深入了解MySQL 5.5分区功能增强
Oracle在并购Sun后对于MySQL的态度令人寻味。在新发布的MySQL 5.5中带来了许多增强的功能,在这篇文章中,我们将解释一下MySQL 5.5分区功能的增强特性。
MySQL 5.5的发布带来了许多增强的功能,虽然已经报道了很多增强功能,如半同步复制,但大家却忽略了分区方面的增强,有时甚至还对其真正意义产生了误解,在这篇文章中,我们希望解释一下这些很酷的增强,特别是我们大多数人还没有完全理解的地方。51CTO向您推荐《MySQL数据库入门与精通教程》。

图 1 大家还没注意到我MySQL的分区功能也很强了哦
非整数列分区
任何使用过分区的人应该都遇到过不少问题,特别是面对非整数列分区时,MySQL 5.1只能处理整数列分区,如果你想在日期或字符串列上进行分区,你不得不使用函数对其进行转换。
MySQL 5.5中新增了两类分区方法,RANG和LIST分区法,同时在新的函数中增加了一个COLUMNS关键词。我们假设有这样一个表:
CREATE TABLE expenses ( expense_date DATE NOT NULL, category VARCHAR(30), amount DECIMAL (10,3) );
如果你想使用MySQL 5.1中的分区类型,那你必须将类型转换成整数,需要使用一个额外的查找表,到了MySQL 5.5中,你可以不用再进行类型转换了,如:
ALTER TABLE expenses PARTITION BY LIST COLUMNS (category) ( PARTITION p01 VALUES IN ( 'lodging', 'food'), PARTITION p02 VALUES IN ( 'flights', 'ground transportation'), PARTITION p03 VALUES IN ( 'leisure', 'customer entertainment'), PARTITION p04 VALUES IN ( 'communications'), PARTITION p05 VALUES IN ( 'fees') );
这样的分区语句除了更加易读外,对数据的组织和管理也非常清晰,上面的例子只对category列进行分区。
在MySQL 5.1中使用分区另一个让人头痛的问题是date类型(即日期列),你不能直接使用它们,必须使用YEAR或TO_DAYS转换这些列,如:
/* 在MySQL 5.1中*/
CREATE TABLE t2
(
dt DATE
)
PARTITION BY RANGE (TO_DAYS(dt))
(
PARTITION p01 VALUES LESS THAN (TO_DAYS('2007-01-01')),
PARTITION p02 VALUES LESS THAN (TO_DAYS('2008-01-01')),
PARTITION p03 VALUES LESS THAN (TO_DAYS('2009-01-01')),
PARTITION p04 VALUES LESS THAN (MAXVALUE));
SHOW CREATE TABLE t2 \G
*************************** 1. row ***************************
Table: t2
Create Table: CREATE TABLE `t2` (
`dt` date DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=latin1
/*!50100 PARTITION BY RANGE (TO_DAYS(dt))
(PARTITION p01 VALUES LESS THAN (733042) ENGINE = MyISAM,
PARTITION p02 VALUES LESS THAN (733407) ENGINE = MyISAM,
PARTITION p03 VALUES LESS THAN (733773) ENGINE = MyISAM,
PARTITION p04 VALUES LESS THAN MAXVALUE ENGINE = MyISAM) */
看上去非常糟糕,当然也有变通办法,但麻烦确实不少。使用YEAR或TO_DAYS定义一个分区的确让人费解,查询时不得不使用赤裸列,因为加了函数的查询不能识别分区。
但在MySQL 5.5中情况发生了很大的变化,现在在日期列上可以直接分区,并且方法也很简单。
/*在MySQL 5.5中*/
CREATE TABLE t2
(
dt DATE
)
PARTITION BY RANGE COLUMNS (dt)
(
PARTITION p01 VALUES LESS THAN ('2007-01-01'),
PARTITION p02 VALUES LESS THAN ('2008-01-01'),
PARTITION p03 VALUES LESS THAN ('2009-01-01'),
PARTITION p04 VALUES LESS THAN (MAXVALUE));
SHOW CREATE TABLE t2 \G
*************************** 1. row ***************************
Table: t2
Create Table: CREATE TABLE `t2` (
`dt` date DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=latin1
/*!50500 PARTITION BY RANGE COLUMNS(dt)
(PARTITION p01 VALUES LESS THAN ('2007-01-01') ENGINE = MyISAM,
PARTITION p02 VALUES LESS THAN ('2008-01-01') ENGINE = MyISAM,
PARTITION p03 VALUES LESS THAN ('2009-01-01') ENGINE = MyISAM,
PARTITION p04 VALUES LESS THAN (MAXVALUE) ENGINE = MyISAM) */
在这里,通过函数定义和通过列查询之间没有冲突,因为是按列定义的,我们在定义中插入的值是保留的。
多列分区
COLUMNS关键字现在允许字符串和日期列作为分区定义列,同时还允许使用多个列定义一个分区,你可能在官方文档中已经看到了一些例子,如:
CREATE TABLE p1 ( a INT, b INT, c INT ) PARTITION BY RANGE COLUMNS (a,b) ( PARTITION p01 VALUES LESS THAN (10,20), PARTITION p02 VALUES LESS THAN (20,30), PARTITION p03 VALUES LESS THAN (30,40), PARTITION p04 VALUES LESS THAN (40,MAXVALUE), PARTITION p05 VALUES LESS THAN (MAXVALUE,MAXVALUE) ); CREATE TABLE p2 ( a INT, b INT, c INT ) PARTITION BY RANGE COLUMNS (a,b) ( PARTITION p01 VALUES LESS THAN (10,10), PARTITION p02 VALUES LESS THAN (10,20), PARTITION p03 VALUES LESS THAN (10,30), PARTITION p04 VALUES LESS THAN (10,MAXVALUE), PARTITION p05 VALUES LESS THAN (MAXVALUE,MAXVALUE) )
同样还有PARTITION BY RANGE COLUMNS (a,b,c)等其它例子。由于我很长时间都在使用MySQL 5.1的分区,我对多列分区的含义不太了解,LESS THAN (10,10)是什么意思?如果下一个分区是LESS THAN (10,20)会发生什么?相反,如果是(20,30)又会如何?
所有这些问题都需要一个答案,在回答之前,他们需要更好地理解我们在做什么。
开始时可能有些混乱,当所有分区有一个不同范围的值时,实际上,它只是在表的一个列上进行了分区,但事实并非如此,在下面的例子中:
CREATE TABLE p1_single ( a INT, b INT, c INT ) PARTITION BY RANGE COLUMNS (a) ( PARTITION p01 VALUES LESS THAN (10), PARTITION p02 VALUES LESS THAN (20), PARTITION p03 VALUES LESS THAN (30), PARTITION p04 VALUES LESS THAN (40), PARTITION p05 VALUES LESS THAN (MAXVALUE) );
它和前面的表p1不一样,如果你在表p1中插入(10,1,1),它将会进入第一个分区,相反,在表p1_single中,它将会进入第二个分区,其原因是(10,1)小于(10,10),如果你仅仅关注第一个值,你还没有意识到你在比较一个元组,而不是一个单一的值。
现在我们来分析一下最难懂的地方,当你需要确定某一行应该放在哪里时会发生什么?你是如何确定类似(10,9) < (10,10)这种运算的值的?答案其实很简单,当你对它们进行排序时,使用相同的方法计算两条记录的值。
a=10 b=9 (a,b) < (10,10) ? # evaluates to: (a < 10) OR ((a = 10) AND ( b < 10)) # which translates to: (10 < 10) OR ((10 = 10) AND ( 9 < 10))
如果有三列,表达式会更长,但不会更复杂。你首先在第一个项目上测试小于运算,如果有两个或更多的分区与之匹配,接着就测试第二个项目,如果不止一个候选分区,那还需要测试第三个项目。
下图所显示的内容表示将遍历三条记录插入到使用以下代码定义的分区中:
(10,10),
(10,20),
(10,30),
(10, MAXVALUE)
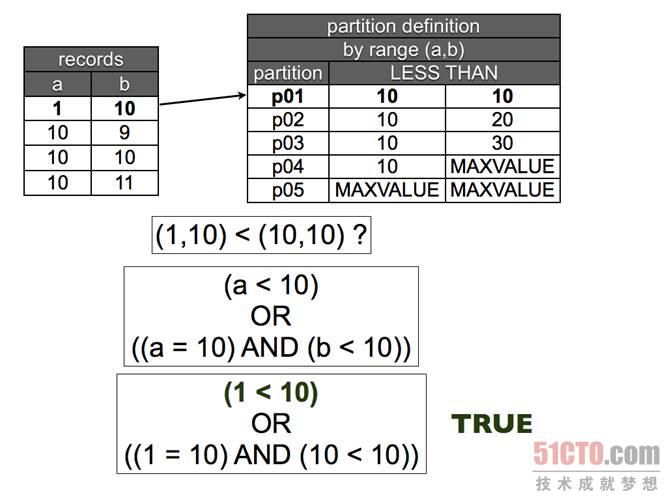
图 2 元组比较。当第一个值小于分区定义的第一个范围时,那么该行将属于这里了。
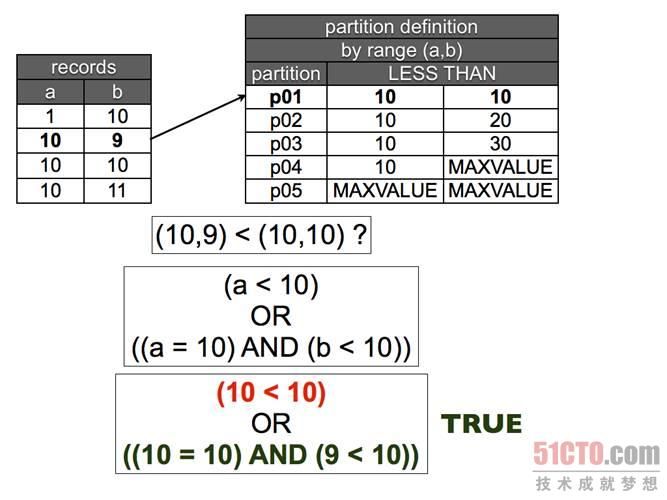
图 3 元组比较。当第一个值等于分区定义的第一个范围,我们需要比较第二个项目,如果它小于第二个范围,那么该行将属于这里了。
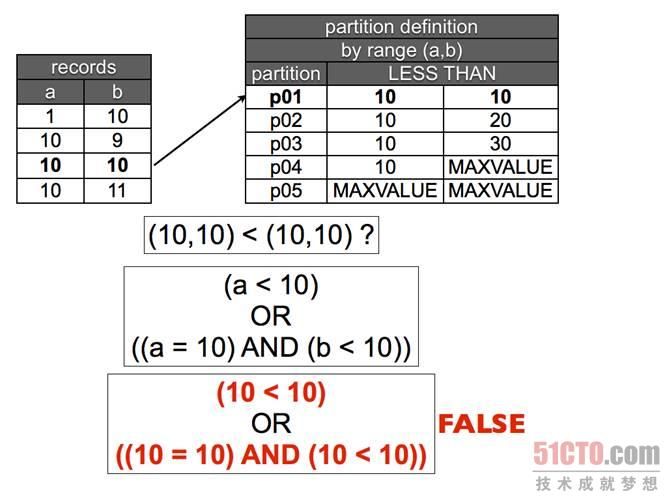
图 4 元组比较。当第一个值和第二个值等于他们对应的范围时,如果元组不小于定义的范围,那么它就不属于这里,继续下一步。
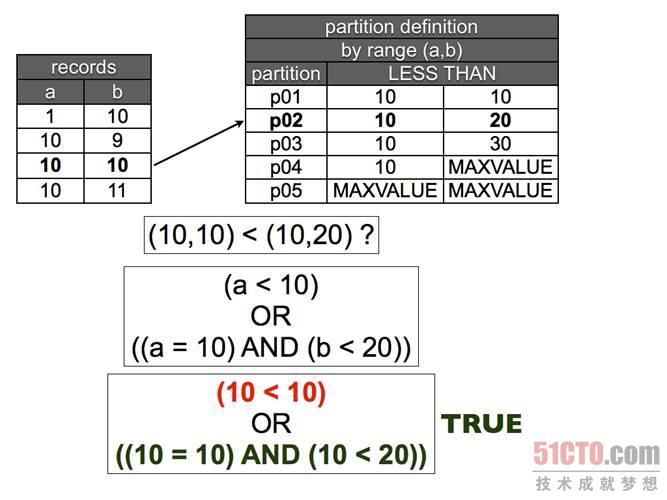
图 5 元组比较。在下一个范围时,第一个项目是等于,第二个项目是小于,因此元组更小,那么该行就属于这里了。
在这些图的帮助下,我们对插入一条记录到多列分区表的步骤有了更深的了解,这些都是理论上的,为了帮助你更好地掌握新功能,我们再来看一个更高级一点的例子,对于比较务实的读者更有意义,下面是表的定义脚本:
CREATE TABLE employees (
emp_no int(11) NOT NULL,
birth_date date NOT NULL,
first_name varchar(14) NOT NULL,
last_name varchar(16) NOT NULL,
gender char(1) DEFAULT NULL,
hire_date date NOT NULL
) ENGINE=MyISAM
PARTITION BY RANGE COLUMNS(gender,hire_date)
(PARTITION p01 VALUES LESS THAN ('F','1990-01-01') ,
PARTITION p02 VALUES LESS THAN ('F','2000-01-01') ,
PARTITION p03 VALUES LESS THAN ('F',MAXVALUE) ,
PARTITION p04 VALUES LESS THAN ('M','1990-01-01') ,
PARTITION p05 VALUES LESS THAN ('M','2000-01-01') ,
PARTITION p06 VALUES LESS THAN ('M',MAXVALUE) ,
PARTITION p07 VALUES LESS THAN (MAXVALUE,MAXVALUE)
和上面的例子不同,这个例子更好理解,第一个分区用来存储雇佣于1990年以前的女职员,第二个分区存储股用于1990-2000年之间的女职员,第三个分区存储所有剩下的女职员。对于分区p04到p06,我们策略是一样的,只不过存储的是男职员。最后一个分区是控制情况。
看完后你可能要问,我怎么知道某一行存储在那个分区中的?有两个办法,第一个办法是使用与分区定义相同的条件作为查询条件进行查询。
SELECT CASE WHEN gender = 'F' AND hire_date < '1990-01-01' THEN 'p1' WHEN gender = 'F' AND hire_date < '2000-01-01' THEN 'p2' WHEN gender = 'F' AND hire_date < '2999-01-01' THEN 'p3' WHEN gender = 'M' AND hire_date < '1990-01-01' THEN 'p4' WHEN gender = 'M' AND hire_date < '2000-01-01' THEN 'p5' WHEN gender = 'M' AND hire_date < '2999-01-01' THEN 'p6' ELSE 'p7' END as p, COUNT(*) AS rows FROM employees GROUP BY p; +------+-------+ | p | rows | +------+-------+ | p1 | 66212 | | p2 | 53832 | | p3 | 7 | | p4 | 98585 | | p5 | 81382 | | p6 | 6 | +------+-------+
如果表是MyISAM或ARCHIVE,你可以信任由INFORMATION_SCHEMA提供的统计信息。
SELECT partition_name part, partition_expression expr, partition_description descr, table_rows FROM INFORMATION_SCHEMA.partitions WHERE TABLE_SCHEMA = schema() AND TABLE_NAME='employees'; +------+------------------+-------------------+------------+ | part | expr | descr | table_rows | +------+------------------+-------------------+------------+ | p01 | gender,hire_date | 'F','1990-01-01' | 66212 | | p02 | gender,hire_date | 'F','2000-01-01' | 53832 | | p03 | gender,hire_date | 'F',MAXVALUE | 7 | | p04 | gender,hire_date | 'M','1990-01-01' | 98585 | | p05 | gender,hire_date | 'M','2000-01-01' | 81382 | | p06 | gender,hire_date | 'M',MAXVALUE | 6 | | p07 | gender,hire_date | MAXVALUE,MAXVALUE | 0 | +------+------------------+-------------------+------------+
如果存储引擎是InnoDB,上面的值就是一个近似值,如果你需要确切的值,那你就不能信任它们。
另一个问题是它的性能,这些增强触发了分区修整吗?答案毫不含糊,是的。与MySQL 5.1有所不同,在5.1中日期分区只能与两个函数工作,在MySQL 5.5中,任何使用了COLUMNS关键字定义的分区都可以使用分区修整,下面还是测试一下吧。
select count(*) from employees where gender='F' and hire_date < '1990-01-01'; +----------+ | count(*) | +----------+ | 66212 | +----------+ 1 row in set (0.05 sec) explain partitions select count(*) from employees where gender='F' and hire_date < '1990-01-01'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: employees partitions: p01 type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 300024 Extra: Using where
使用定义第一个分区的条件,我们获得了一个非常优化的查询,不仅如此,部分条件也将从分区修整中受益。
select count(*) from employees where gender='F'; +----------+ | count(*) | +----------+ | 120051 | +----------+ 1 row in set (0.12 sec) explain partitions select count(*) from employees where gender='F'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: employees partitions: p01,p02,p03,p04 type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 300024 Extra: Using where
它和复合索引的算法一样,如果你的条件指的是索引最左边的部分,MySQL将会使用它。与此类似,如果你的条件指的是分区定义最左边的部分,MySQL将会尽可能修整。它和复合索引一起出现,如果你只使用最右边的条件,分区修整不会工作。
select count(*) from employees where hire_date < '1990-01-01'; +----------+ | count(*) | +----------+ | 164797 | +----------+ 1 row in set (0.18 sec) explain partitions select count(*) from employees where hire_date < '1990-01-01'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: employees partitions: p01,p02,p03,p04,p05,p06,p07 type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 300024 Extra: Using where
如果不用分区定义的第一部分,使用分区定义的第二部分,那么将会发生全表扫描,在设计分区和编写查询时要紧记这一条。
可用性增强:truncate分区
分区最吸引人的一个功能是瞬间移除大量记录的能力,DBA都喜欢将历史记录存储到按日期分区的分区表中,这样可以定期删除过时的历史数据,这种方法相当管用,假设第一个分区存储的是最旧的历史记录,那么你可以直接删除第一个分区,然后再在末尾建立一个新分区保存最近的历史记录,这样循环下去就可以实现历史记录的快速清除。
但当你需要移除分区中的部分数据时,事情就不是那么简单了,删除分区没有问题,但如果是清空分区,就很头痛了,要移除分区中的所有数据,但需要保留分区本身,你可以:
使用DELETE语句,但我们知道DELETE语句的性能都很差。
使用DROP PARTITION语句,紧跟着一个EORGANIZE PARTITIONS语句重新创建分区,但这样做比前一个方法的成本要高出许多。
MySQL 5.5引入了TRUNCATE PARTITION,它和DROP PARTITION语句有些类似,但它保留了分区本身,也就是说分区还可以重复利用。TRUNCATE PARTITION应该是DBA工具箱中的必备工具。
更多微调功能:TO_SECONDS
分区增强包有一个新的函数处理DATE和DATETIME列,使用TO_SECONDS函数,你可以将日期/时间列转换成自0年以来的秒数,如果你想使用小于1天的间隔进行分区,那么这个函数就可以帮到你。
TO_SECONDS会触发分区修整,与TO_DAYS不同,它可以反过来使用,就是FROM_DAYS,对于TO_SECONDS就没有这样的反向函数了,但要自己动手DIY一个也不是难事。
drop function if exists from_seconds; delimiter // create function from_seconds (secs bigint) returns DATETIME begin declare days INT; declare secs_per_day INT; DECLARE ZH INT; DECLARE ZM INT; DECLARE ZS INT; set secs_per_day = 60 * 60 * 24; set days = floor(secs / secs_per_day); set secs = secs - (secs_per_day * days); set ZH = floor(secs / 3600); set ZM = floor(secs / 60) - ZH * 60; set ZS = secs - (ZH * 3600 + ZM * 60); return CAST(CONCAT(FROM_DAYS(days), ' ', ZH, ':', ZM, ':', ZS) as DATETIME); end // delimiter ;
有了这些新武器,我们可以有把握地创建一个小于1天的临时分区,如:
CREATE TABLE t2 (
dt datetime
)
PARTITION BY RANGE (to_seconds(dt))
(
PARTITION p01 VALUES LESS THAN (to_seconds('2009-11-30 08:00:00')) ,
PARTITION p02 VALUES LESS THAN (to_seconds('2009-11-30 16:00:00')) ,
PARTITION p03 VALUES LESS THAN (to_seconds('2009-12-01 00:00:00')) ,
PARTITION p04 VALUES LESS THAN (to_seconds('2009-12-01 08:00:00')) ,
PARTITION p05 VALUES LESS THAN (to_seconds('2009-12-01 16:00:00')) ,
PARTITION p06 VALUES LESS THAN (MAXVALUE)
);
show create table t2\G
*************************** 1. row ***************************
Table: t2
Create Table: CREATE TABLE `t2` (
`dt` datetime DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=latin1
/*!50500 PARTITION BY RANGE (to_seconds(dt))
(PARTITION p01 VALUES LESS THAN (63426787200) ENGINE = MyISAM,
PARTITION p02 VALUES LESS THAN (63426816000) ENGINE = MyISAM,
PARTITION p03 VALUES LESS THAN (63426844800) ENGINE = MyISAM,
PARTITION p04 VALUES LESS THAN (63426873600) ENGINE = MyISAM,
PARTITION p05 VALUES LESS THAN (63426902400) ENGINE = MyISAM,
PARTITION p06 VALUES LESS THAN MAXVALUE ENGINE = MyISAM) */
因为我们没有使用COLUMNS关键字,我们也不能使用它,因为它不支持混合列和函数,表定义中的记录值就是TO_SECONDS函数的计算结果。
但我们还是要感谢新的函数,我们可以反推这个值,换算成一个更容易读懂的日期。
select partition_name part, partition_expression expr, from_seconds(partition_description) descr, table_rows FROM INFORMATION_SCHEMA.partitions WHERE TABLE_SCHEMA = 'test' AND TABLE_NAME='t2'; +------+----------------+---------------------+------------+ | part | expr | descr | table_rows | +------+----------------+---------------------+------------+ | p01 | to_seconds(dt) | 2009-11-30 08:00:00 | 0 | | p02 | to_seconds(dt) | 2009-11-30 16:00:00 | 0 | | p03 | to_seconds(dt) | 2009-12-01 00:00:00 | 0 | | p04 | to_seconds(dt) | 2009-12-01 08:00:00 | 0 | | p05 | to_seconds(dt) | 2009-12-01 16:00:00 | 0 | | p06 | to_seconds(dt) | 0000-00-00 00:00:00 | 0 | +------+----------------+---------------------+------------+
总结
MySQL 5.5对分区用户绝对是个好消息,虽然没有提供直接的性能增强的方法(如果你按响应时间评估性能),但更易于使用的增强功能,以及TRUNCATE PARTITION命令都可以为DBA节省大量的时间,有时对最终用户亦如此。
这些增强的功能可能会在下一个里程碑发布时得到更新,最终版本预计会在2010年年中发布,届时所有分区用户都可以尝试一下!
原文出处:http://dev.mysql.com/tech-resources/articles/mysql_55_partitioning.html
原文名:A deep look at MySQL 5.5 partitioning enhancements