KMP子字符串查找算法分析与实现
原创博客,转载请注明http://my.oschina.net/BreathL/blog/137916
子字符串查找,是程序设计的一个基本且普遍的问题。通常情况下子字符串查找不需要特别的设计,一是由于执行的次数不多,二是查找字符串一般也较短,所以不会形成性能的瓶颈;但如果你的程序里有大量的查找或长字符串的子串查找,也许就需要考虑特别的设计已保证程序的效率。
暴力查找算法:
大部分语言默认的子字符串查找都是使用的暴力查找算法,思路很简单,就是逐个取出待查找的字符串的字节,然后依次和被包含的子字符串的字节比较,从以第一个开始,若相等,则各自取下一个继续比较;若不相等,则待查找的字符串回退回去到起始比较处的下一个字节,而子字符串从头开始取,然后以此循环的比较。
可以优化:
它的算法复杂度是 N*M 这个量级的,但有个问题是:当匹配失败后,待查找的字符串回退回去到起始比较处的下一个字节,而子字符串从头开始取时,紧接着的几步比较可能是多余的计算。因为前X已经匹配上了,说明临近X个字节已知了,那就可以根据已知的情况去掉一些重复的比较,这就KMP子字符串查找算法的优化原理。这么说可能有些模糊,举个例子:
带查找字符串: F Y Y Y Y U H N Z Y Y Y Y 目标字符串: F Y Y Y Y M

第1次比较,到M是发现不匹配了,这时我们已经知道了带查找字符串前5个字符是什么,所以通过一定的规律我们可以直接产生第7次比较,去掉第2~第6次的多余的计算,由此提高效率。
Knuth-Morris-Pratt(KMP)子字符串查找算法:
前面已经提到KMP优化的查找的关键点是在,当匹配失败后,根据失败前所匹配的一些信息,回退到最适当的位置进行后续的匹配。KMP算法给出的方案是:1. 待查找字符串,不回退,继续取Next进行匹配。[暴力算法:回退起始匹配的Next]
2. 包含的字符串,根据当前这个不匹配字节,来确定,回退带那个字节。[暴力算法:回退到开始字节]
为了更好的实现上述优化的逻辑,KMP子字符串算法的整个设计思路如下:
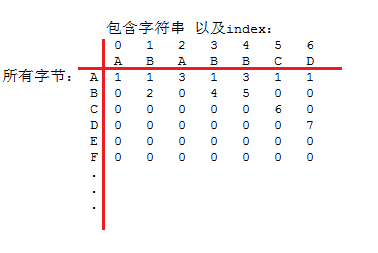
1. 通过包含字符串,构造出一个二维的字典,两个key对应一个值,这两个key:1是对应所有的字节c,2是对应包含字符串字节位置(index);而值是下一个要去比较的包含字符串中字节的位置。
2. 查找字符串,逐个取出字节,放到上述构建的那个二维字典中;取出的字节对应到第一个key,第二个key是包含字符串的index,初始时是0。这样就得到下一个包含字符串中需要比较的字节的位置;用这个位置更新第二个Key,同时取出查找字符串的Next 更新第一个Key;不断循环。
我记得小时候有玩过一种游戏(记不清名字了),跟这个很像:首选,游戏者选择一堆自己觉得对游戏有利的条件;来到第一个格子,格子里写着:[如果满足XXX条件请直接到第六格、如果满足YYY条件请原地不动,如果满足MMM条件继续前进一格],满足MMM条件的我颠儿颠儿的来到第二格,第二个格子同样写着不同的条件,到哪到哪。跟KMP的思路真是如出一辙;二维字典中的这第一个Key就是那些条件,第二个Key就是你当前所处的格子,值就是要去的下一个格子。我猜算法就是设计者玩这游戏时想出的,绝对是,嗯。
核心-二维字典的构建:
由上述的KMP子字符串查找算法,我们可以清晰的看出只要这个二维字典一旦构造好,其他的逻辑只是通过这个字典去查找,逻辑就比较简单了。构造二维字典的目的也已经明确,存储的是下一次比较的位置。说白了就是一次跳转,这里细说下这个跳转,可分为3种类别,分别实现这3种类别的逻辑,其实也就实现了二维字典的构造逻辑,这样看代码也会很清晰。
1 . 首选,匹配对了,即第一个Key的字符与第二个Key(即包含字符串的index)所对应的字符一样,这时的跳转就是下一个(index=index+1)。
2 . 匹配失败,且无前缀,跳转至起始位置,即index=0。
3 . 匹配失败,有前缀,跳转至前缀结束位置的下一个。
这里所指的前缀,是前缀匹配,定义很简单,这里不细讲了,举个例子吧。

比如上图中,匹配到第五个位置了,即红色箭头的比对,发现不匹配了,于是跳转;由于存在前缀,蓝色方框对,于是 包含字符串 跳转至 蓝框结束后面的那个B 开始下一个的比较(查找字符串始终是往下一个跳转),右图红框是匹配失败后的起始的比较。
二维字典,一般用一个二维数组表示,dfa[][],它构造出来大致可以想象成这么个样子,行是第一个Key,列是第二个Key:
实现:
完整的程序如下(代码来自《算法》第四版):
package com.kmp;
public class KMP {
private String pat;
private int[][] dfa; //二维字典
public KMP(String pat){
this.pat = pat;
int M = pat.length();
int R = 256;
//二维字典的构造
dfa = new int[R][M];
dfa[pat.charAt(0)][0] = 1;
for (int X = 0, j = 1; j< M; j++){
//复制前面某一列的所以跳转,至当前列,这某一列可视为参照列
for( int c = 0; c < R; c++) dfa[c][j] = dfa[c][X];
dfa[pat.charAt(j)][j] = j + 1; //第j个字节,刚好在第j个位置上,说明匹配成功
X = dfa[pat.charAt(j)][X]; //更新参照列的位置
}
}
public int find(String content){
// 查找逻辑,类似游戏
int i, j;
int N = content.length();
int M = pat.length();
for (i = 0, j = 0; i<N && j<M; i++){
j = dfa[pat.charAt(i)][j];
}
if (j == M) return i - M; //找到
else return M;
}
}
在二维字典的构造逻辑里面,有个参照列的思路,它的原理是,一列即第二个Key对应所有字节的跳转值是一种状态,这种状态是可以保存并传递给下面某一列;具体的逻辑可以简单理解为,重复了(即在中间出现了前缀),那么程序里的X,就会产生变化,从而是参照列改变。最开始都是参照第0列的;最后如果不再继续重复(即前缀中断),X又会变回成0,重新用第0列作为参照。