Heartbeat+DRBD+MySQL高可用方案
1.方案简介
本方案采用Heartbeat双机热备软件来保证数据库的高稳定性和连续性,数据的一致性由DRBD这个工具来保证。默认情况下只有一台mysql 在工作,当主mysql服务器出现问题后,系统将自动切换到备机上继续提供服务,当主数据库修复完毕,又将服务切回继续由主mysql提供服务。
2.方案优缺点
优点:安全性高、稳定性高、可用性高,出现故障自动切换。
缺点:只有一台服务器提供服务,成本相对较高,不方便扩展,可能会发生脑裂。
3.软件介绍
Heartbeat介绍
官方站点:http://linux-ha.org/wiki/Main_Page
heartbeat可以资源(VIP地址及程序服务)从一台有故障的服务器快速的转移到另一台正常的服务器提供服务,heartbeat和keepalived相似,heartbeat可以实现failover功能,但不能实现对后端的健康检查
DRBD介绍
官方站点:http://www.drbd.org/
DRBD(DistributedReplicatedBlockDevice)是一个基于块设备级别在远程服务器直接同步和镜像数据的软件,用软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。它可以实现在网络中两台服务器之间基于块设备级别的实时镜像或同步复制(两台服务器都写入成功)/异步复制(本地服务器写入成功),相当于网络的RAID1,由于是基于块设备(磁盘,LVM逻辑卷),在文件系统的底层,所以数据复制要比cp命令更快。DRBD已经被MySQL官方写入文档手册作为推荐的高可用的方案之一
4.方案拓扑
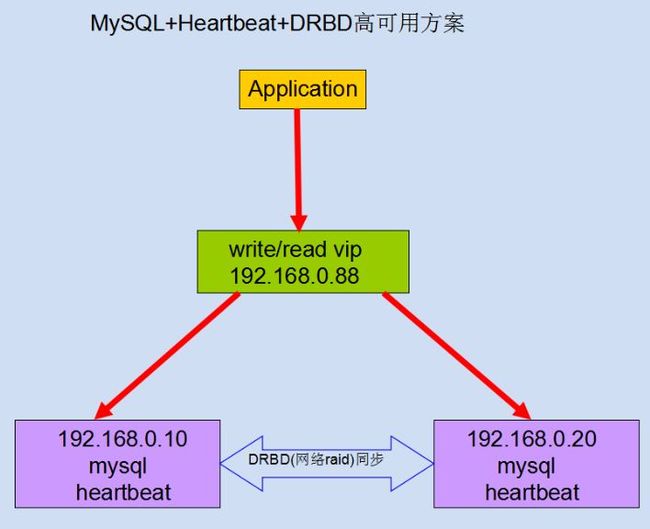
5.方案适用场景:
适用于数据库访问量不太大,短期内访问量增长不会太快,对数据库可用性要求非常高的场景。
6.测试环境介绍(如下所示,均已关闭防火墙及selinux,生产环境自行开放端口)
主机名 ip 系统 DRBD磁盘 heartbeat版本 db-server-01 192.168.0.10 centos6.2 64bit /dev/sda5 3.0.4 db-server-02 192.168.0.20 centos6.2 64bit /dev/sda5 3.0.4
7.软件安装以及环境配置
(1)安装drbd依赖组件(两台机器,安装以后重启系统,因为会升级内核版本,不重启会对不上内核版本,有知道不用重启的童鞋请给我留言^_^):
yum install -y kernel kernel-devel kernel-headers flex
(2)下载软件安装(两台机器操作一样)
wget http://oss.linbit.com/drbd/8.4/drbd-8.4.2.tar.gz
tar xf drbd-8.4.2.tar.gz cd drbd-8.4.2 ./configure --prefix=/usr/local/drbd --with-km make KDIR=/usr/src/kernels/2.6.32-431.11.2.el6.x86_64/ #很多童鞋无法加载drbd模块,多半是正在运行的内核版本和新安装的不相符 make install mkdir -p /usr/local/drbd/var/run/drbd cp /usr/local/drbd/etc/rc.d/init.d/drbd /etc/rc.d/init.d chmod 755 /etc/init.d/drbd cd drbd make clean make KDIR=/usr/src/kernels/2.6.32-431.11.2.el6.x86_64/ cp drbd.ko /lib/modules/`uname -r`/kernel/lib/ modprobe drbd
检查是否加载了drbd模块
[[email protected] ~]# lsmod | grep drbd drbd 314246 0 libcrc32c 1246 1 drbd [[email protected] ~]#
(3)DRBD配置(配置之前需要先使用fdisk对 /dev/sda进行分区)
[[email protected] ~]# df -HT Filesystem Type Size Used Avail Use% Mounted on /dev/sda2 ext4 19G 2.6G 16G 15% / tmpfs tmpfs 121M 0 121M 0% /dev/shm /dev/sda1 ext4 204M 52M 141M 27% /boot /dev/sda5 ext4 34G 185M 32G 1% /data [[email protected] ~]#
我这里两台机器之前都已经分区了,由于是自己笔记本上的虚拟机,所以懒得加磁盘了,我直接把 /data/卸载,然后格式化/dev/sda5,我两台机器都这样操作,如果你有空的磁盘,照样需要进行分区,比如可以将一个1T的盘分一个区就行了。
[[email protected] ~]# umount /data/ [[email protected] ~]# mkfs.ext4 /dev/sda5 mke2fs 1.41.12 (17-May-2010) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 2048000 inodes, 8185344 blocks 409267 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=4294967296 250 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624 Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done This filesystem will be automatically checked every 28 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override. [[email protected] ~]#
[[email protected] ~]# fdisk -l Disk /dev/sda: 53.7 GB, 53687091200 bytes 255 heads, 63 sectors/track, 6527 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x000eb0ff Device Boot Start End Blocks Id System /dev/sda1 * 1 26 204800 83 Linux Partition 1 does not end on cylinder boundary. /dev/sda2 26 2321 18432000 83 Linux /dev/sda3 2321 2451 1048576 82 Linux swap / Solaris /dev/sda4 2451 6528 32742400 5 Extended /dev/sda5 2451 6528 32741376 83 Linux [[email protected] ~]#
我这里还要在/etc/fstab里面注释一项:
#UUID=33958004-e8a7-4135-844f-707a5537e86a /data ext4 defaults 1 2
否则重启机器的时候提示无法挂载,会无法启动的。
修改/etc/hosts文件,两台服务器操作一样。
192.168.0.10 db-server-01 192.168.0.20 db-server-02
drbd配置只需要修改/usr/local/drbd/etc/drbd.d/global_common.conf配置文件即可,修改后如下(两台服务器配置一样):
[[email protected] ~]# cat /usr/local/drbd/etc/drbd.d/global_common.conf global { usage-count yes; } common { syncer { rate 30M; } } #同步速率,视带宽而定 resource r0 { #创建一个资源,名字叫"r0" protocol C; #选择的是drbd的C 协议(数据同步协议,C为收到数据并写入后返回,确认成功) startup { } disk { on-io-error detach; } net { } on db-server-01 { #设定一个节点,分别以各自的主机名命名 device /dev/drbd0; #设定资源设备/dev/drbd0 指向实际的物理分区 /dev/sda5 disk /dev/sda5; address 192.168.0.10:7888; #设定监听地址以及端口 meta-disk internal; } on db-server-02 { device /dev/drbd0; disk /dev/sda5; address 192.168.0.20:7888; meta-disk internal; #internal表示是在同一个局域网内 } } [[email protected] ~]#
(4)DRBD的管理与维护:
创建DRBD资源
配置好drbd以后,就需要使用命令创建配置的drbd资源,使用如下命令(两台服务器操作一样):
[[email protected] ~]# dd if=/dev/zero of=/dev/sda5 bs=1M count=100 #不这样做的话,在创建资源的时候报错 100+0 records in 100+0 records out 104857600 bytes (105 MB) copied, 3.34339 s, 31.4 MB/s [[email protected] ~]#
[[email protected] ~]# drbdadm create-md r0 Writing meta data... initializing activity log NOT initializing bitmap New drbd meta data block successfully created. success [[email protected] ~]#
(5)DRBD的启动与状态查看(分别在两台服务器启动)
[[email protected] ~]# /etc/init.d/drbd start Starting DRBD resources: [ create res: r0 prepare disk: r0 adjust disk: r0 adjust net: r0 ] ..... [[email protected] ~]#
[[email protected] ~]# /etc/init.d/drbd start Starting DRBD resources: [ create res: r0 prepare disk: r0 adjust disk: r0 adjust net: r0 ] . [[email protected] ~]#
查看drbd的状态:
[[email protected] ~]# /etc/init.d/drbd status drbd driver loaded OK; device status: version: 8.4.2 (api:1/proto:86-101) GIT-hash: 7ad5f850d711223713d6dcadc3dd48860321070c build by root@db-server-01, 2014-04-18 21:15:57 m:res cs ro ds p mounted fstype 0:r0 Connected Secondary/Secondary Inconsistent/Inconsistent C [[email protected] ~]#
可以看见都还没有主节点。设置当前节点(192.168.0.10)为主节点,并进行格式化和挂载 。
drbdadm -- --overwrite-data-of-peer primary all mkfs.ext4 /dev/drbd0 mkdir /data mount /dev/drbd0 /data/
在另外一台服务器创建挂载目录,也创建/data
[[email protected] ~]# mkdir /data
查看一下drbd的状态(可以看见还在同步):
[[email protected] ~]# /etc/init.d/drbd status drbd driver loaded OK; device status: version: 8.4.2 (api:1/proto:86-101) GIT-hash: 7ad5f850d711223713d6dcadc3dd48860321070c build by root@db-server-01, 2014-04-18 21:15:57 m:res cs ro ds p mounted fstype ... sync'ed: 13.7% (27596/31972)M 0:r0 SyncSource Primary/Secondary UpToDate/Inconsistent C /data ext4 [[email protected] ~]#
(6)mysql安装,我这里为了简单直接安装编译好的二进制软件包(两台服务器都需要安装,操作一样,只是第二台mysql不需要初始化数据)
注意:两台服务器上的mysql用户的uid和gid要一样。不然切换后会导致mysql数据目录的属主不正确而启动失败。
[[email protected] ~]# wget http://cdn.mysql.com/Downloads/MySQL-5.5/mysql-5.5.37-linux2.6-x86_64.tar.gz
[[email protected] ~]# tar xf mysql-5.5.37-linux2.6-x86_64.tar.gz -C /usr/local/ [[email protected] ~]# cd /usr/local/ [[email protected] local]# ln -s mysql-5.5.37-linux2.6-x86_64/ mysql [[email protected] local]# groupadd mysql [[email protected] local]# useradd -r -g mysql mysql [[email protected] local]# cd mysql [[email protected] mysql]# chown -R mysql . [[email protected] mysql]# chgrp -R mysql . [[email protected] mysql]# mkdir /data/mysql [[email protected] mysql]# chown -R mysql.mysql /data/mysql/ [[email protected] mysql]# /usr/local/mysql/scripts/mysql_install_db --user=mysql --datadir=/data/mysql/ --basedir=/usr/local/mysql
[[email protected] mysql]# chown -R root . [[email protected] mysql]# cp support-files/my-medium.cnf /etc/my.cnf [[email protected] mysql]# cp support-files/mysql.server /etc/init.d/mysqld [[email protected] mysql]# chmod 755 /etc/init.d/mysqld
[[email protected] mysql]# egrep 'datadir|basedir' /etc/my.cnf #两台服务器上的mysql配置文件都加入这里的配置 datadir=/data/mysql basedir=/usr/local/mysql [[email protected] mysql]#
(7)手动切换drbd的主从。看另外一台服务器是否有数据(自动切换需要使用heartbeat,后面介绍):
[[email protected] ~]# ll /data/ total 20 drwx------ 2 root root 16384 Apr 18 22:16 lost+found drwxr-xr-x 5 mysql mysql 4096 Apr 18 23:01 mysql [[email protected] ~]#
[[email protected] ~]# ll /data/ total 0 [[email protected] ~]#
[[email protected] ~]# /etc/init.d/drbd status drbd driver loaded OK; device status: version: 8.4.2 (api:1/proto:86-101) GIT-hash: 7ad5f850d711223713d6dcadc3dd48860321070c build by root@db-server-01, 2014-04-18 21:15:57 m:res cs ro ds p mounted fstype 0:r0 Connected Primary/Secondary UpToDate/UpToDate C /data ext4 [[email protected] ~]#
可以看见当前服务器是主,也就是数据在这台服务器上,另外一台服务器是没有数据的。下面进行手动切换
主切换成从,需要先卸载文件系统,再执行降级为从的命令:
[[email protected] ~]# umount /data/ [[email protected] ~]# drbdadm secondary all
从切换成主,要先执行升级成主的命令然后挂在文件系统:
[[email protected] ~]# drbdadm primary all [[email protected] ~]# mount /dev/drbd0 /data/ [[email protected] ~]# ll /data/ total 20 drwx------ 2 root root 16384 Apr 18 22:16 lost+found drwxr-xr-x 5 mysql mysql 4096 Apr 18 23:01 mysql [[email protected] ~]# /etc/init.d/drbd status drbd driver loaded OK; device status: version: 8.4.2 (api:1/proto:86-101) GIT-hash: 7ad5f850d711223713d6dcadc3dd48860321070c build by root@db-server-02, 2014-04-18 21:22:55 m:res cs ro ds p mounted fstype 0:r0 Connected Primary/Secondary UpToDate/UpToDate C /data ext4 [[email protected] ~]#
可以看见已经成功切换成主,并且mysql初始化数据也存在了。
DRBD脑裂后的处理
当DRBD出现脑裂后,会导致drbd两边的磁盘数据不一致,在确定要作为从的节点上切换成secondary,并放弃该资源的数据:
drbdadm secondary r0 drbdadm -- --discard-my-data connect r0
在要作为primary的节点重新连接secondary(如果这个节点当前的连接状态为WFConnection的话,可以省略),使用如下命令连接:
drbdadm connect r0
(8)Heartbeat安装(两台服务器)
需要添加epel源,centos默认自己没有该软件包,当然你可以自己源码编译。
rpm -ivh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
yum install heartbeat -y
创建DRBD脚本文件drbddisk:(两台服务器)
注意:
此处是一个大坑,因为默认yum安装Heartbeat,不会在 /etc/ha.d/resource.d/创建drbddisk脚本,估计是版本太新了吧。记得前两年都不会这样的。囧。而且也无法在安装后从本地其他 路径找到该文件。此处也是因为启动Heartbeat后无法PING通虚IP,最后通过查看/var/log/ha-log日志,找到一行ERROR: Cannot locate resource script drbddisk,然后进而到/etc/ha.d/resource.d/路径下发现竟然没有drbddisk脚本,最后在google上找到该代码,创 建该脚本,终于测试通过:
[[email protected] ~]# chmod 755 /etc/ha.d/resource.d/drbddisk [[email protected] ~]# cat /etc/ha.d/resource.d/drbddisk #!/bin/bash # # This script is inteded to be used as resource script by heartbeat # # Copright 2003-2008 LINBIT Information Technologies # Philipp Reisner, Lars Ellenberg # ### DEFAULTFILE="/etc/default/drbd" DRBDADM="/sbin/drbdadm" if [ -f $DEFAULTFILE ]; then . $DEFAULTFILE fi if [ "$#" -eq 2 ]; then RES="$1" CMD="$2" else RES="all" CMD="$1" fi ## EXIT CODES # since this is a "legacy heartbeat R1 resource agent" script, # exit codes actually do not matter that much as long as we conform to # http://wiki.linux-ha.org/HeartbeatResourceAgent # but it does not hurt to conform to lsb init-script exit codes, # where we can. # http://refspecs.linux-foundation.org/LSB_3.1.0/ #LSB-Core-generic/LSB-Core-generic/iniscrptact.html #### drbd_set_role_from_proc_drbd() { local out if ! test -e /proc/drbd; then ROLE="Unconfigured" return fi dev=$( $DRBDADM sh-dev $RES ) minor=${dev#/dev/drbd} if [[ $minor = *[!0-9]* ]] ; then # sh-minor is only supported since drbd 8.3.1 minor=$( $DRBDADM sh-minor $RES ) fi if [[ -z $minor ]] || [[ $minor = *[!0-9]* ]] ; then ROLE=Unknown return fi if out=$(sed -ne "/^ *$minor: cs:/ { s/:/ /g; p; q; }" /proc/drbd); then set -- $out ROLE=${5%/**} : ${ROLE:=Unconfigured} # if it does not show up else ROLE=Unknown fi } case "$CMD" in start) # try several times, in case heartbeat deadtime # was smaller than drbd ping time try=6 while true; do $DRBDADM primary $RES && break let "--try" || exit 1 # LSB generic error sleep 1 done ;; stop) # heartbeat (haresources mode) will retry failed stop # for a number of times in addition to this internal retry. try=3 while true; do $DRBDADM secondary $RES && break # We used to lie here, and pretend success for anything != 11, # to avoid the reboot on failed stop recovery for "simple # config errors" and such. But that is incorrect. # Don't lie to your cluster manager. # And don't do config errors... let --try || exit 1 # LSB generic error sleep 1 done ;; status) if [ "$RES" = "all" ]; then echo "A resource name is required for status inquiries." exit 10 fi ST=$( $DRBDADM role $RES ) ROLE=${ST%/**} case $ROLE in Primary|Secondary|Unconfigured) # expected ;; *) # unexpected. whatever... # If we are unsure about the state of a resource, we need to # report it as possibly running, so heartbeat can, after failed # stop, do a recovery by reboot. # drbdsetup may fail for obscure reasons, e.g. if /var/lock/ is # suddenly readonly. So we retry by parsing /proc/drbd. drbd_set_role_from_proc_drbd esac case $ROLE in Primary) echo "running (Primary)" exit 0 # LSB status "service is OK" ;; Secondary|Unconfigured) echo "stopped ($ROLE)" exit 3 # LSB status "service is not running" ;; *) # NOTE the "running" in below message. # this is a "heartbeat" resource script, # the exit code is _ignored_. echo "cannot determine status, may be running ($ROLE)" exit 4 # LSB status "service status is unknown" ;; esac ;; *) echo "Usage: drbddisk [resource] {start|stop|status}" exit 1 ;; esac exit 0 [[email protected] ~]#
(9)heartbeat配置
Hearbeat的配置主要包括三个配置文件,authkeys,ha.cf和haresources的配置,下面就分别来看看:
Authkerys的配置(两台服务器配置一样)
这个文件用来配置密码认证方式,支持3种认证方式,crc,md5和sha1,从左到右安全性越来越高,消耗的资源也越多。因此如果 heartbeat运行在安全的网路之上,比如私网,那么可以将验证方式设置成crc,master和backup的authkeys配置一样。我的 authkeys文件配置如下:
[[email protected] ~]# cat /etc/ha.d/authkeys auth 1 1 crc [[email protected] ~]# chmod 600 /etc/ha.d/authkeys
注意:该文件权限必须是600
ha.cf的配置(两台机器稍微有点区别),Primary(192.168.0.10)如下:
[[email protected] ~]# cat /etc/ha.d/ha.cf logfile /var/log/ha-log #定义Heartbeat的日志名字及位置 logfacility local0 keepalive 2 #设定心跳(监测)时间为2秒 deadtime 15 #设定死亡时间为15秒 ucast eth1 192.168.0.20 #采用单播的方式,IP地址指定为对方IP auto_failback off #当Primary机器发生故障切换到Secondary机器后Primary恢复后是否进行切回操作 (最好是我们有需求手动进行切换) node db-server-01 node db-server-02 [[email protected] ~]#
Secondary(192.168.0.20)如下:
[[email protected] ~]# cat /etc/ha.d/ha.cf logfile /var/log/ha-log #定义Heartbeat的日志名字及位置 logfacility local0 keepalive 2 #设定心跳(监测)时间为2秒 deadtime 15 #设定死亡时间为15秒 ucast eth1 192.168.0.10 #采用单播的方式,IP地址指定为对方IP auto_failback off #当Primary机器发生故障切换到Secondary机器后Primary恢复后是否进行切回操作(一般我们可以看需求,否则不用自动切换) node db-server-01 node db-server-02 [[email protected] ~]#
haresources的配置(两台机器配置一样):
[[email protected] ~]# cat /etc/ha.d/haresources db-server-01 IPaddr::192.168.0.88/24/eth1 drbddisk::r0 Filesystem::/dev/drbd0::/data::ext4 mysqld [[email protected] ~]#
注:该文件内IPaddr,Filesystem等脚本存放路径在 /etc/ha.d/resource.d/下,也可在该目录下存放服务启动脚本(例如:mysqld),将相同脚本名称添到/etc/ha.d /haresources内容中,从而跟随heartbeat启动而启动该脚本。
IPaddr::192.168.0.88/24/eth1:用IPaddr脚本配置浮动VIP
drbddisk::r0:用drbddisk脚本实现DRBD主从节点资源组的挂载和卸载
Filesystem::/dev/drbd0::/data::ext4:用Filesystem脚本实现磁盘挂载和卸载
(10)heartbeat的管理
配置好heartbeat之后,需要将mysql从自启动服务器中去掉,因为主heartbeat启动的时候会挂载drdb文件系统以及启动mysql,切换的时候会将主上的mysql停止并卸载文件系统,从上会挂载文件系统,并启动mysql。因此需要做如下操作(两台服务器):
[[email protected] ~]# chkconfig mysqld off [[email protected] ~]# chkconfig heartbeat off [[email protected] ~]# chkconfig drbd off
[[email protected] ~]# cat /etc/rc.local #!/bin/sh # # This script will be executed *after* all the other init scripts. # You can put your own initialization stuff in here if you don't # want to do the full Sys V style init stuff. touch /var/lock/subsys/local modprobe drbd #必须先加载模块,这也是因为将启动命令放在这里的原因 /etc/init.d/drbd start /etc/init.d/heartbeat start [[email protected] ~]#
到这里heartbeat+drbd+mysql高可用环境就搭建结束了。接下来进行测试。
高可用测试
(1)在第一台服务器上面启动mysql服务。(192.168.0.10)
[[email protected] ~]# /etc/init.d/mysqld start Starting MySQL.The server quit without updating PID file (/[FAILED]ql/db-server-01.pid). [[email protected] ~]# ll /data/ total 0 [[email protected] ~]#
怎么回事?/data/下面为空。这里是因为我们在前面已经把这个节点变为Secondary
[[email protected] ~]# /etc/init.d/drbd status drbd driver loaded OK; device status: version: 8.4.2 (api:1/proto:86-101) GIT-hash: 7ad5f850d711223713d6dcadc3dd48860321070c build by root@db-server-01, 2014-04-18 21:15:57 m:res cs ro ds p mounted fstype 0:r0 Connected Secondary/Primary UpToDate/UpToDate C [[email protected] ~]#
我们现在需要手动切换回来。才能启动mysql
[[email protected] ~]# umount /data/ [[email protected] ~]# drbdadm secondary all [[email protected] ~]#
[[email protected] ~]# drbdadm primary all [[email protected] ~]# mount /dev/drbd0 /data/ [[email protected] ~]# ll /data/ total 20 drwx------ 2 root root 16384 Apr 18 22:16 lost+found drwxr-xr-x 5 mysql mysql 4096 Apr 18 23:01 mysql [[email protected] ~]# /etc/init.d/drbd status drbd driver loaded OK; device status: version: 8.4.2 (api:1/proto:86-101) GIT-hash: 7ad5f850d711223713d6dcadc3dd48860321070c build by root@db-server-01, 2014-04-18 21:15:57 m:res cs ro ds p mounted fstype 0:r0 Connected Primary/Secondary UpToDate/UpToDate C /data ext4 [[email protected] ~]#
可以看见已经切换回来了,我们现在可以启动mysql了。
[[email protected] ~]# /etc/init.d/mysqld start Starting MySQL....... [ OK ] [[email protected] ~]# mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 Server version: 5.5.37-log MySQL Community Server (GPL) Copyright (c) 2000, 2014, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
(2)在两台服务器上面启动heartbeat
[[email protected] ~]# /etc/init.d/heartbeat start Starting High-Availability services: INFO: Resource is stopped Done. [[email protected] ~]#
[[email protected] ~]# /etc/init.d/heartbeat start Starting High-Availability services: INFO: Resource is stopped Done. [[email protected] ~]#
[[email protected] ~]# ip addr | grep eth1 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 inet 192.168.0.10/24 brd 192.168.0.255 scope global eth1 inet 192.168.0.88/24 brd 192.168.0.255 scope global secondary eth1 [[email protected] ~]#
可以看见虚拟ip192.168.0.88已经存在了。说明成功了。我们看看heartbeat的日志就能发现。
[[email protected] ~]# tail -n 20 /var/log/ha-log harc(default)[5598]: 2014/04/19_00:25:21 info: Running /etc/ha.d//rc.d/status status Apr 19 00:25:22 db-server-01 heartbeat: [5591]: info: Comm_now_up(): updating status to active Apr 19 00:25:22 db-server-01 heartbeat: [5591]: info: Local status now set to: 'active' Apr 19 00:25:22 db-server-01 heartbeat: [5591]: info: Status update for node db-server-02: status active harc(default)[5618]: 2014/04/19_00:25:22 info: Running /etc/ha.d//rc.d/status status Apr 19 00:25:33 db-server-01 heartbeat: [5591]: info: remote resource transition completed. Apr 19 00:25:33 db-server-01 heartbeat: [5591]: info: remote resource transition completed. Apr 19 00:25:33 db-server-01 heartbeat: [5591]: info: Initial resource acquisition complete (T_RESOURCES(us)) /usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_192.168.0.88)[5671]: 2014/04/19_00:25:33 INFO: Resource is stopped Apr 19 00:25:33 db-server-01 heartbeat: [5635]: info: Local Resource acquisition completed. harc(default)[5752]: 2014/04/19_00:25:33 info: Running /etc/ha.d//rc.d/ip-request-resp ip-request-resp ip-request-resp(default)[5752]: 2014/04/19_00:25:33 received ip-request-resp IPaddr::192.168.0.88/24/eth1 OK yes ResourceManager(default)[5775]: 2014/04/19_00:25:33 info: Acquiring resource group: db-server-01 IPaddr::192.168.0.88/24/eth1 drbddisk::r0 Filesystem::/dev/drbd0::/data::ext4 mysqld /usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_192.168.0.88)[5803]: 2014/04/19_00:25:33 INFO: Resource is stopped ResourceManager(default)[5775]: 2014/04/19_00:25:33 info: Running /etc/ha.d/resource.d/IPaddr 192.168.0.88/24/eth1 start IPaddr(IPaddr_192.168.0.88)[5926]: 2014/04/19_00:25:34 INFO: Adding inet address 192.168.0.88/24 with broadcast address 192.168.0.255 to device eth1 IPaddr(IPaddr_192.168.0.88)[5926]: 2014/04/19_00:25:34 INFO: Bringing device eth1 up IPaddr(IPaddr_192.168.0.88)[5926]: 2014/04/19_00:25:34 INFO: /usr/libexec/heartbeat/send_arp -i 200 -r 5 -p /var/run/resource-agents/send_arp-192.168.0.88 eth1 192.168.0.88 auto not_used not_used /usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_192.168.0.88)[5900]: 2014/04/19_00:25:34 INFO: Success /usr/lib/ocf/resource.d//heartbeat/Filesystem(Filesystem_/dev/drbd0)[6030]: 2014/04/19_00:25:34 INFO: Running OK [[email protected] ~]#
激动的时刻到了,我们测试一下自动切换。我们先看看两台服务器的状态:
[[email protected] ~]# df -HT Filesystem Type Size Used Avail Use% Mounted on /dev/sda2 ext4 19G 3.5G 15G 20% / tmpfs tmpfs 121M 0 121M 0% /dev/shm /dev/sda1 ext4 204M 52M 141M 27% /boot /dev/drbd0 ext4 33G 216M 32G 1% /data [[email protected] ~]#
[[email protected] ~]# df -HT Filesystem Type Size Used Avail Use% Mounted on /dev/sda2 ext4 19G 4.9G 13G 28% / tmpfs tmpfs 121M 0 121M 0% /dev/shm /dev/sda1 ext4 204M 52M 141M 27% /boot [[email protected] ~]#
可以看见挂载在第一台服务器。
测试方法:
1.停掉master上的mysqld,看看是否切换(因为heartheat不检查服务的可用性,因此需要通过而外的脚本来实现)。
2.停掉master的heartheat看看是否能正常切换。
3.停掉master的网络或者直接将master系统shutdown,看看能否正常切换。
4.启动master的heartbeat看看是否能正常切换回来。
5.重新启动master看看能否切换过程是否OK。
注意:这里说的切换是不是已经将mysql停掉、是否卸载了文件系统等等。
我就停止master(192.168.0.10)上的heartbeat来测试是否会自动切换,这里除了第一条无法实现,其他的都可以切换:
[[email protected] ~]# /etc/init.d/heartbeat stop Stopping High-Availability services: Done.
[[email protected] ~]# df -HT Filesystem Type Size Used Avail Use% Mounted on /dev/sda2 ext4 19G 3.5G 15G 20% / tmpfs tmpfs 121M 0 121M 0% /dev/shm /dev/sda1 ext4 204M 52M 141M 27% /boot [[email protected] ~]# /etc/init.d/drbd status drbd driver loaded OK; device status: version: 8.4.2 (api:1/proto:86-101) GIT-hash: 7ad5f850d711223713d6dcadc3dd48860321070c build by root@db-server-01, 2014-04-18 21:15:57 m:res cs ro ds p mounted fstype 0:r0 Connected Secondary/Primary UpToDate/UpToDate C [[email protected] ~]#
可以看见已经切换了,我们看另外一台机器的情况:
[[email protected] ~]# df -HT Filesystem Type Size Used Avail Use% Mounted on /dev/sda2 ext4 19G 4.9G 13G 28% / tmpfs tmpfs 121M 0 121M 0% /dev/shm /dev/sda1 ext4 204M 52M 141M 27% /boot /dev/drbd0 ext4 33G 216M 32G 1% /data [[email protected] ~]# netstat -nltp | grep 3306 | grep -v grep tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 5542/mysqld [[email protected] ~]#
可以发现已经切换过来,mysql也自动启动了。之前是没有启动的。
[[email protected] ~]# ip addr | grep eth1 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 inet 192.168.0.20/24 brd 192.168.0.255 scope global eth1 inet 192.168.0.88/24 brd 192.168.0.255 scope global secondary eth1 [[email protected] ~]# mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 Server version: 5.5.37-log MySQL Community Server (GPL) Copyright (c) 2000, 2014, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
可以看见,一切正常呢。如果我们查看日志,就可以看见到底发生了什么。
[[email protected] ~]# tail -n 10 /var/log/ha-log ResourceManager(default)[4768]: 2014/04/19_00:36:42 info: Running /etc/ha.d/resource.d/Filesystem /dev/drbd0 /data ext4 start Filesystem(Filesystem_/dev/drbd0)[5131]: 2014/04/19_00:36:42 INFO: Running start for /dev/drbd0 on /data /usr/lib/ocf/resource.d//heartbeat/Filesystem(Filesystem_/dev/drbd0)[5122]: 2014/04/19_00:36:42 INFO: Success ResourceManager(default)[4768]: 2014/04/19_00:36:43 info: Running /etc/init.d/mysqld start mach_down(default)[4741]: 2014/04/19_00:36:46 info: /usr/share/heartbeat/mach_down: nice_failback: foreign resources acquired mach_down(default)[4741]: 2014/04/19_00:36:46 info: mach_down takeover complete for node db-server-01. Apr 19 00:36:46 db-server-02 heartbeat: [4637]: info: mach_down takeover complete. Apr 19 00:36:58 db-server-02 heartbeat: [4637]: WARN: node db-server-01: is dead Apr 19 00:36:58 db-server-02 heartbeat: [4637]: info: Dead node db-server-01 gave up resources. Apr 19 00:36:58 db-server-02 heartbeat: [4637]: info: Link db-server-01:eth1 dead. [[email protected] ~]#
对于mysqld服务挂掉的情况无法实现自动切换,所以需要一个脚本来帮助我们完成,我这里有个简单的脚本,能实现当mysqld服务不可用时进行自动切换,当进行切换时发送邮件等。该脚本放在主服务器执行,也就是运行mysqld服务的服务器上执行。
[[email protected] ~]# cat mysqlmon.sh #!/bin/bash trap 'echo PROGRAM INTERRUPTED; exit 1' INT username=root password=123456 n=0 log='/var/log/mysqlmon.log' while true do if /usr/local/mysql/bin/mysql -u${username} -p${password} -e "use test" >&/dev/null then echo `date +"%Y-%m-%d %H:%M:%S"` mysqld is alive! >> ${log} n=0 else echo "`date +"%Y-%m-%d %H:%M:%S"` mysqld cannot be connected!" >> ${log} n=$[n + 1] if [ $n -eq 3 ] then /etc/init.d/heartbeat stop echo "`date +"%Y-%m-%d %H:%M:%S"` mysqld switched to backup!" >> ${log} echo "`date +"%Y-%m-%d %H:%M:%S"` mysqld switched to backup" | mutt -s "mysqld switched to backup" [email protected] break fi fi sleep 10 done [[email protected] ~]#
挂在后台执行:
[[email protected] ~]# nohup mysqlmon.sh &
停止mysqld服务,看是否进行切换以及发送邮件:
[[email protected] ~]# /etc/init.d/mysqld stop Shutting down MySQL. [ OK ] [[email protected] ~]#
[[email protected] ~]# df -HT Filesystem Type Size Used Avail Use% Mounted on /dev/sda2 ext4 19G 4.9G 13G 28% / tmpfs tmpfs 121M 0 121M 0% /dev/shm /dev/sda1 ext4 204M 52M 141M 27% /boot /dev/drbd0 ext4 33G 216M 32G 1% /data [[email protected] ~]# netstat -nltp | grep 3306 tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 13771/mysqld [[email protected] ~]#
总结:
搭建还不算复杂,但是也踩了不少坑,比如yum安装的heartbeat没有drbddisk脚本。该方案的优点是安全性高、稳定性高、可用性高,出现故障自动切换,但是缺点也很明显,只有一台服务器提供服务,成本相对较高。不方便扩展。可能会发生脑裂。当mysql服务挂掉或者不可用的情况下不能进行自动切换,需要通过crm模式实现或者额外的脚本实现(比如shell脚本监测到master的mysql不可用就将主上的heartbeat停掉,这样就会切换到backup中去)。监控也特别重要,可以使用nagios或者zabbix监控。