s2是遵守,但怎么遵守的没看明白 浏览参数 -F "Mozilla 1.0, Sparc, Solaris 23.54.34" 不需要解释 -%F "Mirrored [from host %s [file %s [at %s]]]" 底部代码详情见 http://www.httrack.com/html/fcguide.html
二.Metagoofil 信息收集
修改/usr/share/metagoofil/discovery中的googlesearch.py的内容如下
#self.server="www.google.com" #self.hostname="www.google.com" self.server="www.google.com.hk" self.hostname="www.google.com.hk" #self.quantity="100" self.quantity="10" # 这个值是google返回每页中有多少条结果,发现太大了在后面 do_search_files方法中self.results = h.getfile().read()会卡住不动,设置为10了有时都还有这种情况,不明白为什么。 #改了这个值后在process_files中要做相应修改 #self.counter+=100 self.counter+=10
myparser.py中解析google返回的结果(提取文件链接)的正则式也要做相应修改:
#reg_urls = re.compile('<a href="(.*?)"')
reg_urls = re.compile('<a href="[^">]*?/url\?q=([^">]*?)&sa=U.*?"')
三.FPing 判断主机在线
详情见 http://www.fping.org/fping.1.html
fping -a -g 192.168.0.1/24 >hosts.txt
四.Nmap 端口扫描
4.1 TCP 扫描
完成三次握手,最稳定.
nmap -sT -p- -PN 172.16.45.135
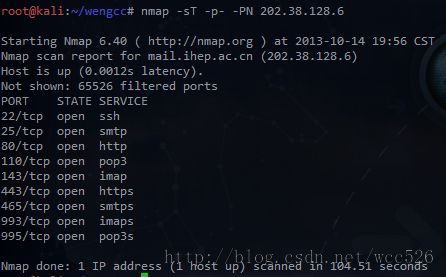
-sT 执行TCP 扫描
-p- 扫描所有端口,而不是常用的1000个端口
-PN 跳过主机发现过程,扫描所有地址
可以使用172.16.45-254 指定一个范围或者使用-iL path_to_the_text_file
4.2 SYN 扫描
完成两次握手,速度较快,隐性扫描,相当于打给别人,对方刚说喂,就挂了.是默认的扫描方式.
nmap -sS -p- -PN 172.16.45.135

4.3 UDP 扫描
扫描速度非常慢,DHCP,DNS,SNMP,TFTP使用UDP服务
nmap -sUV 172.16.45.36
-sV 用于版本扫描,精确UDP扫描结果

4.4 Xmas扫描
发送非常规的数据包,针对的是Linux或Unix操作系统,Windows 一般无效
nmap -sX -p- -PN 172.16.45.129
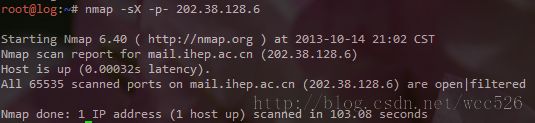
4.5 Null 扫描
发送NULL,与Xmas 相反,关闭的端口会发回一个RST数据包。只有那些100%遵循TCP RFC的系统有效,Windows 一般无效
nmap -sN -p- -PN 172.16.45.129
4.6 好用的参数
-T 0~5 5最快,为避免被检测到,设置速度
-O 用于识别操作系统
作者:wcc526 发表于2013-10-14 17:55:16 原文链接
阅读:43 评论:0 查看评论