Hadoop CDH4.5 NameNode HA方案实战
本篇实战Hadoop2.0 NameNode的HA方案,采用QJM的自动故障转移方案。
Hadoop集群信息如下(增加了U-7):
192.168.1.10 U-1 Active-NameNode zkfc 192.168.1.20 U-2 DataNode zookeeper journalnode 192.168.1.30 U-3 DataNode zookeeper journalnode 192.168.1.40 U-4 DataNode zookeeper journalnode 192.168.1.50 U-5 DataNode 192.168.1.70 U-7 Standby-NameNode zkfcU-7的系统初始化和之前的机器一样,安装JDK,修改/etc/hosts,设置时钟同步等等。不过因为NameNode要和DataNode进行ssh无密码登陆,所以除了U-1要和DataNode进行无密码登陆外, U-7也要和DataNode进行无密码登陆,以上是基本的配置。由于NameNode、DataNode、zookeeper之前已经在集群中配置完毕,所以本篇只要配置U-7及journalnode。为了信息明确,在各个节点不启动mapreduce相关进程,只操作hdfs。
1 安装journalnode服务(U-2/3/4)
apt-get install hadoop-hdfs-journalnode
2 因为要配置fencing服务,所以需要active和standby节点的hdfs用户可以进行无密码ssh相互登陆,注意必须是hdfs用户
登陆U-1,执行如下命令
#切换到hdfs用户 su - hdfs #生成相关ssh密钥对 ssh-keygen #CDH的hads用户家目录在/var/lib/hadoop-hdfs目录,进入该目录下的.ssh目录 cd /var/lib/hadoop-hdfs/.ssh #拷贝id_rsa.pub到U-7的/var/lib/hadoop-hdfs/.ssh/authorized_keys文件 #注意这时候U-7上面还没有该目录,可以在U-7上面先执行ssh-keygen scp id_rsa.pub hdfs@U-7:/var/lib/hadoop-hdfs/.ssh/authorized_keys
登陆U-7,执行和上面U-1类似的步骤,最终效果就是U-1和U-7的hdfs用户可以无密码ssh相互登陆,要不然zkfc会启动失败。
3 在U-7上创建namenode.dir相关目录
mkdir /data chown hdfs:hadoop /data
4 创建journalnode的edit日志目录(U-2/3/4)
mkdir /jdata chown hdfs:hdfs /jdata5 假如我们的hadoop集群的 NameService ID为mycluster,下面配置core-site.xml(U-1)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster/</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>U-2:2181,U-3:2181,U-4:2181</value>
</property>
</configuration>
6 接着配置hdfs-site.xml(U-1)
<configuration>
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data01,/data02</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- HA Config -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>U-1,U-7</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.U-1</name>
<value>U-1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.U-7</name>
<value>U-7:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.U-1</name>
<value>U-1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.U-7</name>
<value>U-7:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://U-2:8485;U-3:8485;U-4:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/jdata</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/var/lib/hadoop-hdfs/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
7 把U-1上的core-site.xml和hdfs-site.xml文件同步到U-2/3/4/5/7节点的相同目录下
8 安装zkfc服务(U-1/7)
apt-get install hadoop-hdfs-zkfc9 安装完zkfc后,你需要初始化以创建znode,在随便一台NameNode上执行即可(U-1)
su - hdfs hdfs zkfc -formatZK10 如果你是从non-HA模式转换到HA模式,则需要初始化共享edits目录(U-1)
su - hdfs hdfs namenode -initializeSharedEdits11 下面开始启动各个节点的相关进程
1 启动Journal Node(U-2/3/4)
service hadoop-hdfs-journalnode start2 格式化Active NameNode(U-1)
sudo -u hdfs hadoop namenode -format3 如果你是从non-HA模式转换到HA模式,则需要初始化共享edits目录(U-1)
su - hdfs hdfs namenode -initializeSharedEdits
注意:如果你不格式化,则NameNode不会启动成功
4 删除DataNode上的数据(U-2/3/4/5)
rm -fr /data01/* /data02/*
第3步执行完毕后,会创建空的fsimage文件和edit log,以及随机生成的storage ID。DataNode连接到NameNode后会获取到这个storage ID,这样以后就拒绝连接到其他namenode。如果要重新格式化namenode,那么必须删除所有datanode的数据,因为其保护了storage ID信息。因为我们用的是老的集群,之前在DataNode上面存有数据,如果再次重新格式化NameNode,DataNode在启动会失败,所以要删除DataNode上的老数据
注意:如果你本来就是新的集群,则不需要执行以上步骤
5 启动Active NameNode(U-1)
service hadoop-hdfs-namenode start6 初始化S tandby NameNode(U-7)
su - hdfs hdfs namenode -bootstrapStandby
当Active NameNode完成格式化后,StandBy NameNode不能通过相同的方式进行格式化,因为这样会导致出现不一致的namespace id,使得DataNode不能同时与两个NameNode交互。StandBy NameNode需要与Active NameNode同步信息
7 启动Standby NameNode(U-7)
service hadoop-hdfs-namenode start8 启动zookeeper(U-2/3/4)
service zookeeper-server start9 启动ZKFC(U-1/7)
service hadoop-hdfs-zkfc start
10 启动DataNode(U-2/3/4/5)
service hadoop-hdfs-datanode start
12 下面挑选U-1/3/5/7节点,查看都运行了哪些服务

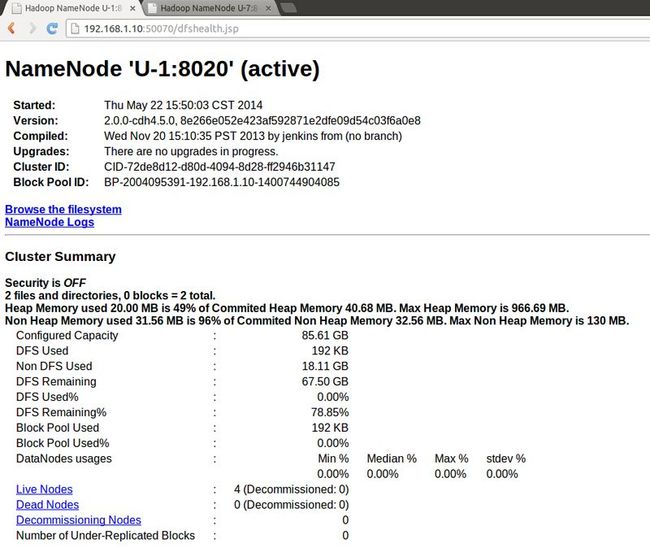
13 查看U-1/7的NameNode各处于什么状态
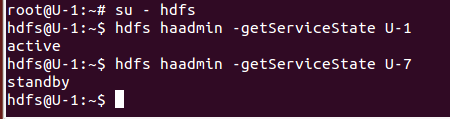
可以看到U-1处于active状态,而U-7处于standby状态
14 模拟一个故障转移

可以看到U-7以及转移到active状态了,U-1进入standby状态。
15 直接kill掉U-7的NameNode,然后看结果
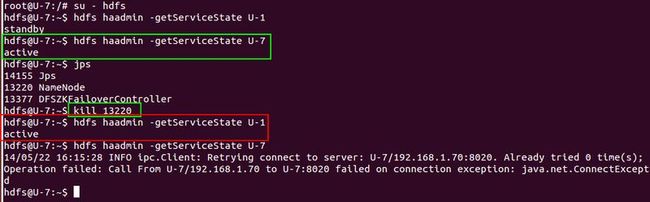
可以看到kill掉U-7的NameNode后,U-1自动转入active状态,而这时也链接不上U-7的NameNode了。也可以在浏览器通过IP:50070查看各个NameNode 的状态。