java序列化与反序列化以及浅谈一下hadoop的序列化
1、什么是序列化和反序列化
神马是序列化呢,序列化就是把
内存中的对象的状态信息,转换成
字节序列以便于存储(持久化)和网络传输。(网络传输和硬盘持久化,你没有一定的手段来进行辨别这些字节序列是什么东西,有什么信息,这些字节序列就是垃圾)。
反序列化就是将收到
字节序列或者是硬盘的持久化数据,转换成
内存中的对象。
2、JDK的序列化
JDK的序列化只有实现了serializable接口就能实现序列化与反序列化,但是记得一定要加上序列化版本ID serialVersionUID
这个是识别序列化的之前那个类的到底是哪一个?我们显示这个序列化版本ID的目的就是为了:
1) 在某些场合,希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有相同的serialVersionUID;
2) 在某些场合,不希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有不同的serialVersionUID。
java的序列化算法要考虑到下面这些东西:◆将对象实例相关的类元数据输出。
◆递归地输出类的超类描述直到不再有超类。
◆类元数据完了以后,开始从最顶层的超类开始输出对象实例的实际数据值。
◆从上至下递归输出实例的数据
所以java的序列化确实很强大,序列化后得到的信息也很详细,所以反序列化就so easy.
但是这样做也有它的坏处,序列化后很占内存,所以不一定详细就是好处,简单有时也是不错的。
在hadoop中,hadoop实现了一套自己的序列化框架,hadoop的序列化相对于JDK的序列化来说是比较简洁的。在集群中信息的传递主要就是靠这些序列化的字节序列来传递的所以更快速度更小的容量就变得非常地重要了。
说了太多的废话,还是扯回JDK的序列化吧。下面我们看一下在JDK中式如何实现序列化的。
首先我们有一个需要序列化的类如下(必须实现serializable接口)
import java.io.Serializable;
public class Block implements Serializable{
/**
*
*/
private static final long serialVersionUID = 1L;
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Block(int id, String name) {
this.id = id;
this.name = name;
}
}
下面我们来测试一下序列化的结果:
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class TestSerializable {
public static void main(String[] args) throws IOException,
ClassNotFoundException {
//将序列化化的数据写到文件out里面(持久化)
FileOutputStream fos = new FileOutputStream("./out");
ObjectOutputStream oos = new ObjectOutputStream(fos);
for (int i = 0; i < 100; i++) {
Block b = new Block(i, "B"+i);
oos.writeObject(b);
}
oos.flush();
oos.close();
//读出一个序列化的对象的字节序列(^..^)就是反序列化
FileInputStream fis = new FileInputStream("./out");
ObjectInputStream ois = new ObjectInputStream(fis);
Block b2 = (Block) ois.readObject();
ois.close();
System.out.println(b2.getName());
}
}
测试的结果:(取出第一个对象的name)
B0生成一百个对象的持久化数据的大小是:1.60 KB (1,643 字节)一个对象平均16个字节,该类只有两个字段一个是int,一个字符串但是字符串的长度为2,所以我们可以感受到这冗余还是挺大的。
3、hadoop的序列化
hadoop的序列化的特点是:
1、紧凑:由于带宽是集群中信息传递的最宝贵的资源所以我们必须想法设法缩小传递信息的大小,hadoop的序列化就为了更好地坐到这一点而设计的。
2、对象可重用:JDK的反序列化会不断地创建对象,这肯定会造成一定的系统开销,但是在hadoop的反序列化中,能重复的利用一个对象的readField方法来重新产生不同的对象。
3、可扩展性:当前hadoop的序列化有多中选择
*可以利用实现hadoop的Writable接口。
*使用开源的序列化框架protocol Buffers,Avro等框架。
我们可以注意到的是hadoop2.X之后是实现一个叫YARN的云操作系统,所有应用(如mapreduce,或者其他spark实时或者离线的计算框架都可以运行在YARN上),YARN还负责对资源的调度等等。
YARN的序列化就是用Google开发的序列化框架protocol Buffers,proto目前支持支持三种语言C++,java,Python所以RPC这一层我们就可以利用其他语言来做文章,满足其他语言开发者的需求。
我屮艸芔茻,扯得有点远。
回到hadoop原生的序列化,hadoop原生的序列化类需要实现一个叫Writeable的接口,类似于serializable接口。
还有hadoop也为我们提供了几个序列化类,他们都直接或者间接地实现了Writable接口。如:IntWritable,LongWritable,Text等等。
实现Writable接口必须实现两个方法:write(DataOutputStream out);readField(DataInputStream in)方法。
下面是一个hadoop的序列化例子:
package hadoop;
import java.io.ByteArrayOutputStream;
import java.io.DataInput;
import java.io.DataInputStream;
import java.io.DataOutput;
import java.io.DataOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.junit.Test;
public class Testhadoop_serializable_writable {
@Test
public void serializable() throws IOException {
ByteArrayOutputStream out = new ByteArrayOutputStream();
DataOutputStream dataOut = new DataOutputStream(out);
FileOutputStream fos = new FileOutputStream("./hadoop_out");
for (int i = 0; i < 10; i++) {
Text t1 = new Text(String.valueOf(i));
Text t2 = new Text("mw");
MyWritable mw = new MyWritable(t1,t2);
mw.write(dataOut);
}
dataOut.close();
fos.write(out.toByteArray());
fos.flush();
fos.close();
FileInputStream fis = new FileInputStream("./hadoop_out");
DataInputStream dis = new DataInputStream(fis);
for (int i = 0; i < 10; i++) {
MyWritable mw = new MyWritable(new Text(), new Text());
mw.readFields(dis);
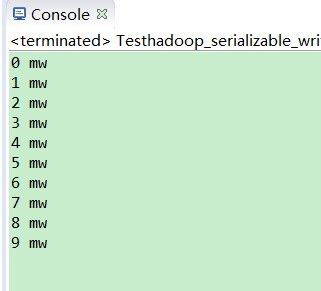
System.out.println(mw.getId() + " " + mw.getName());
}
}
}
class MyWritable implements Writable {
private Text id;
private Text name;
public MyWritable(Text id, Text name) {
super();
this.id = id;
this.name = name;
}
public synchronized Text getId() {
return id;
}
public synchronized void setId(Text id) {
this.id = id;
}
public synchronized Text getName() {
return name;
}
public synchronized void setName(Text name) {
this.name = name;
}
@Override
public void write(DataOutput out) throws IOException {
id.write(out);
name.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
id.readFields(in);
name.readFields(in);
}
}
我们可以看到我们实现的自己序列化类MyWritable。他有两个字段都是Text,Text是hadoop自带的序列化类,可以看做字符串(类似吧)吧?!
write()和readField()用到的是回调函数,将流(DataOutputStream DataInputStream)写出,或者读出,都是用到回调函数(hook(钩子))。
上面的运行结果如下:
生成的字节序列:
命令行结果:
完!
作者:oChenXiaoZuo1 发表于2014-8-18 20:24:06 原文链接
阅读:0 评论:0 查看评论