#celery#集群管理实现

本来这个方案打算用在我的Sora上,但是因为某些问题打算弃用celery。但既然有人想问怎样实现多机器的管理,那就写出来了:
架构:
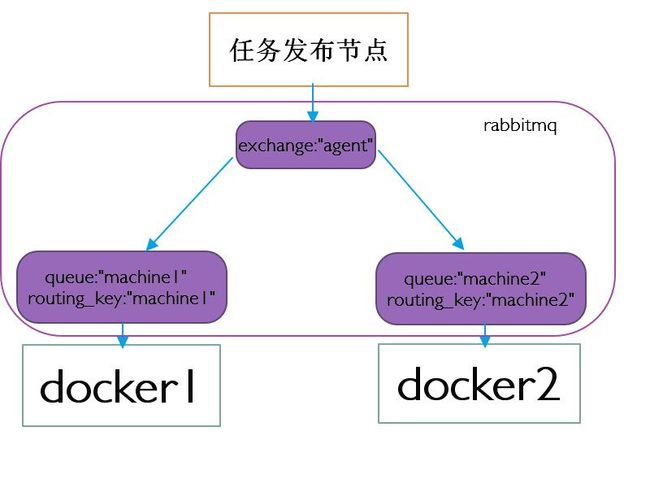
这里作为例子的celery app为myapp:
root@workgroup0:~/celeryapp# ls myapp agent.py celery.py config.py __init__.py root@workgroup0:~/celeryapp#
公用代码部分:
celery.py:(备注:172.16.77.175是任务发布节点的ip地址)
from __future__ import absolute_import
from celery import Celery
app = Celery('myapp',
broker='amqp://[email protected]//',
backend='amqp://[email protected]//',
include=['myapp.agent'])
app.config_from_object('myapp.config')
if __name__ == '__main__':
app.start()
config.py:
from __future__ import absolute_import
from kombu import Queue,Exchange
from datetime import timedelta
CELERY_TASK_RESULT_EXPIRES=3600
CELERY_TASK_SERIALIZER='json'
CELERY_ACCEPT_CONTENT=['json']
CELERY_RESULT_SERIALIZER='json'
CELERY_DEFAULT_EXCHANGE = 'agent'
CELERY_DEFAULT_EXCHANGE_TYPE = 'direct'
CELERT_QUEUES = (
Queue('machine1',exchange='agent',routing_key='machine1'),
Queue('machine2',exchange='agent',routing_key='machine2'),
)
__init__.py:(空白)
任务发布节点的agent.py:
from __future__ import absolute_import
from myapp.celery import app
@app.task
def add(x,y):
return {'the value is ':str(x+y)}
@app.task
def writefile():
out=open('/tmp/data.txt','w')
out.write('hello'+'\n')
out.close()
@app.task
def mul(x,y):
return x*y
@app.task
def xsum(numbers):
return sum(numbers)
@app.task
def getl(stri):
return getlength(stri)
def getlength(stri):
return len(stri)
docker1上的agent.py:
from __future__ import absolute_import
from myapp.celery import app
@app.task
def add(x,y):
return {'value':str(x+y),'node_name':'docker1'} #增加了node_name用来识别节点
@app.task
def writefile():
out=open('/tmp/data.txt','w')
out.write('hello'+'\n')
out.close()
@app.task
def mul(x,y):
return x*y
@app.task
def xsum(numbers):
return sum(numbers)
@app.task
def getl(stri):
return getlength(stri)
def getlength(stri):
return len(stri)
docker2上的:
from __future__ import absolute_import
from myapp.celery import app
@app.task
def add(x,y):
return {'value':str(x+y),'node_name':'docker2'}
@app.task
def writefile():
out=open('/tmp/data.txt','w')
out.write('hello'+'\n')
out.close()
@app.task
def mul(x,y):
return x*y
@app.task
def xsum(numbers):
return sum(numbers)
@app.task
def getl(stri):
return getlength(stri)
def getlength(stri):
return len(stri)
在这个例子中我只测试add()函数:
在docker1节点上启动worker:(用-Q指定监听的queue)
root@workgroup1:~/celeryapp# celery -A myapp worker -l info -Q machine1 /usr/local/lib/python2.7/dist-packages/celery/platforms.py:766: RuntimeWarning: You are running the worker with superuser privileges, which is absolutely not recommended! Please specify a different user using the -u option. User information: uid=0 euid=0 gid=0 egid=0 uid=uid, euid=euid, gid=gid, egid=egid, -------------- [email protected] v3.1.17 (Cipater) ---- **** ----- --- * *** * -- Linux-3.13.0-24-generic-x86_64-with-Ubuntu-14.04-trusty -- * - **** --- - ** ---------- [config] - ** ---------- .> app: myapp:0x7f472d73f190 - ** ---------- .> transport: amqp://guest:**@172.16.77.175:5672// - ** ---------- .> results: amqp://[email protected]// - *** --- * --- .> concurrency: 1 (prefork) -- ******* ---- --- ***** ----- [queues] -------------- .> machine1 exchange=machine1(direct) key=machine1 [tasks] . myapp.agent.add . myapp.agent.getl . myapp.agent.mul . myapp.agent.writefile . myapp.agent.xsum [2015-10-18 15:07:51,313: INFO/MainProcess] Connected to amqp://guest:**@172.16.77.175:5672// [2015-10-18 15:07:51,340: INFO/MainProcess] mingle: searching for neighbors [2015-10-18 15:07:52,372: INFO/MainProcess] mingle: sync with 1 nodes [2015-10-18 15:07:52,374: INFO/MainProcess] mingle: sync complete [2015-10-18 15:07:52,423: WARNING/MainProcess] [email protected] ready.
启动docker2上的worker:
root@workgroup2:~/celeryapp# celery -A myapp worker -l info -Q machine2 /usr/local/lib/python2.7/dist-packages/celery/platforms.py:766: RuntimeWarning: You are running the worker with superuser privileges, which is absolutely not recommended! Please specify a different user using the -u option. User information: uid=0 euid=0 gid=0 egid=0 uid=uid, euid=euid, gid=gid, egid=egid, -------------- [email protected] v3.1.18 (Cipater) ---- **** ----- --- * *** * -- Linux-3.13.0-24-generic-x86_64-with-Ubuntu-14.04-trusty -- * - **** --- - ** ---------- [config] - ** ---------- .> app: myapp:0x7f708cb8ec10 - ** ---------- .> transport: amqp://guest:**@172.16.77.175:5672// - ** ---------- .> results: amqp://[email protected]// - *** --- * --- .> concurrency: 1 (prefork) -- ******* ---- --- ***** ----- [queues] -------------- .> machine2 exchange=machine2(direct) key=machine2 [tasks] . myapp.agent.add . myapp.agent.getl . myapp.agent.mul . myapp.agent.writefile . myapp.agent.xsum [2015-10-18 15:08:52,114: INFO/MainProcess] Connected to amqp://guest:**@172.16.77.175:5672// [2015-10-18 15:08:52,144: INFO/MainProcess] mingle: searching for neighbors [2015-10-18 15:08:53,174: INFO/MainProcess] mingle: sync with 1 nodes [2015-10-18 15:08:53,176: INFO/MainProcess] mingle: sync complete [2015-10-18 15:08:53,227: WARNING/MainProcess] [email protected] ready.
在任务发布节点发布一个计算任务给docker1:
root@workgroup0:~/celeryapp# ls
default.etcd hots.sh hotswap.py myapp myapp1tmp people.db resp sora test.py
root@workgroup0:~/celeryapp# python
Python 2.7.6 (default, Mar 22 2014, 22:59:56)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> from myapp.agent import add
>>> res = add.apply_async(args=[122,34],queue='machine1',routing_key='machine1')
>>> res.get()
{u'value': u'156', u'node_name': u'docker1'}
用get()可以看到来自docker1的返回,再看看docker1的显示:
[2015-10-18 15:11:51,217: INFO/MainProcess] Task myapp.agent.add[c487a9a2-e5cc-462b-a131-784b363a1952] succeeded in 0.03602907s: {'value': '156', 'node_name': 'docker1'}
至于docker2,一点没动:
[2015-10-18 15:08:53,176: INFO/MainProcess] mingle: sync complete [2015-10-18 15:08:53,227: WARNING/MainProcess] [email protected] ready.
发布一个任务给docker2:
>>> res = add.apply_async(args=[1440,900],queue='machine2',routing_key='machine2')
>>> res.get()
{u'value': u'2340', u'node_name': u'docker2'}
>>>
因为在配置文件中已经定义好了默认的exchange,因此只需指定queue和routing key即可把任务发到指定的节点上。但是这样的架构不容易增删节点(我的项目就是如此),我还是研究了一个使用actor模型+etcd任务持久化的架构开发Sora。
总结:这样一来,就可以实现集群的管理。但是任务发布节点必须维护一个queue与routing key的记录,以便指定集群中的节点执行任务。建议根据情况改变exchange的设置,节点多的时候不应该只用一个default exchange。