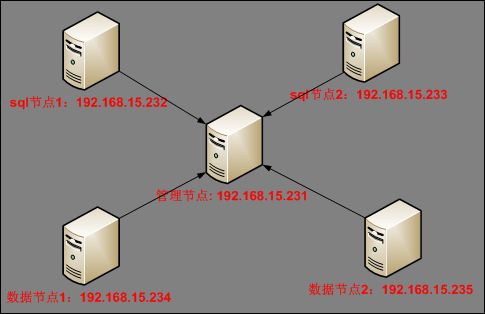
MySQL日志管理
一、日志类型:
MySQL有几个不同的日志文件,可以帮助你找出mysqld内部发生的事情:
| 日志文件 | 记入文件中的信息类型 |
| 错误日志 | 记录启动、运行或停止时出现的问题。 |
| 查询日志 | 记录建立的客户端连接和执行的语句。 |
| 二进制日志 | 记录所有更改数据的语句。主要用于复制和即时点恢复。 |
| 慢日志 | 记录所有执行时间超过long_query_time秒的所有查询或不使用索引的查询。 |
| 事务日志 | 记录InnoDB等支持事务的存储引擎执行事务时产生的日志。 |
默认情况下,所有日志创建于mysqld数据目录中。通过刷新日志,你可以强制 mysqld来关闭和重新打开日志文件(或者在某些情况下切换到一个新的日志)。当你执行一个FLUSH LOGS语句或执行mysqladmin flush-logs或mysqladmin refresh时,出现日志刷新。如果你正使用MySQL复制功能,从复制服务器将维护更多日志文件,被称为接替日志。
二、错误日志:
错误日志主要记录如下几种日志:
- 服务器启动和关闭过程中的信息
- 服务器运行过程中的错误信息
- 事件调度器运行一个时间是产生的信息
- 在从服务器上启动从服务器进程是产生的信息
错误日志定义:
可以用--log-error[=file_name]选项来指定mysqld保存错误日志文件的位置。如果没有给定file_name值,mysqld使用错误日志名host_name.err 并在数据目录中写入日志文件。如果你执行FLUSH LOGS,错误日志用-old重新命名后缀并且mysqld创建一个新的空日志文件。(如果未给出--log-error选项,则不会重新命名)。
查看当前错误日志配置:
mysql> SHOW GLOBAL VARIABLES LIKE '%log_error%';
+---------------+---------------------------------------+
| Variable_name | Value |
+---------------+---------------------------------------+
| log_error | /data/mysql/localhost.localdomain.err |
+---------------+---------------------------------------+
1 row in set (0.45 sec)
是否记录警告日志:
mysql> SHOW GLOBAL VARIABLES LIKE '%log_warnings%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_warnings | 1 |
+---------------+-------+
1 row in set (0.00 sec)
三、通用查询日志
- 启动开关:general_log={ON|OFF}
- 日志文件变量:general_log_file[=/PATH/TO/file]
- 全局日志开关:log={ON|OFF} 该开关打开后,所有日志都会被启用
- 记录类型:log_output={TABLE|FILE|NONE}
因此,要启用通用查询日志,需要至少配置general_log=ON,log_output={TABLE|FILE}。而general_log_file如果没有指定,默认名是host_name.log。
看看上述几个值的默认配置:
mysql> SHOW GLOBAL VARIABLES LIKE '%general_log%';
+------------------+---------------------------+
| Variable_name | Value |
+------------------+---------------------------+
| general_log | OFF |
| general_log_file | /data/mysql/localhost.log |
+------------------+---------------------------+mysql> SHOW GLOBAL VARIABLES LIKE '%log_output%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_output | FILE |
+---------------+-------+
四、慢查询日志:
MySQL如果启用了slow_query_log=ON选项,就会记录执行时间超过long_query_time的查询(初使表锁定的时间不算作执行时间)。日志记录文件为slow_query_log_file[=file_name],如果没有给出file_name值, 默认为主机名,后缀为-slow.log。如果给出了文件名,但不是绝对路径名,文件则写入数据目录。
默认与慢查询相关变量:
mysql> SHOW GLOBAL VARIABLES LIKE '%slow_query_log%';
+----------------------------+--------------------------------+
| Variable_name | Value |
+----------------------------+--------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | /data/mysql/localhost-slow.log |
+----------------------------+--------------------------------+
服务器参数设定方法与通用查询日志相同,不做解释。
默认没有启用慢查询,为了服务器调优,建议开启。
mysql> SET GLOBAL slow_query_log=ON;
Query OK, 0 rows affected (1.45 sec)##如果要长久生效,则需要在配置文件中定义。
那么多久算是慢呢?
如果查询时长超过long_query_time的定义值(默认10秒),即为慢查询:
mysql> SHOW GLOBAL VARIABLES LIKE 'long_query_time';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
五、二进制日志:
二进制日志启动开关:log-bin [= file_name]
在5.6及以上版本一定要手动指定。5.6以下版本默认file_name为$datadir/mysqld-binlog
二进制日志用于记录所有更改数据的语句。主要用于复制和即时点恢复。
查看二进制日志的工具为:mysqlbinlog
二进制日志包含了所有更新了数据或者已经潜在更新了数据(例如,没有匹配任何行的一个DELETE)的所有语句。语句以“事件”的形式保存,它描述数据更改。二进制日志还包含关于每个更新数据库的语句的执行时间信息。它不包含没有修改任何数据的语句。
二进制日志的主要目的是在数据库存在故障时,恢复时能够最大可能地更新数据库(即时点恢复),因为二进制日志包含备份后进行的所有更新。二进制日志还用于在主复制服务器上记录所有将发送给从服务器的语句。
那么二进制日志是记录执行的语句还是执行后的结果数据呢?
第一种情况:
加入一个表有10万行数据,而现在要执行一个如下语句将amount字段的值全部在原来的基础上增加1000:
UPDATE sales.january SET amount=amount+1000;
此时如果要记录执行后的结果数据的话,日志会非常大。
因此在这种情况下应记录执行语句。这种方式就是基于语句的二进制日志。
第二种情况:
如果向某个字段插入的是当前的时间呢?如下:
INSERT INTO tb SET Birthdate=CURRENT_TIME();
此时就不能记录语句了,因为不同时间执行的结果是不一样的。这是应该记录这一行的值,这种就是基于行(row)的二进制日志。
在有些情况,可能会结合两种方式来记录,这种叫做混合方式的二进制日志。
二进制日志记录时间:
默认情况下,并不是每次写入时都将二进制日志与硬盘同步。因此如果操作系统或机器(不仅仅是MySQL服务器)崩溃,有可能二进制日志中最后的语句丢失了。要想防止这种情况,你可以使用sync_binlog全局变量(1是最安全的值,但也是最慢的),使二进制日志在每N次二进制日志写入后与硬盘同步。
对非事务表的更新执行完毕后立即保存到二进制日志中。对于事务表,例如BDB或InnoDB表,所有更改表的更新(UPDATE、DELETE或INSERT) 被缓存起来,直到服务器接收到COMMIT语句。在该点,执行完COMMIT之前,mysqld将整个事务写入二进制日志。当处理事务的线程启动时,它为缓冲查询分配binlog_cache_size大小的内存。如果语句大于该值,线程则打开临时文件来保存事务。线程结束后临时文件被删除。
二进制日志的管理:
- 日志的滚动:
在my.cnf中设定max_binlog_size = 200M,表示限制二进制日志最大尺寸为200M,超过200M后进行滚动。MySQL的滚动方式与其他日志不太一样,滚动时会创建一个新的编号大1的日志用于记录最新的日志,而原日志名字不会被改变。
每次重启MySQL服务,日志都会自动滚动一次。
另外如果需要手动滚动,则使用命令:
mysql> FLUSH LOGS;
- 日志的查看:
查看有哪些二进制日志文件:
mysql> SHOW BINARY LOGS;
+----------------------+-----------+
| Log_name | File_size |
+----------------------+-----------+
| mysqld-binlog.000001 | 143 |
| mysqld-binlog.000002 | 120 |
+----------------------+-----------+
查看当前正在使用的是哪一个二进制日志文件:
mysql> SHOW MASTER STATUS;
+----------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+----------------------+----------+--------------+------------------+-------------------+
| mysqld-binlog.000002 | 120 | | | |
+----------------------+----------+--------------+------------------+-------------------+##做个操作后再次查看:
mysql> use jiaowu;
Database changed
mysql> INSERT INTO students (Name,Age) VALUES ('stu1',24);
Query OK, 1 row affected (0.07 sec)mysql> SHOW MASTER STATUS;
+----------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+----------------------+----------+--------------+------------------+-------------------+
| mysqld-binlog.000002 | 394 | | | |
+----------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)##可以看到Position(位置)已经改变。
查看二进制日志内容:
mysql> SHOW BINLOG EVENTS IN 'mysqld-binlog.000002';
+----------------------+-----+-------------+-----------+-------------+------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+----------------------+-----+-------------+-----------+-------------+------------------------------------------------------------------+
| mysqld-binlog.000002 | 4 | Format_desc | 1 | 120 | Server ver: 5.6.13-log, Binlog ver: 4 |
| mysqld-binlog.000002 | 120 | Query | 1 | 203 | BEGIN |
| mysqld-binlog.000002 | 203 | Intvar | 1 | 235 | INSERT_ID=11 |
| mysqld-binlog.000002 | 235 | Query | 1 | 363 | use `jiaowu`; INSERT INTO students (Name,Age) VALUES ('stu1',24) |
| mysqld-binlog.000002 | 363 | Xid | 1 | 394 | COMMIT /* xid=13 */ |
+----------------------+-----+-------------+-----------+-------------+------------------------------------------------------------------+
5 rows in set (0.01 sec)##该语句还可以加上Position(位置),指定显示从哪个Position(位置)开始:
mysql> SHOW BINLOG EVENTS IN 'mysqld-binlog.000002' FROM 203;
+----------------------+-----+------------+-----------+-------------+------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+----------------------+-----+------------+-----------+-------------+------------------------------------------------------------------+
| mysqld-binlog.000002 | 203 | Intvar | 1 | 235 | INSERT_ID=11 |
| mysqld-binlog.000002 | 235 | Query | 1 | 363 | use `jiaowu`; INSERT INTO students (Name,Age) VALUES ('stu1',24) |
| mysqld-binlog.000002 | 363 | Xid | 1 | 394 | COMMIT /* xid=13 */ |
+----------------------+-----+------------+-----------+-------------+------------------------------------------------------------------+
3 rows in set (0.00 sec)
使用命令mysqlbinlog查看二进制日志内容:
基本语法:
mysqlbinlog [options] log-files
常用options(选项):
--start-position :开始位置
--stop-position :结束位置--start-datetime 'yyyy-mm-dd hh:mm:ss' :开始时间
--stop-datetime 'yyyy-mm-dd hh:mm:ss' :结束时间
示例:
[root@localhost mysql]# mysqlbinlog --start-datetime '2013-09-26 23:30:00' mysqld-binlog.000002
[root@localhost mysql]# mysqlbinlog --start-position 203 --stop-position 389 mysqld-binlog.000002
使用二进制日志还原数据:
使用mysqlbinlog读取需要的日志内容,使用标准输入重定向到一个sql文件,然后在mysql服务器上导入即可,如下:
[root@localhost mysql]# mysqlbinlog mysqld-binlog.000002 >/root/temp_date.sql
数据的还原后面博客会详细介绍。
删除二进制日志文件:
二进制日志文件不能直接删除的,如果使用rm等命令直接删除日志文件,可能导致数据库的崩溃。
必须使用命令PURGE删除日志,语法如下:
PURGE { BINARY | MASTER } LOGS
{ TO 'log_name' | BEFORE datetime_expr }
示例:
##查看当前所有日志文件
[root@localhost mysql]# ll mysqld-binlog.0*
-rw-rw----. 1 mysql mysql 445 9月 22 15:13 mysqld-binlog.000002
-rw-rw----. 1 mysql mysql 171 9月 22 15:13 mysqld-binlog.000003
-rw-rw----. 1 mysql mysql 171 9月 22 15:13 mysqld-binlog.000004
-rw-rw----. 1 mysql mysql 171 9月 22 15:13 mysqld-binlog.000005
-rw-rw----. 1 mysql mysql 171 9月 22 15:13 mysqld-binlog.000006
-rw-rw----. 1 mysql mysql 171 9月 22 15:13 mysqld-binlog.000007
-rw-rw----. 1 mysql mysql 120 9月 22 15:13 mysqld-binlog.000008##删除mysqld-binlog.000006以前的日志文件:
mysql> PURGE BINARY LOGS TO 'mysqld-binlog.000006';
Query OK, 0 rows affected (0.02 sec)##查看删除情况:
[root@localhost mysql]# ll mysqld-binlog.0*
-rw-rw----. 1 mysql mysql 171 9月 22 15:13 mysqld-binlog.000006
-rw-rw----. 1 mysql mysql 171 9月 22 15:13 mysqld-binlog.000007
-rw-rw----. 1 mysql mysql 120 9月 22 15:13 mysqld-binlog.000008mysql> SHOW BINARY LOGS;
+----------------------+-----------+
| Log_name | File_size |
+----------------------+-----------+
| mysqld-binlog.000006 | 171 |
| mysqld-binlog.000007 | 171 |
| mysqld-binlog.000008 | 120 |
+----------------------+-----------+
3 rows in set (0.00 sec)
六、MySQL中日志相关常用的服务器变量说明:
expire_logs_days={0..99}
设定二进制日志的过期天数,超出此天数的二进制日志文件将被自动删除。默认为0,表示不启用过期自动删除功能。如果启用此功能,自动删除工作通常发生在MySQL启动时或FLUSH日志时。作用范围为全局,可用于配置文件,属动态变量。
general_log={ON|OFF}
设定是否启用查询日志,默认值为取决于在启动mysqld时是否使用了--general_log选项。如若启用此项,其输出位置则由--log_output选项进行定义,如果log_output的值设定为NONE,即使用启用查询日志,其也不会记录任何日志信息。作用范围为全局,可用于配置文件,属动态变量。
general_log_file=FILE_NAME
查询日志的日志文件名称,默认为“hostname.log"。作用范围为全局,可用于配置文件,属动态变量。
binlog-format={ROW|STATEMENT|MIXED}
指定二进制日志的类型,默认为STATEMENT,建议更改为MIXED。如果设定了二进制日志的格式,却没有启用二进制日志,则MySQL启动时会产生警告日志信息并记录于错误日志中。作用范围为全局或会话,可用于配置文件,且属于动态变量。
log={YES|NO}
是否启用记录所有语句的日志信息于一般查询日志(general query log)中,默认通常为OFF。MySQL 5.6已经弃用此选项。
log-bin={YES|NO}
是否启用二进制日志,如果为mysqld设定了--log-bin选项,则其值为ON,否则则为OFF。其仅用于显示是否启用了二进制日志,并不反应log-bin的设定值。作用范围为全局级别,属非动态变量。
log_bin_trust_function_creators={TRUE|FALSE}
此参数仅在启用二进制日志时有效,用于控制创建存储函数时如果会导致不安全的事件记录二进制日志条件下是否禁止创建存储函数。默认值为0,表示除非用户除了CREATE ROUTING或ALTER ROUTINE权限外还有SUPER权限,否则将禁止创建或修改存储函数,同时,还要求在创建函数时必需为之使用DETERMINISTIC属性,再不然就是附带READS SQL DATA或NO SQL属性。设置其值为1时则不启用这些限制。作用范围为全局级别,可用于配置文件,属动态变量。
log_error=/PATH/TO/ERROR_LOG_FILENAME
定义错误日志文件。作用范围为全局或会话级别,可用于配置文件,属非动态变量。
log_output={TABLE|FILE|NONE}
定义一般查询日志和慢查询日志的保存方式,可以是TABLE、FILE、NONE,也可以是TABLE及FILE的组合(用逗号隔开),默认为TABLE。如果组合中出现了NONE,那么其它设定都将失效,同时,无论是否启用日志功能,也不会记录任何相关的日志信息。作用范围为全局级别,可用于配置文件,属动态变量。
log_query_not_using_indexes={ON|OFF}
设定是否将没有使用索引的查询操作记录到慢查询日志。作用范围为全局级别,可用于配置文件,属动态变量。
log_slave_updates
用于设定复制场景中的从服务器是否将从主服务器收到的更新操作记录进本机的二进制日志中。本参数设定的生效需要在从服务器上启用二进制日志功能。
log_slow_queries={YES|NO}
是否记录慢查询日志。慢查询是指查询的执行时间超出long_query_time参数所设定时长的事件。MySQL 5.6将此参数修改为了slow_query_log。作用范围为全局级别,可用于配置文件,属动态变量。
log_warnings=#
设定是否将警告信息记录进错误日志。默认设定为1,表示启用;可以将其设置为0以禁用;而其值为大于1的数值时表示将新发起连接时产生的“失败的连接”和“拒绝访问”类的错误信息也记录进错误日志。
long_query_time=#
设定区别慢查询与一般查询的语句执行时间长度。这里的语句执行时长为实际的执行时间,而非在CPU上的执行时长,因此,负载较重的服务器上更容易产生慢查询。其最小值为0,默认值为10,单位是秒钟。它也支持毫秒级的解析度。作用范围为全局或会话级别,可用于配置文件,属动态变量。
max_binlog_cache_size{4096 .. 18446744073709547520}
二进定日志缓存空间大小,5.5.9及以后的版本仅应用于事务缓存,其上限由max_binlog_stmt_cache_size决定。作用范围为全局级别,可用于配置文件,属动态变量。
max_binlog_size={4096 .. 1073741824}
设定二进制日志文件上限,单位为字节,最小值为4K,最大值为1G,默认为1G。某事务所产生的日志信息只能写入一个二进制日志文件,因此,实际上的二进制日志文件可能大于这个指定的上限。作用范围为全局级别,可用于配置文件,属动态变量。
max_relay_log_size={4096..1073741824}
设定从服务器上中继日志的体积上限,到达此限度时其会自动进行中继日志滚动。此参数值为0时,mysqld将使用max_binlog_size参数同时为二进制日志和中继日志设定日志文件体积上限。作用范围为全局级别,可用于配置文件,属动态变量。
innodb_log_buffer_size={262144 .. 4294967295}
设定InnoDB用于辅助完成日志文件写操作的日志缓冲区大小,单位是字节,默认为8MB。较大的事务可以借助于更大的日志缓冲区来避免在事务完成之前将日志缓冲区的数据写入日志文件,以减少I/O操作进而提升系统性能。因此,在有着较大事务的应用场景中,建议为此变量设定一个更大的值。作用范围为全局级别,可用于选项文件,属非动态变量。
innodb_log_file_size={108576 .. 4294967295}
设定日志组中每个日志文件的大小,单位是字节,默认值是5MB。较为明智的取值范围是从1MB到缓存池体积的1/n,其中n表示日志组中日志文件的个数。日志文件越大,在缓存池中需要执行的检查点刷写操作就越少,这意味着所需的I/O操作也就越少,然而这也会导致较慢的故障恢复速度。作用范围为全局级别,可用于选项文件,属非动态变量。
innodb_log_files_in_group={2 .. 100}
设定日志组中日志文件的个数。InnoDB以循环的方式使用这些日志文件。默认值为2。作用范围为全局级别,可用于选项文件,属非动态变量。
innodb_log_group_home_dir=/PATH/TO/DIR
设定InnoDB重做日志文件的存储目录。在缺省使用InnoDB日志相关的所有变量时,其默认会在数据目录中创建两个大小为5MB的名为ib_logfile0和ib_logfile1的日志文件。作用范围为全局级别,可用于选项文件,属非动态变量。
innodb_support_xa={TRUE|FLASE}
存储引擎事务在存储引擎内部被赋予了ACID属性,分布式(XA)事务是一种高层次的事务,它利用“准备”然后“提交”(prepare-then-commit)两段式的方式将ACID属性扩展到存储引擎外部,甚至是数据库外部。然而,“准备”阶段会导致额外的磁盘刷写操作。XA需要事务协调员,它会通知所有的参与者准备提交事务(阶段1)。当协调员从所有参与者那里收到“就绪”信息时,它会指示所有参与者进行真正的“提交”操作。
此变量正是用于定义InnoDB是否支持两段式提交的分布式事务,默认为启用。事实上,所有启用了二进制日志的并支持多个线程同时向二进制日志写入数据的MySQL服务器都需要启用分布式事务,否则,多个线程对二进制日志的写入操作可能会以与原始次序不同的方式完成,这将会在基于二进制日志的恢复操作中或者是从服务器上创建出不同原始数据的结果。因此,除了仅有一个线程可以改变数据以外的其它应用场景都不应该禁用此功能。而在仅有一个线程可以修改数据的应用中,禁用此功能是安全的并可以提升InnoDB表的性能。作用范围为全局和会话级别,可用于选项文件,属动态变量。
relay_log=file_name
设定中继日志的文件名称,默认为host_name-relay-bin。也可以使用绝对路径,以指定非数据目录来存储中继日志。作用范围为全局级别,可用于选项文件,属非动态变量。
relay_log_index=file_name
设定中继日志的索引文件名,默认为为数据目录中的host_name-relay-bin.index。作用范围为全局级别,可用于选项文件,属非动态变量。
relay-log-info-file=file_name
设定中继服务用于记录中继信息的文件,默认为数据目录中的relay-log.info。作用范围为全局级别,可用于选项文件,属非动态变量。
relay_log_purge={ON|OFF}
设定对不再需要的中继日志是否自动进行清理。默认值为ON。作用范围为全局级别,可用于选项文件,属动态变量。
relay_log_space_limit=#
设定用于存储所有中继日志文件的可用空间大小。默认为0,表示不限定。最大值取决于系统平台位数。作用范围为全局级别,可用于选项文件,属非动态变量。
slow_query_log={ON|OFF}
设定是否启用慢查询日志。0或OFF表示禁用,1或ON表示启用。日志信息的输出位置取决于log_output变量的定义,如果其值为NONE,则即便slow_query_log为ON,也不会记录任何慢查询信息。作用范围为全局级别,可用于选项文件,属动态变量。
slow_query_log_file=/PATH/TO/SOMEFILE
设定慢查询日志文件的名称。默认为hostname-slow.log,但可以通过--slow_query_log_file选项修改。作用范围为全局级别,可用于选项文件,属动态变量。
sql_log_bin={ON|OFF}
用于控制二进制日志信息是否记录进日志文件。默认为ON,表示启用记录功能。用户可以在会话级别修改此变量的值,但其必须具有SUPER权限。作用范围为全局和会话级别,属动态变量。
sql_log_off={ON|OFF}
用于控制是否禁止将一般查询日志类信息记录进查询日志文件。默认为OFF,表示不禁止记录功能。用户可以在会话级别修改此变量的值,但其必须具有SUPER权限。作用范围为全局和会话级别,属动态变量。
sync_binlog=#
设定多久同步一次二进制日志至磁盘文件中,0表示不同步,任何正数值都表示对二进制每多少次写操作之后同步一次。当autocommit的值为1时,每条语句的执行都会引起二进制日志同步,否则,每个事务的提交会引起二进制日志同步。 建议设置为1。
1.前置条件:
本次是基于小数据量,且数据块在一个页中的最理想情况进行分析,可能无具体的实际意义,但是可以借鉴到各种复杂条件下,因为原理是相同的,知小见大,见微知著!
打开语句分析并确认是否已经打开
- mysql> set profiling=1;
- Query OK, 0 rows affected (0.00 sec)
- mysql> select @@profiling;
- +-------------+
- | @@profiling |
- +-------------+
- | 1 |
- +-------------+
- 1 row in set (0.01 sec)
2.数据准备:
2.1全表扫描数据
- create table person4all(id int not null auto_increment, name varchar(30) not null, gender varchar(10) not null ,primary key(id));
- insert into person4all(name,gender) values("zhaoming","male");
- insert into person4all(name,gender) values("wenwen","female");
2.2根据主键查看数据
- create table person4pri(id int not null auto_increment, name varchar(30) not null, gender varchar(10) not null ,primary key(id));
- insert into person4pri(name,gender) values("zhaoming","male");
- insert into person4pri(name,gender) values("wenwen","female");
2.3根据非聚集索引查数据
- create table person4index(id int not null auto_increment, name varchar(30) not null, gender varchar(10) not null ,primary key(id) , index(gender));
- insert into person4index(name,gender) values("zhaoming","male");
- insert into person4index(name,gender) values("wenwen","female");
2.4根据覆盖索引查数据
- create table person4cindex(id int not null auto_increment, name varchar(30) not null, gender varchar(10) not null ,primary key(id) , index(name,gender));
- insert into person4cindex(name,gender) values("zhaoming","male");
- insert into person4cindex(name,gender) values("wenwen","female");
主要从以下几个方面分析:查询消耗的时间,走的执行计划等方面。
3.开工测试:
第一步:全表扫描
- mysql> select * from person4all ;
- +----+----------+--------+
- | id | name | gender |
- +----+----------+--------+
- | 1 | zhaoming | male |
- | 2 | wenwen | female |
- +----+----------+--------+
- 2 rows in set (0.00 sec)
查看其执行计划:
- mysql> explain select * from person4all;
- +----+-------------+------------+------+---------------+------+---------+------+------+-------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+------------+------+---------------+------+---------+------+------+-------+
- | 1 | SIMPLE | person4all | ALL | NULL | NULL | NULL | NULL | 2 | |
- +----+-------------+------------+------+---------------+------+---------+------+------+-------+
- 1 row in set (0.01 sec)
我们可以很清晰的看到走的是全表扫描,而没有走索引!
查询消耗的时间:
- mysql> show profiles;
- +----------+------------+-----------------------------------------------------------------------------------------------------------------------------------+
- | Query_ID | Duration | Query |
- | 54 | 0.00177300 | select * from person4all |
- | 55 | 0.00069200 | explain select * from person4all |
- +----------+------------+-----------------------------------------------------------------------------------------------------------------------------------+
全表扫描总共话了0.0017730秒
各个阶段消耗的时间是:
- mysql> show profile for query 54;
- +--------------------------------+----------+
- | Status | Duration |
- +--------------------------------+----------+
- | starting | 0.000065 |
- | checking query cache for query | 0.000073 |
- | Opening tables | 0.000037 |
- | System lock | 0.000024 |
- | Table lock | 0.000053 |
- | init | 0.000044 |
- | optimizing | 0.000022 |
- | statistics | 0.000032 |
- | preparing | 0.000030 |
- | executing | 0.000020 |
- | Sending data | 0.001074 |
- | end | 0.000091 |
- | query end | 0.000020 |
- | freeing items | 0.000103 |
- | storing result in query cache | 0.000046 |
- | logging slow query | 0.000019 |
- | cleaning up | 0.000020 |
- +--------------------------------+----------+
- 17 rows in set (0.00 sec)
第一次不走缓存的话,需要检查是否存在缓存中,打开表,初始化等操作,最大的开销在于返回数据。
第二步:根据主键查询数据。
- mysql> select name ,gender from person4pri where id in (1,2);
- +----------+--------+
- | name | gender |
- +----------+--------+
- | zhaoming | male |
- | wenwen | female |
- +----------+--------+
- 2 rows in set (0.01 sec)
查看其执行计划:
- mysql> explain select name ,gender from person4pri where id in (1,2);
- +----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+
- | 1 | SIMPLE | person4pri | range | PRIMARY | PRIMARY | 4 | NULL | 2 | Using where |
- +----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+
- 1 row in set (0.00 sec)
从执行计划中我们可以看出,走的是范围索引。
再看其执行消耗的时间:
- mysql> show profiles;
- +----------+------------+-----------------------------------------------------------------------------------------------------------------------------------+
- | Query_ID | Duration | Query |
- +----------+------------+-----------------------------------------------------------------------------------------------------------------------------------+
- | 63 | 0.00135700 | select name ,gender from person4pri where id in (1,2) |
- | 64 | 0.00079200 | explain select name ,gender from person4pri where id in (1,2) |
- +----------+------------+-----------------------------------------------------------------------------------------------------------------------------------+
- 15 rows in set (0.01 sec)
这次查询消耗时间为0.00079200。
查看各个阶段消耗的时间:
- mysql> show profile for query 63;
- +--------------------------------+----------+
- | Status | Duration |
- +--------------------------------+----------+
- | starting | 0.000067 |
- | checking query cache for query | 0.000146 |
- | Opening tables | 0.000342 |
- | System lock | 0.000027 |
- | Table lock | 0.000115 |
- | init | 0.000056 |
- | optimizing | 0.000032 |
- | statistics | 0.000069 |
- | preparing | 0.000039 |
- | executing | 0.000022 |
- | Sending data | 0.000100 |
- | end | 0.000075 |
- | query end | 0.000022 |
- | freeing items | 0.000158 |
- | storing result in query cache | 0.000045 |
- | logging slow query | 0.000019 |
- | cleaning up | 0.000023 |
- +--------------------------------+----------+
- 17 rows in set (0.00 sec)
看出最大的消耗也是在Sending data,第一次也是需要一些初始化操作。
第三步:根据非聚集索引查询
- mysql> select name ,gender from person4index where gender in ("male","female");
- +----------+--------+
- | name | gender |
- +----------+--------+
- | wenwen | female |
- | zhaoming | male |
- +----------+--------+
- 2 rows in set (0.00 sec)
查看器执行计划:
- mysql> explain select name ,gender from person4index where gender in ("male","female");
- +----+-------------+--------------+-------+---------------+--------+---------+------+------+-------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+--------------+-------+---------------+--------+---------+------+------+-------------+
- | 1 | SIMPLE | person4index | range | gender | gender | 12 | NULL | 2 | Using where |
- +----+-------------+--------------+-------+---------------+--------+---------+------+------+-------------+
- 1 row in set (0.00 sec)
可以看出,走的也是范围索引。同主键查询,那么就看其消耗时间了
- mysql> show profiles;
- +----------+------------+-----------------------------------------------------------------------------------------------------------------------------------------------------+
- | Query_ID | Duration | Query |
- +----------+------------+-----------------------------------------------------------------------------------------------------------------------------------------------------+
- | 68 | 0.00106600 | select name ,gender from person4index where gender in ("male","female") |
- | 69 | 0.00092500 | explain select name ,gender from person4index where gender in ("male","female") |
- +----------+------------+-----------------------------------------------------------------------------------------------------------------------------------------------------+
- 15 rows in set (0.00 sec)
这个非主键索引消耗的时间为:0.00106600,可以看出略大于组件索引消耗的时间。
看其具体消耗的阶段:
- mysql> show profile for query 68 ;
- +--------------------------------+----------+
- | Status | Duration |
- +--------------------------------+----------+
- | starting | 0.000059 |
- | checking query cache for query | 0.000111 |
- | Opening tables | 0.000085 |
- | System lock | 0.000023 |
- | Table lock | 0.000067 |
- | init | 0.000183 |
- | optimizing | 0.000031 |
- | statistics | 0.000139 |
- | preparing | 0.000035 |
- | executing | 0.000020 |
- | Sending data | 0.000148 |
- | end | 0.000024 |
- | query end | 0.000019 |
- | freeing items | 0.000043 |
- | storing result in query cache | 0.000042 |
- | logging slow query | 0.000017 |
- | cleaning up | 0.000020 |
- +--------------------------------+----------+
- 17 rows in set (0.00 sec)
看几个关键词的点;init,statistics,Sending data 这几个关键点上的消耗向比较主键的查询要大很多,特别是Sending data。因为若是走的非聚集索引,那么就需要回表进行再进行一次查询,多消耗一次IO。
第四部:根据覆盖索引查询数据
- mysql> select gender ,name from person4cindex where gender in ("male","female");
- +--------+----------+
- | gender | name |
- +--------+----------+
- | female | wenwen |
- | male | zhaoming |
- +--------+----------+
- 2 rows in set (0.01 sec)
这里需要注意的是,我的字段查询顺序变了,是gender,name而不在是前面的name,gender,这样是为了走覆盖索引。具体看效果吧
还是先看执行计划:
- mysql> explain select gender ,name from person4cindex where gender in ("male","female");
- +----+-------------+---------------+-------+---------------+------+---------+------+------+--------------------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+---------------+-------+---------------+------+---------+------+------+--------------------------+
- | 1 | SIMPLE | person4cindex | index | NULL | name | 44 | NULL | 2 | Using where; Using index |
- +----+-------------+---------------+-------+---------------+------+---------+------+------+--------------------------+
- 1 row in set (0.00 sec)
最后栏Extra中表示走的就是覆盖索引。
看消耗的时间吧:
- mysql> show profiles;
- +----------+------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
- | Query_ID | Duration | Query |
- +----------+------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
- | 83 | 0.00115400 | select gender ,name from person4cindex where gender in ("male","female") |
- | 84 | 0.00074000 | explain select gender ,name from person4cindex where gender in ("male","female") |
- +----------+------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
我们看到消耗的时间是0.00115400,看这个数字好像挺高的,那么都花在什么地方了呢?
看下具体的消耗情况:
- mysql> show profile for query 83 ;
- +--------------------------------+----------+
- | Status | Duration |
- +--------------------------------+----------+
- | starting | 0.000083 |
- | checking query cache for query | 0.000113 |
- | Opening tables | 0.000039 |
- | System lock | 0.000026 |
- | Table lock | 0.000075 |
- | init | 0.000128 |
- | optimizing | 0.000193 |
- | statistics | 0.000056 |
- | preparing | 0.000038 |
- | executing | 0.000021 |
- | Sending data | 0.000121 |
- | end | 0.000042 |
- | query end | 0.000021 |
- | freeing items | 0.000112 |
- | storing result in query cache | 0.000043 |
- | logging slow query | 0.000021 |
- | cleaning up | 0.000022 |
- +--------------------------------+----------+
- 17 rows in set (0.00 sec)
很惊奇吧,在初始化和优化上消耗了这么多时间,取数据基恩差不多。
总 结:
有了上面这些数据,那么我们整理下吧。未存在缓存下的数据。

看这个表,全表扫描最慢,我们可以理解,同时主键查询比覆盖所有扫描慢也还能接受,但是为什么主键扫描会比非主键扫描慢?而且非主键查询需要消耗的1次查询的io+一次回表的查询IO,理论上是要比主键扫描慢,而出来的数据缺不是如此。那么就仔细看下是个查询方式在各个主要阶段消耗的时间吧。
查询是否存在缓存,打开表及锁表这些操作时间是差不多,我们不会计入。具体还是看init,optimizing等环节消耗的时间。
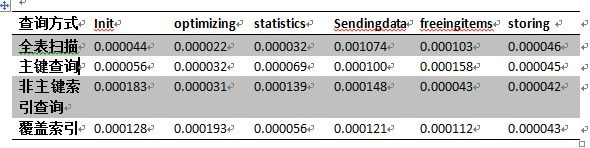
1.从这个表中,我们看到非主键索引和覆盖索引在准备时间上需要开销很多的时间,预估这两种查询方式都需要进行回表操作,所以花在准备上更多时间。
2.第二项optimizing上,可以清晰知道,覆盖索引话在优化上大量的时间,这样在二级索引上就无需回表。
3. Sendingdata,全表扫描慢就慢在这一项上,因为是加载所有的数据页,所以花费在这块上时间较大,其他三者都差不多。
4. 非主键查询话在freeingitems上时间最少,那么可以看出它在读取数据块的时候最少。
5.相比较主键查询和非主键查询,非主键查询在Init,statistics都远高于主键查询,只是在freeingitems开销时间比主键查询少。因为这里测试数据比较少,但是我们可以预见在大数据量的查询上,不走缓存的话,那么主键查询的速度是要快于非主键查询的,本次数据不过是太小体现不出差距而已。
6.在大多数情况下,全表扫描还是要慢于索引扫描的。
tips:
过程中的辅助命令:
1.清楚缓存
reset query cache ;
flush tables;
2.查看表的索引:
show index from tablename;
一、什么是视图?
视图就是存储下来的SQL SELECT语句,也可以说是虚拟的表(在MySQL中视图被当着表来用)。这些数据可以是从一个或几个基本表(或视图)的数据。也可以是用户自已定义的数据。其实视图里面不存放数据的,数据还是放在基本表里面,基本表里面的数据发生变动时,视图里面的数据随之变动。
视图的作用:
- 视图可以让查询变得很清楚:
如果您要找的数据存放在三张关系表里面,查看数据的时候,你就要写个联合查询了。换种方法,我把联合查询的数据放到视图里面,这样查询起来是不是更方便呢?
- 保护数据库的重要数据,给不同的人看不同的数据:
假如您让别人帮您开发一套系统,但是你又想把真正表的暴露出来,这个时候视图是不是最好的选择呢?
视图的类型:
mysql的视图有三种类型:MERGE、TEMPTABLE、UNDEFINED。如果没有ALGORITHM子句,默认算法是UNDEFINED(未定义的)。算法会影响MySQL处理视图的方式。
1,MERGE,会将引用视图的语句的文本与视图定义合并起来,使得视图定义的某一部分取代语句的对应部分。
2,TEMPTABLE,视图的结果将被置于临时表中,然后使用它执行语句。
3,UNDEFINED,MySQL将选择所要使用的算法。如果可能,它倾向于MERGE而不是TEMPTABLE,这是因为MERGE通常更有效,而且如果使用了临时表,视图是不可更新的。
二、创建、删除视图:
创建视图基本语法:
CREATE
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
如下:
mysql> CREATE VIEW sc AS SELECT s.Name,c.Cname FROM students AS s RIGHT JOIN courses AS c ON s.CID1=c.CID;
Query OK, 0 rows affected (0.07 sec)mysql> SHOW TABLES;
+------------------+
| Tables_in_jiaowu |
+------------------+
| courses |
| sc |
| scores |
| students |
| tutors |
+------------------+
5 rows in set (0.01 sec)mysql> SELECT * FROM sc;
+--------------+------------------+
| Name | Cname |
+--------------+------------------+
| GuoJing | TaiJiquan |
| YangGuo | TaiJiquan |
| DingDian | Qishangquan |
| HuFei | Wanliduxing |
| HuangRong | Qianzhuwandushou|
| YueLingshang | Wanliduxing |
| ZhangWuji | Hamagong |
| Xuzhu | TaiJiquan |
| NULL | Yiyangzhi |
| NULL | Jinshejianfa |
| NULL | Qiankundanuoyi |
| NULL | Pixiejianfa |
| NULL | Jiuyinbaiguzhua |
+--------------+------------------+
13 rows in set (0.02 sec)
删除视图基本语法:
DROP VIEW [IF EXISTS]
view_name [, view_name] ...
[RESTRICT | CASCADE]
如下:
mysql> DROP VIEW IF EXISTS sc;
Query OK, 0 rows affected (0.01 sec)
查看视图创建过程:
mysql> SHOW CREATE VIEW sc\G
*************************** 1. row ***************************
View: sc
Create View: CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost` SQL SECURITY DEFINER VIEW `sc` AS select `s`.`Name` AS `Name`,`c`.`Cname` AS `Cname` from (`courses` `c` left join `students` `s` on((`s`.`CID1` = `c`.`CID`)))
character_set_client: utf8
collation_connection: utf8_general_ci
1 row in set (0.00 sec)
三、在MySQL中使用视图的注意事项:
(1) 运行创建视图的语句需要用户具有创建视图(crate view)的权限,若加了[or replace]时,还需要用户具有删除视图(drop view)的权限;
(2) select语句不能包含from子句中的子查询;
(3) select语句不能引用系统或用户变量;
(4) select语句不能引用预处理语句参数;
(5) 在存储子程序内,定义不能引用子程序参数或局部变量;
(6)在定义中引用的表或视图必须存在。但是,创建了MySQL视图后,能够舍弃定义引用的表或视图。要想检查视图定义是否存在这类问题,可使用check table语句;
(7) 在定义中不能引用temporary表,不能创建temporary视图;
(8) 在视图定义中命名的表必须已存在;
(9) 不能将触发程序与视图关联在一起;
(10) 在视图定义中允许使用order by,但是,如果从特定视图进行了选择,而该视图使用了具有自己order by的语句,它将被忽略。
(11)MySQL视图不支持雾化(即将视图保持为实际的数据),也不能创建索引,因此效率较低!
一、什么是事务?
数据库的事物,是指将一系列的操作作为一个逻辑单元来执行,即加入由十条SQL语句组成的一个事物,则要么则十条都执行成功,要么都不执行!事务处理可以确保除非事务性单元内的所有操作都成功完成,否则不会永久更新面向数据的资源。一个逻辑工作单元要成为事务,必须满足所谓的ACID(原子性、一致性、隔离性和持久性)属性。
为什么要用事务?
假想一下,没有事务的情况会发生什么情况:你通过网银向别人转的账户转钱,结果执行到一半,出现故障(如服务器宕机),你的钱被减少了,而你转账的对方账户钱却没有加上去!钱消失了!
如果有事务会是怎么样的?当执行到一半出错,那已经执行的也会被撤销,保障ACID!
二、事务的ACID属性:
原子性(atomicity)
事务必须是原子工作单元;对于其数据修改,要么全都执行,要么全都不执行。通常,与某个事务关联的操作具有共同的目标,并且是相互依赖的。如果系统只执行这些操作的一个子集,则可能会破坏事务的总体目标。原子性消除了系统处理操作子集的可能性。
一致性(consistency)
事务在完成时,必须使所有的数据都保持一致状态。在相关数据库中,所有规则都必须应用于事务的修改,以保持所有数据的完整性。事务结束时,所有的内部数据结构(如 B 树索引或双向链表)都必须是正确的。某些维护一致性的责任由应用程序开发人员承担,他们必须确保应用程序已强制所有已知的完整性约束。例如,当开发用于转帐的应用程序时,应避免在转帐过程中任意移动小数点。
隔离性(isolation)
由并发事务所作的修改必须与任何其它并发事务所作的修改隔离。事务查看数据时数据所处的状态,要么是另一并发事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看中间状态的数据。这称为隔离性,因为它能够重新装载起始数据,并且重播一系列事务,以使数据结束时的状态与原始事务执行的状态相同。当事务可序列化时将获得最高的隔离级别。在此级别上,从一组可并行执行的事务获得的结果与通过连续运行每个事务所获得的结果相同。由于高度隔离会限制可并行执行的事务数,所以一些应用程序降低隔离级别以换取更大的吞吐量。
持久性(durability)
事务完成之后,它对于系统的影响是永久性的。该修改即使出现致命的系统故障也将一直保持。保证事务的持久性,主要通过如下方式完成:
- 事务提交之前就已经写入数据至持久性存储;
- 通过事务日志协助完成(事务日志使用连续IO,因此写入非常快)
三、MySQL对事务的支持情况:
MySQL数据库中,只有使用InnoDB 和 BDB存储引擎才支持事务,而其他存储引擎(如常用的MyISAM引擎)是不支持事务的,这点特别需要注意。
四、事务的隔离级别详解
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read(可重读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
这四种隔离级别采取不同的锁类型来实现,若读取的是同一个数据的话,就容易发生问题。例如:
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
在MySQL中,实现了这四种隔离级别,分别有可能产生问题如下所示:

下面,将利用MySQL的客户端程序,分别测试几种隔离级别。测试数据库为test,表为tx;表结构:
id int
num int
两个命令行客户端分别为A,B;不断改变A的隔离级别,在B端修改数据。
(一)、将A的隔离级别设置为read uncommitted(未提交读)
在B未更新数据之前:
客户端A:

B更新数据:
客户端B:
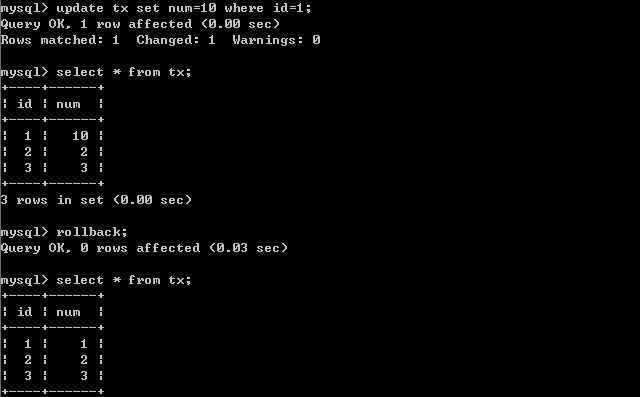
客户端A:

经过上面的实验可以得出结论,事务B更新了一条记录,但是没有提交,此时事务A可以查询出未提交记录。造成脏读现象。未提交读是最低的隔离级别。
(二)、将客户端A的事务隔离级别设置为read committed(已提交读)
在B未更新数据之前:
客户端A:
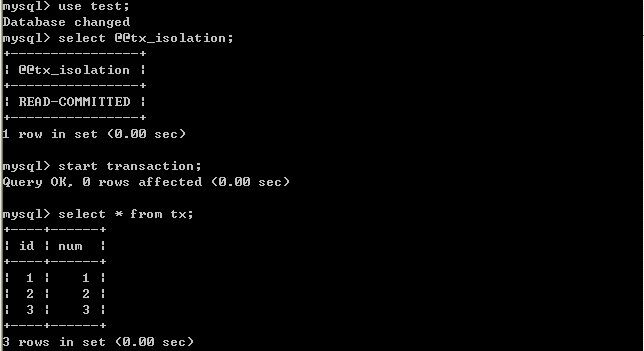
B更新数据:
客户端B:

客户端A:
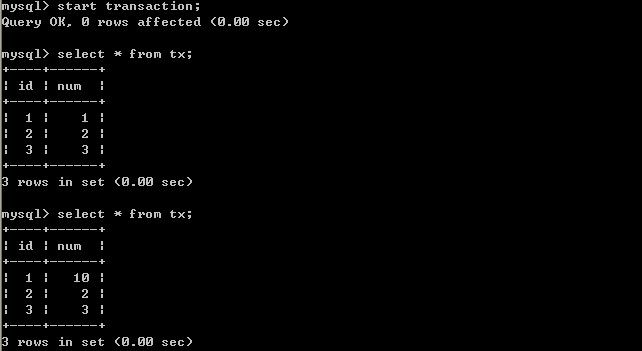
经过上面的实验可以得出结论,已提交读隔离级别解决了脏读的问题,但是出现了不可重复读的问题,即事务A在两次查询的数据不一致,因为在两次查询之间事务B更新了一条数据。已提交读只允许读取已提交的记录,但不要求可重复读。
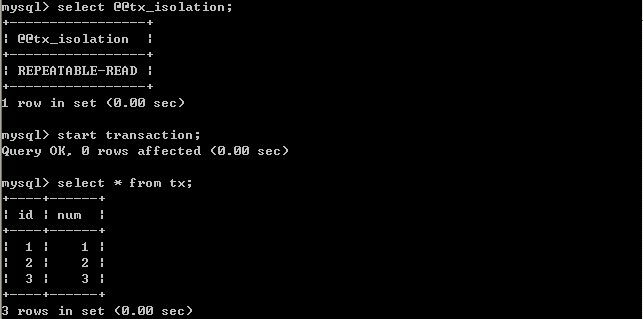
(三)、将A的隔离级别设置为repeatable read(可重复读)
在B未更新数据之前:
客户端A:
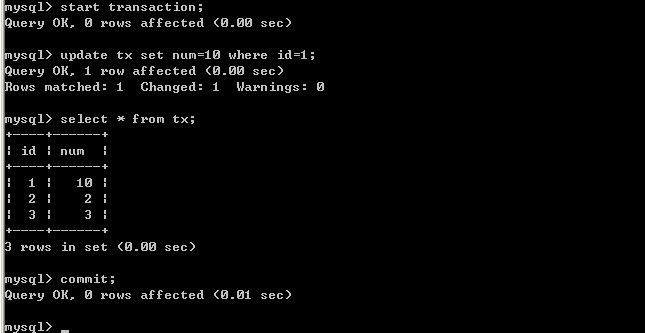
B更新数据:
客户端B:
客户端A:

B插入数据:
客户端B:

客户端A:

由以上的实验可以得出结论,可重复读隔离级别只允许读取已提交记录,而且在一个事务两次读取一个记录期间,其他事务部的更新该记录。但该事务不要求与其他事务可串行化。例如,当一个事务可以找到由一个已提交事务更新的记录,但是可能产生幻读问题(注意是可能,因为数据库对隔离级别的实现有所差别)。像以上的实验,就没有出现数据幻读的问题。
(四)、将A的隔离级别设置为 可串行化 (Serializable)
A端打开事务,B端插入一条记录
事务A端:

事务B端:

因为此时事务A的隔离级别设置为serializable,开始事务后,并没有提交,所以事务B只能等待。
事务A提交事务:
事务A端

事务B端
![]()
serializable完全锁定字段,若一个事务来查询同一份数据就必须等待,直到前一个事务完成并解除锁定为止 。是完整的隔离级别,会锁定对应的数据表格,因而会有效率的问题。
五、事务的其他说明:
5.1 事务的状态:
事务包括如下几种状态:
- 活动的:正在执行
- 部分提交的:最后一条语句执行后
- 失败的:
- 终止的:
- 提交的:已经提交成功的
几种状态的转换情况见下图:

5.2 事务的其他知识点:
事务并发执行的好处:提高吞吐量和资源利用率、减少等待时间。
事务调度的分类:可恢复调度、无级联调度。
并发控制依赖的技术手段:锁、时间戳、多版本和快照隔离
锁:读锁(共享锁)、写锁(独占锁、排查锁)
锁粒度:从大到小,Mysql服务器只支持表级锁,行锁需要有存储引擎完成;
5.3 事务的控制命令:
START TANSACTION:启动
SQL语句
……ROLLBACK: 回滚
COMMIT: 提交
事务流程如下:

需要注意的是,事务的回滚需要在提交之前,如果已经提交了,就无法回滚了。
另外在Mysql下,如果没有明确启动事务,且autocommit变量设置为1,就会实现自动提交,每一个操作都直接提交。
查看当前autocommit设置:
mysql> SELECT @@autocommit;
+--------------+
| @@autocommit |
+--------------+
| 1 |
+--------------+
1 row in set (0.01 sec)
在MySQL的InnoDB存储引擎下,为了保障数据的持久性,默认将autocommit置为1,以实现自动提交事务。但为了数据的安全性,建议明确使用事务。
5.4 事务的保存点:
在一个事务中,如果包含的语句较多,如一个事务要执行100条SQL语句,如果执行到99条的时候,发现95条出现了错误,需要回退,莫非只能全部回滚?
为了防止这样的情况发生,引入了保存点(SAVEPOINT)的概念。加入还是上述的100条语句,如果每十条语句建立一个保存点,那么则只需回滚至第90条即可,极大的提高了效率。
具体命令和流程如下:
START TANSACTION:启动
SQL
……SAVEPOINT sid_one :创建保存点
SQL……
SAVEPOINT sid_two :创建保存点
……
ROLLBACK TO sid :回滚到指定保存点
COMMIT: 提交
一、MySQL用户的基本说明:
1.1 用户的基本结构
MySQL的用户:用户名@主机
- 用户名:16个字符以内
- 主机:可以是主机名、IP地址、网络地址等
主机名:www.toxingwang.com,localhost
IP:192.168.0.1
网络地址:172.16.0.0/255.255.0.0
主机还支持通配符:%和_
172.16.%.%
%.toxingwang.com
注意:对于包含了主机名的用户,MySQL会尝试反解析主机名,此时可能会造成连接非常慢,如果反解析的IP地址与连接点的地址不同,还可能出现无法连接的情况。因此,为了加快连接并避免出现解析问题,可以在my.cnf文件中加入如下一行加速连接:
--skip-name-resolve
MySQL用户的密码有MySQL内部的password()函数管理。
1.2 授权表:
MySQL用户只是用于认证,而用户具有的权限有相应的授权机制实现。首先MySQL用户授权的,主要为如下刘张表:
user: Contains user accounts, global privileges, and other non-privilege columns.
user: 用户帐号、全局权限db: Contains database-level privileges.
db: 库级别权限host: Obsolete.
host: 废弃tables_priv: Contains table-level privileges.
tables_priv: 表级别权限columns_priv: Contains column-level privileges.
columns_priv: 列级别权限procs_priv: Contains stored procedure and function privileges.
procs_priv: 存储过程和存储函数相关的权限proxies_priv: Contains proxy-user privileges.
proxies_priv: 代理用户权限在MySQL数据库服务启动后,这六张表会被直接加载到内存,而今后所有的认证都直接从内存中这六张表获取,而不是去读取磁盘。
1.3 各授权表的说明:
- user表范围列决定是否允许或拒绝到来的连接。对于允许的连接,user表授予的权限指出用户的全局(超级用户)权限。这些权限适用于服务器上的all数据库。
- db表范围列决定用户能从哪个主机存取哪个数据库。权限列决定允许哪个操作。授予的数据库级别的权限适用于数据库和它的表。
- tables_priv和columns_priv表类似于db表,但是更精致:它们在表和列级应用而非在数据库级。授予表级别的权限适用于表和所有它的列。授予列级别的权限只适用于专用列。
- procs_priv表适用于保存的程序。授予程序级别的权限只适用于单个程序。
管理权限(例如RELOAD或SHUTDOWN等等)仅在user表中被指定。这是因为管理性操作是服务器本身的操作并且不是特定数据库,因此没有理由在其他授权表中列出这样的权限。事实上,只需要查询user表来决定你是否执行一个管理操作。
FILE权限也仅在user表中指定。它不是管理性权限,但你在服务器主机上读或写文件的能力与你正在存取的数据库无关。
当mysqld服务器启动时,将授权表的内容读入到内存中。你可以通过FLUSH PRIVILEGES语句或执行mysqladmin flush-privileges或mysqladmin reload命令让它重新读取表。
二、MySQL提供的权限
账户权限信息被存储在mysql数据库的user、db、host、tables_priv、columns_priv和procs_priv表中。在MySQL启动时时,服务器将这些数据库表内容读入内存。
GRANT和REVOKE语句所用的涉及权限的名称显示在下表,还有在授权表中每个权限的表列名称和每个权限有关的上下文。
权限
列
上下文
CREATE
Create_priv
数据库、表或索引
DROP
Drop_priv
数据库或表
GRANT OPTION
Grant_priv
数据库、表或保存的程序
REFERENCES
References_priv
数据库或表
ALTER
Alter_priv
表
DELETE
Delete_priv
表
INDEX
Index_priv
表
INSERT
Insert_priv
表
SELECT
Select_priv
表
UPDATE
Update_priv
表
CREATE VIEW
Create_view_priv
视图
SHOW VIEW
Show_view_priv
视图
ALTER ROUTINE
Alter_routine_priv
保存的程序
CREATE ROUTINE
Create_routine_priv
保存的程序
EXECUTE
Execute_priv
保存的程序
FILE
File_priv
服务器主机上的文件访问
CREATE TEMPORARY TABLES
Create_tmp_table_priv
服务器管理
LOCK TABLES
Lock_tables_priv
服务器管理
CREATE USER
Create_user_priv
服务器管理
PROCESS
Process_priv
服务器管理
RELOAD
Reload_priv
服务器管理
REPLICATION CLIENT
Repl_client_priv
服务器管理
REPLICATION SLAVE
Repl_slave_priv
服务器管理
SHOW DATABASES
Show_db_priv
服务器管理
SHUTDOWN
Shutdown_priv
服务器管理
SUPER
Super_priv
服务器管理
三、权限更改何时生效
当mysqld启动时,所有授权表的内容被读进内存并且从此时生效。
当服务器注意到授权表被改变了时,现存的客户端连接有如下影响:
- 表和列权限在客户端的下一次请求时生效。
- 数据库权限改变在下一个USE db_name命令生效。
- 全局权限的改变和密码改变在下一次客户端连接时生效。
如果用GRANT、REVOKE或SET PASSWORD对授权表进行修改,服务器会注意到并立即重新将授权表载入内存。
如果你手动地修改授权表(使用INSERT、UPDATE或DELETE等等),你应该执行mysqladmin flush-privileges或mysqladmin reload告诉服务器再装载授权表,否则你的更改将不会生效,除非你重启服务器。
如果你直接更改了授权表但忘记重载,重启服务器后你的更改方生效。这样可能让你迷惑为什么你的更改没有什么变化!
四、MySQL用户账户管理
4.1 创建用户与授权:
4.1.1 创建用户:CREATE USER
基本语法:
CREATE USER username@host [IDENTIFIED BY 'password']
示例:
mysql> CREATE USER barlow@'%' IDENTIFIED BY '123456';
Query OK, 0 rows affected (0.34 sec)4.2.2 创建用户并授权:GRANT
基本语法:
GRANT priv_type[(column_list)] ON [object_type] priv_level TO username@'%' [IDENTIFIED BY [PASSWORD] 'password'];
- priv_type:ALL或上面的权限表格中的权限。
- priv_level: *| *.*| db_name.*| db_name.tbl_name| tbl_name| db_name.routine_name
示例:
mysql> GRANT CREATE,INSERT,SELECT,UPDATE,DELETE ON testdb.* TO barlow@'%';
Query OK, 0 rows affected (0.21 sec)mysql> SHOW GRANTS FOR 'barlow'@'%';
+-------------------------------------------------------------------------------------------------------+
| Grants for barlow@% |
+-------------------------------------------------------------------------------------------------------+
| GRANT USAGE ON *.* TO 'barlow'@'%' IDENTIFIED BY PASSWORD '*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9' |
| GRANT SELECT, INSERT, UPDATE, DELETE, CREATE ON `testdb`.* TO 'barlow'@'%' |
+-------------------------------------------------------------------------------------------------------+
2 rows in set (0.01 sec)

通过上图实例可以看到,用户只拥有明确授权的权限。
4.3 用户管理
4.3.1 删除用户:
基本语法:
DROP USER 'username'@'host'
4.3.2 重命名用户:
基本语法:
RENAME USER old_name TO new_name
4.3.3 收回已授予的用户权限
基本语法:
REVOKE priv_type [(column_list)] [, priv_type [(column_list)]] ... ON [object_type] priv_level FROM user [, user] ...
示例:
mysql> mysql> REVOKE INSERT ON testdb.* FROM barlow@'%';
Query OK, 0 rows affected (0.01 sec)

从上图可以看出,barlow@'%'用户已经没有了INSERT权限。
4.3.4 修改用户密码:
方法一:SET PASSWORD
基本语法:
SET PASSWORD FOR 'user_name'@'host' = PASSWORD('new_password');
示例:
mysql> SET PASSWORD FOR 'barlow'@'%' = PASSWORD('987654');
Query OK, 0 rows affected (0.07 sec)说明:管理员可以修改任何用户的密码,但普通用户只能修改自己的密码。
用户修改自己的密码语法(也可以使用上述语法修改):
SET PASSWORD = PASSWORD('new_password');方法二:直接update mysql.user表的password字段实现修改密码:基本语法:mysql> use mysql
mysql> UPDATE user SET Password = PASSWORD('new_password') WHERE User='user_name' AND Host='host';
mysql> FLUSH PRIVILEGES;
示例:
mysql> use mysql
Database changed
mysql> UPDATE user SET Password = PASSWORD('redhat') WHERE User='barlow' AND Host='%';
Query OK, 1 row affected (0.03 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.08 sec)
4.4 找回root用户的密码:
如果root用户的密码忘记后,可以通过如下方法找回:
- 停止mysqld服务
- 启动mysqld_safe时传递两个参数:--skip-grant-tables --skip-networking
- 启动mysqld服务
- 使用直接update mysql.user表的password字段实现修改root用户密码
示例:
停止服务,修改mysqld_safe传递参数:
[root@localhost ~]# service mysqld stop
Shutting down MySQL........ SUCCESS!
[root@localhost ~]# vim /etc/init.d/mysqld

登录mysql修改密码:
[root@localhost ~]# service mysqld start
Starting MySQL....................... SUCCESS!
[root@localhost ~]# mysql ##注意,这里已经不需要登录密码了
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.6.13 Source distribution
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> UPDATE mysql.user SET Password = PASSWORD('123456') WHERE User='root';
Query OK, 0 rows affected (0.00 sec)
Rows matched: 3 Changed: 0 Warnings: 0
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.03 sec)
恢复mysqld_safe传递参数:
[root@localhost ~]# service mysqld stop
Shutting down MySQL........ SUCCESS!
[root@localhost ~]# vim /etc/init.d/mysqld
$bindir/mysqld_safe --datadir="$datadir" --pid-file="$mysqld_pid_file_path" $other_args >/dev/null 2>&1 &
[root@localhost ~]# service mysqld start
Starting MySQL...... SUCCESS!
[root@localhost ~]# mysql ##再次登录,提示需要密码
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)
[root@localhost ~]# mysql -u root –p ##使用新密码正常登录
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.6.13 Source distribution
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
更多mysql用户和权限管理的内容,可参考官方文档:http://dev.mysql.com/doc/refman/5.1/zh/database-administration.html#privilege-changes
第一步:检查系统的状态
通过操作系统的一些工具检查系统的状态,比如CPU、内存、交换、磁盘的利用率、IO、网络,根据经验或与系统正常时的状态相比对,有时系统表面上看起来看空闲,这也可能不是一个正常的状态,因为cpu可能正等待IO的完成。除此之外,还应观注那些占用系统资源(cpu、内存)的进程。
1.用vmstat察看关于内核进程,虚拟内存,磁盘,cpu的的活动状态
[root@ks01 ~]# vmstat
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 208 811596 326016 2485004 0 0 0 1 0 0 0 0 100 0 0其中:
procs--内核进程的状态
--r:运行队列中的进程数,当这个值超过了CPU数目,就可能会出现CPU瓶颈,在一个稳定的工作量下,应该少于5。
--b:等待队列中的进程数(等待I/O)(阻塞进程),通常情况下是接近0的,--w:被交换出去的可运行的进程数。此数由 linux 计算得出,但 linux 并不耗尽交换空间
memory--虚拟和真实内存的使用信息
--swpd:虚拟内存使用大小,单位:KB,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么应该升级内存或者把耗内存的任务迁移到其他机器。
-- free:空闲的物理内存的大小,单位KB-- buff :被用来做为缓存的内存数,单位:KB。Linux/Unix系统用来存储目录内容,权限等的缓存
-- cache:用来保存打开的文件,给文件做缓冲。Linux/Unix将空闲物理内存的一部分用于文件和目录的缓存,这样提高程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。
swap--
-- si:从磁盘交换到内存的交换页数量,单位:KB/秒,即每秒从磁盘读入虚拟内存的大小。-- so:从内存交换到磁盘的交换页数量,单位:KB/秒,即每秒虚拟内存写入磁盘的大小。
io--
-- bi:发送到块设备的块数,单位:块/秒,即块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,
-- bo:从块设备接收到的块数,单位:块/秒,即块设备每秒发送的块数量
如读取文件,bo一般会大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
system--
-- in:每秒的中断数,包括时钟中断
-- cs:每秒的环境(上下文)切换次数,上下文切换次数过多表示CPU大部分浪费在上下文切换,导致CPU运行任务时间过少,CPU没有充分利用。例如我们调用系统函数,代码就会进入内核空间,导致上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好
cpu--按 CPU 的总使用百分比来显示
-- us:用户CPU时间
-- sy:系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
-- id:空闲 CPU时间(包括IO等待时间),一般来说,id + us + sy = 100,
-- wa:等待IO CPU时间
虚拟内存运行原理
在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。
分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。经管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)。
准测
r,b≈0,
如果fre,将会出现连续不断的页面调度,将导致系统性能问题。
对于page列,re,pi,po,cy维持于比较稳定的状态,PI率不超过5,如果有pagin发生,那么关联页面必须先进行pageout
在内存相对紧张的环境下pagein会强制对不同的页面进行steal操作。如果系统正在读一个大批的永久页面,你也许可以看到po和pi列
会出现不一致的增长,这种情景并不一定表明系统负载过重,但是有必要对应用程序的数据访问模式进行见检查。在稳定的情况下,扫描率和重置率几乎相等,在
多个进程处理使用不同的页面的情况下,页面会更加不稳定和杂乱,这时扫描率可能会比重置率高出。
faults列,in,sy,cs会不断跳跃,这里没有明确的限制,唯一的就是这些值最少大于100
cpu列,us,sys,id和wa也是不确定的,最理想的状态是使cpu处于100%工作状态,单这只适合单用户的情况下。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足
如果在多用户环境中us+sys > 80,进程就会在运行队列中花费等待时间,响应时间和吞吐量就会下降。wa>40表明磁盘io没有也许存在不合理的平衡,或者对磁盘操作比较频繁,如果 r经常大于 4 ,且id经常少于40,表示cpu的负荷很重。
如果pi,po 长期不等于0,表示内存不足。
如果disk 经常不等于0, 且在 b中的队列 大于3, 表示 io性能不好。wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
swpd 切换到内存交换区的内存数量(k表示)。如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
cache: 作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载
io bo: 磁盘写的数据量稍大,如果是大文件的写,10M以内基本不用担心,如果是小文件写2M以内基本正常
在Linux下还有很多系统性能分析工具,比较常见的有top、free、ps、time、timex、uptime等。
2.使用sar来检查操作系统是否存在IO问题
sar可以显示CPU、运行队列、磁盘I/O、分页(交换区)、内存、CPU中断、网络等性能数据:
[root@ks01 ~]# sar
Linux 2.6.18-194.el5 (ks01.oss.com) 05/03/201112:00:01 AM CPU %user %nice %system %iowait %steal %idle
12:10:01 AM all 0.00 0.00 0.00 0.03 0.00 99.96
12:20:01 AM all 0.00 0.00 0.00 0.01 0.00 99.98
...
其中:-CPU CPU编号
--%user 在用户模式中运行进程所花的时间的百分比(指的是用户进程使用的cpu资源的百分比)
--%nice 运行正常进程所花的时间的百分比
--%system 在内核模式(系统)中运行进程所花的时间的百分比(指的是系统资源使用cpu资源的百分比)
--%iowait 没有进程在该CPU上执行时,处理器等待I/O完成的时间的百分比(指的是等待io完成的百分比) --这个值过高,表示硬盘存在I/O瓶颈
--%idle CPU空闲时间百分比 ---如果这个值很高 但是系统响应慢 这时候应该加大内存 如果这个值持续太低 说明系统缺少cpu资源如果iowait列的值很大,如在35%以上,说明系统的IO存在瓶颈,CPU花费了很大的时间去等待I/O的完成。Idle很小说明系统CPU很忙。
附:sar 命令行的常用格式:
sar -u 是sar的缺省输出 (CPU 使用情况)
sar [options] [-A] [-o file] t [n] 在命令行中,n 和t 两个参数组合起来定义采样间隔和次数,t为采样间隔,是必须有 的参数,n为采样次数,是可选的,默认值是1,-o file表示将命令结果以二进制格式 存放在文件中,file 在此处不是关键字,是文件名。options 为命令行选项,sar命令
的选项很多,下面只列出常用选项:-A:所有报告的总和。
-u:CPU利用率
-v:进程、I节点、文件和锁表状态。
-d:硬盘使用报告。
-r:没有使用的内存页面和硬盘块。
-g:串口I/O的情况。
-b:缓冲区使用情况。
-a:文件读写情况。
-c:系统调用情况。
-R:进程的活动情况。
-y:终端设备活动情况。
-w:系统交换活动。比如
[root@ks01 ~]# sar -u 2 5 每2秒采集一下信息 收集5次
Linux 2.6.18-194.el5 (ks01.oss.com) 05/03/201103:33:47 PM CPU %user %nice %system %iowait %steal %idle
03:33:49 PM all 0.00 0.00 0.00 0.00 0.00 100.00
03:33:51 PM all 0.00 0.00 0.00 0.00 0.00 100.00
03:33:53 PM all 0.00 0.00 0.00 0.03 0.00 99.97
03:33:55 PM all 0.00 0.00 0.00 0.00 0.00 100.00
03:33:57 PM all 0.00 0.00 0.00 0.00 0.00 100.00
Average: all 0.00 0.00 0.00 0.01 0.00 99.99
3.使用vmstat监控内存 cpu资源
2.1 CPU问题
下面几列需要被察看,以确定cpu是否有问题
Processes in the run queue (procs r)
User time (cpu us)
System time (cpu sy)
Idle time (cpu id)
问题情况:
1) 如果processes in run queue (procs r)的数量远大于系统中cpu的数量,将会使系统便慢。
2) 如果这个数量是cpu的4倍的话,说明系统正面临cpu能力短缺,这将使系统运行速度大幅度降低
3) 如果cpu的idle时间经常为0的话,或者系统占用时间(cpu sy)是用户占用时间(cpu us)两倍的话,系统面临缺少cpu资源
解决方案 :
解决这些情况,涉及到调整应用程序,使其能更有效的使用cpu,同时增加cpu的能力或数量
2.2内存问题
主要查看页导入的数值(swap中的si),如果该值比较大就要考虑内存,大概方法如下:
1) 最简单的,加大RAM
2) 减少RAM的需求
3.磁盘IO问题
处理方式:做raid10提高性能
使用的操作系统很重要。为了更好地使用多CPU机器,应使用Solaris(因为其线程工作得很好)或Linux(因为2.4和以后的内核有很好的SMP支持)。请注意默认情况旧的Linux内核有一个2GB的文件大小限制。如果有这样的一个内核并且需要文件大于2GB,应得到ext2文件系统的大文件支持(LFS)补丁。其它文件系统例如ReiserFS和XFS没有此2GB限制。
4.网络问题
telnet一下MySQL对外开放的端口,如果不通的话,看看防火墙是否正确设置了。另外,看看MySQL是不是开启了skip-networking的选项,如果开启请关闭。
第二步 检查mysql参数
1.几个不被注意的mysql参数
1.1 max_connect_errors
max_connect_errors默认值为10,如果受信帐号错误连接次数达到10则自动堵塞,需要flush hosts来解除。如果你得到象这样的一个错误:
Host ’hostname’ is blocked because of many connection errors.
Unblock with ’mysqladmin flush-hosts’
这意味着,mysqld已经得到了大量(max_connect_errors)的主机’hostname’的在中途被中断了的连接请求。在 max_connect_errors次失败请求后,mysqld认定出错了(象来字一个黑客的攻击),并且阻止该站点进一步的连接,直到某人执行命令 mysqladmin flush-hosts。
内网连接的话,建议设置在10000以上,已避免堵塞,并定期flush hosts。
1.2 connect_timeout
指定MySQL服务等待应答一个连接报文的最大秒数,超出该时间,MySQL向客户端返回 bad handshake。默认值是5秒,在内网高并发环境中建议设置到10-15秒,以便避免bad hand shake。建议同时关注thread_cache_size并设置thread_cache_size为非0值,大小具体调整。
1.3 skip-name-resolve
skip-name-resolve能大大加快用户获得连接的速度,特别是在网络情况较差的情况下。MySQL在收到连接请求的时候,会根据请求包中获得的ip来反向追查请求者的主机名。然后再根据返回的主机名又一次去获取ip。如果两次获得的ip相同,那么连接就成功建立了。在DNS不稳定或者局域网内主机过多的情况下,一次成功的连接将会耗费很多不必要的时间。假如MySQL服务器的ip地址是广域网的,最好不要设置skip-name- resolve。
1.4 slave-net-timeout=seconds
参数含义:当slave从主数据库读取log数据失败后,等待多久重新建立连接并获取数据。默认值是3600秒,如果需要保证同步性,如此NC的参数请极力控制在10秒以下。
1.5 master-connect-retry
参数含义:当重新建立主从连接时,如果连接建立失败,间隔多久后重试。默认是60秒,请按照合理的情况去设置参数。
第三步 检查mysql 相关状态
几个命令:
show status 显示系统状态
show variables 显示系统变量
show processlist 显示进程状态
show profiles; 收集执行查询资源信息 默认是关闭的 开启 set profiling=1;
当调节MySQL服务器时,要配置的两个最重要的变量是key_buffer_size和table_cache。在试图更改其它变量前你应先确信已经适当地配置了这些变量。
下面的例子显示了部分典型的不同的运行时配置的变量值。
• 如果至少有256MB内存和许多表,想要在中等数量的客户时获得最大性能,应使用:
shell> mysqld_safe --key_buffer_size=64M --table_cache=256 \
--sort_buffer_size=4M --read_buffer_size=1M &
• 如果只有128MB内存和少量表,但仍然要进行大量的排序,可以使用:
shell> mysqld_safe --key_buffer_size=16M --sort_buffer_size=1M
如果有许多并行连接,交换问题会发生,除非mysqld已经配置成为每个连接分配很少的内存。如果有足够的内存用于所有连接,mysqld会执行得更好。
• 对于少量内存和大量连接,应使用:
shell> mysqld_safe --key_buffer_size=512K --sort_buffer_size=100K \
--read_buffer_size=100K &
或甚至为:
shell> mysqld_safe --key_buffer_size=512K --sort_buffer_size=16K \
--table_cache=32 --read_buffer_size=8K \
--net_buffer_length=1K &
如果正对远远大于可用内存的表执行GROUP BY或ORDER BY操作,应增加read_rnd_buffer_size的值以加速排序操作后面的行读取。
如果已经安装了MySQL,support-files目录包含一些不同的my.cnf示例文件:my-huge.cnf、my-大.cnf、my-medium.cnf和my-small.cnf。可以使用这些文件来优化系统。
请注意如果在命令行中为mysqld或mysqld_safe指定一个选项,它只在该次服务器调用中保持有效。要想每次服务器运行时使用该选项,将它放在选项文件中。
要想看参数更改的效果,应执行:
shell> mysqld --key_buffer_size=32M --verbose ---help
变量值列于输出的最后。确保--verbose和---help选项在最后。否则,在命令行中列于它们后面的选项的效果不会反映到输出中。
1.连接数
mysql> show variables like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 100 |
+-----------------+-------+
1 row in set (0.00 sec)
mysql> show status like 'max_used_connections';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| Max_used_connections | 1 |
+----------------------+-------+
1 row in set (0.00 sec)
* max_connections:最大连接数
* max_used_connections:响应的连接数
max_connections:允许的并行客户端连接的数量。增大该值会增加mysqld 需要的文件描述符的数量。默认值为100,这个数字应该增大,否则,会经常看到 Too many connections 错误。并且如果连接数达到了最大连接数,应用程序的访问将会被阻塞。
一般情况下,max_used_connections的值在max_connections的85%左右是比较合适的,即:
max_used_connections / max_connections * 100% (理想值 ≈ 85%)
如果max_used_connection值过高或与max_connections相同,那么就是max_connections设置过低,或者系统负荷过高,超过服务器负载上限了。
修改mysql最大连接数,请根据硬件情况调整到合适的大小,一般经验值可设为3000。Windows服务器大概支持量为1500-1800个连接,linux服务器可以支持到8000个左右。请将max_user_connections设0——–这个0代表不限制单用户的最大连接数,其最大连接值可以等于max_connections值。
下面是网上看到的两个公式:
key_buffer_size + (read_buffer_size + sort_buffer_size) * max_connections
innoDB 的公式比这个复杂点:
innodb_buffer_pool_size + key_buffer_size + max_connections * ( sort_buffer_size + read_buffer_size + binlog_cache_size ) + max_connections * 2MB
相关参数:
back_log:back_log值说明MySQL临时停止响应新请求前在短时间内可以堆起多少请求。如果你需要在短时间内允许大量连接,可以增加该数值。当主要MySQL线程在一个很短时间内得到非常多的连接请求,这就起作用,然后主线程花些时间(尽管很短)检查连接并且启动一个新线程。
换句话说,该值为“进”TCP/IP连接帧听队列的大小。操作系统有该队列自己的限制值。该变量最大值请查阅OS文档。企图将back_log设置为高于你的操作系统限值是徒劳无益的。
当观察MySQL主机进程列表,发现大量 264084 | unauthenticated user | xxx.xxx.xxx.xxx | NULL | Connect | NULL | login | NULL 的待连接进程时,就要加大 back_log的值了。默认数值是50。
1.1 mysqladmin -uroot status
[root@mysql1 ~]# mysqladmin -uroot status
Uptime: 1742276 Threads: 2 Questions: 2538 Slow queries: 0 Opens: 145 Flush tables: 1 Open tables: 23 Queries per second avg: 0.1
1.2 show full processlist
1. 显示所有进程
mysql> show full processlist;
+—–+——+———–+——+———+——+——-+———————–+
| Id | User | Host | db | Command | Time | State | Info |
+—–+——+———–+——+———+——+——-+———————–+
| 629 | root | localhost | NULL | Query | 0 | NULL | show full processlist |
| 633 | root | localhost | NULL | Sleep | 11 | | NULL |
+—–+——+———–+——+———+——+——-+———————–+
2 rows in set (0.00 sec)
2. 如果正在运行的语句太多,运行时间太长,表示MySQL效率有问题。必要的时候可以将对应的进程kill掉。
杀死休眠的进程kill ID号
mysql> kill 633;
Query OK, 0 rows affected (0.00 sec)
3. 关注TIME参数,看看正在运行的用户进程有多少是长时间占用的,具体分析下。
1)使用mysqlreport关注Connections,Threads
__ Connections _________________________________________________________
Max used 3 of 200 %Max: 1.50
Total 30.16k 0.7/s
。。。。。。
__ Threads _____________________________________________________________
Running 1 of 2
Cached 1 of 300 %Hit: 99.99
Created 3 0.0/s
Slow 0 0/s
2.连接失败情况
mysql> show status like'%aborted%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Aborted_clients | 46 |
| Aborted_connects | 1 |
+------------------+-------+
2 rows in set (0.00 sec)参数:
* aborted_connects:连接mysql失败次数,如果指过高,那就该检查一下网络,错误链接失败会在此记录。
* aborted_clients:客户端非法中断连接次数。如果随时间而增大,看看mysql的链接是否正常,或者检查一下网络,或者检查一下max_allowed_packet,超过此设置的查询会被中断( show variables like'%max%')。
连接缓存区和结果缓存区可以根据需要动态扩充到max_allowed_packet。当某个查询运行时,也为当前查询字符串分配内存。所有线程共享相同的基本内存。
包消息缓冲区初始化为net_buffer_length字节,但需要时可以增长到max_allowed_packet字节。该值默认很小,以捕获大的(可能是错误的)数据包。
mysql> show variables like '%timeout';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| connect_timeout | 10 |
| delayed_insert_timeout | 300 |
| innodb_lock_wait_timeout | 50 |
| innodb_rollback_on_timeout | OFF |
| interactive_timeout | 28800 |
| net_read_timeout | 30 |
| net_write_timeout | 60 |
| slave_net_timeout | 3600 |
| table_lock_wait_timeout | 50 |
| wait_timeout | 28800 |
+----------------------------+-------+
10 rows in set (0.00 sec)
参数:
* wait_timeout:服务器在关闭非交互连接之前等待活动的秒数。在线程启动时,根据全局wait_timeout值或全局interactive_timeout值初始化会话wait_timeout值,取决于客户端类型(由mysql_real_connect()的连接选项CLIENT_INTERACTIVE定义)
* interactive_timeout:服务器关闭交互式连接前等待活动的秒数。交互式客户端定义为在mysql_real_connect()中使用CLIENT_INTERACTIVE选项的客户端。
* connect_timeout:mysqld服务器用Bad handshake响应前等待连接包的秒数。
3.慢查询(slow query)日志
日志必然会拖慢系统速度,特别是CPU资源,所以如果CPU资源充分,可以一直打开,如果不充足,那就在需要调整的时候,或者在replication从服务器上打开(针对select)。
mysql> show variables like ‘%slow%’;
+———————+—————————————-+
| Variable_name | Value |
+———————+—————————————-+
| log_slow_queries | OFF |
| slow_launch_time | 2 |
| slow_query_log | OFF |
| slow_query_log_file | /data/mysql/data/mysql1-slow.log |
+———————+—————————————-+
4 rows in set (0.00 sec)
参数:
* log_slow_queries:是否记录慢日志,用long_query_time变量的值来确定“慢查询”。
* slow_launch_time:如果创建线程的时间超过该秒数,服务器增加Slow_launch_threads状态变量
* slow_query_log:是否打开日志记录
* slow_query_log_file:日志文件
mysql> set global slow_query_log='ON' 注:打开日志记录
一旦slow_query_log变量被设置为ON,mysql会立即开始记录
mysql> show status like '%slow%';
+---------------------+-------+
| Variable_name | Value |
+---------------------+-------+
| Slow_launch_threads | 0 |
| Slow_queries | 0 |
+---------------------+-------+
2 rows in set (0.00 sec)参数:
* Slow_launch_threads:The number of threads that have taken more than slow_launch_time seconds to create.
* Slow_queries:超过long_query_time时间的查询数量
相关参数:
* long_query_time:慢查询的时间标准。如果查询时间超过该值,则该sql会被记录下来。如果使用--log-slow-queries选项,则查询记入慢查询日志文件。用实际时间测量该值,而不是CPU时间,因此低于轻负载系统阈值的查询可能超过重负载系统的阈值。
其中,slow_launch_threads 值较大时,说明有些东西正在延迟链接的新线程。
把数个修改裹进一个事务里。如果事务对数据库修改,InnoDB在该事务提交时必须刷新日志到磁盘。因为磁盘旋转的速度至多167转/秒,如果磁盘没有骗操作系统的话,这就限制提交的数目为同样的每秒167次。
如果你可以接受损失一些最近的已提交事务,你可以设置my.cnf文件里的参数innodb_flush_log_at_trx_commit为0。 无论如何InnoDB试着每秒刷新一次日志,尽管刷新不被许可。
使用大的日志文件,让它甚至与缓冲池一样大。当InnoDB写满日志文件时,它不得不在一个检查点把缓冲池已修改的内容写进磁盘。小日志文件导致许多不必要的吸盘写操作。大日志文件的缺点时恢复时间更长。
也让日志缓冲相当大(与8MB相似的数量)。
3.1关注慢查询涉及的表的相关状态
1. 表内记录数。尽量控制在500万行以内(有索引),建议控制在200万行
2. 表内索引的使用。
3. 表如果update,delete,insert频繁,可以考虑optimize table优化下文件存放,索引,存储空间。
4. 表内update,insert,delete查询的锁定时间。
5. select for update如果条件字段无索引的话,会引起的是锁全表而不是行锁,请关注。
6. 如果查询包括GROUP BY但你想要避免排序结果的消耗,你可以指定ORDER BY NULL禁止排序。
3.2定期分析表
ANALYZE TABLE
语法:
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] …
本语句用于分析和存储表的关键字分布。在分析期间,使用一个读取锁定对表进行锁定。这对于MyISAM, BDB和InnoDB表有作用。对于MyISAM表,本语句与使用myisamchk -a相当。
CHECK TABLE
语法:
CHECK TABLE tbl_name [, tbl_name] … [option] …
option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
检查一个或多个表是否有错误。CHECK TABLE对MyISAM和InnoDB表有作用。对于MyISAM表,关键字统计数据被更新。
CHECK TABLE也可以检查视图是否有错误,比如在视图定义中被引用的表已不存在。
CHECKSUM TABLE
语法:
CHECKSUM TABLE tbl_name [, tbl_name] … [ QUICK | EXTENDED ]
报告一个表校验和。
3.3使用optimize table
OPTIMIZE TABLE
语法:
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] …
如果已经删除了表的一大部分,或者如果您已经对含有可变长度行的表(含有VARCHAR, BLOB或TEXT列的表)进行了很多更改,则应使用OPTIMIZE TABLE。被删除的记录被保持在链接清单中,后续的INSERT操作会重新使用旧的记录位置。您可以使用OPTIMIZE TABLE来重新利用未使用的空间,并整理数据文件的碎片。
OPTIMIZE TABLE只对MyISAM, BDB和InnoDB表起作用。
4.缓存簇
show status like 'key_blocks_u%'; -----使用和未使用缓存簇(blocks)数
show variables like '%Key_cache%';
show variables like '%Key_buffer_size%';mysql> show status like 'key_blocks_u%';
+-------------------+--------+
| Variable_name | Value |
+-------------------+--------+
| Key_blocks_unused | 213839 |
| Key_blocks_used | 503 |
+-------------------+--------+
2 rows in set (0.00 sec)
参数:* Key_blocks_unused 未使用的块数(key_buffer控制)
* Key_blocks_used 使用的块数
mysql> show variables like '%Key_cache%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| key_cache_age_threshold | 300 |
| key_cache_block_size | 1024 |
| key_cache_division_limit | 100 |
+--------------------------+-------+
3 rows in set (0.00 sec)
参数:* key_cache_age_threshold:该值控制将缓冲区从键值缓存热子链(sub-chain)降级到温子链(sub-chain)。如果值更低,则降级更快。最小值为100。 默认值是300。
* key_cache_block_size:键值缓存内块的字节大小。
* key_cache_division_limit:键值缓存缓冲区链热子链和温子链的划分点。该值为缓冲区链用于温子链的百分比。允许的值的范围为1到100。 默认值是100。
这三个参数都与MyISAM键高速缓冲相关。可以使用key_cache_block_size变量为具体的 键高速缓冲指定块缓存区的大小。这样允许为索引文件调节I/O操作的性能。
当读缓存区的大小等于原生操作系统I/O缓存区的大小时,可以获得I/O操作的最佳性能。但是将关键字节点的大小设置为等于I/O缓存区的大小并不总是能保证最佳整体性能。当读取大的叶节点时,服务器读入大量的不需要的数据,结果防止读入其它叶子的节点。
目前,你不能控制表内索引块的大小。该大小由服务器在创建.MYI索引文件时设置,取决于表定义中索引的关键字大小。在大多数情况下,它被设置为与I/O缓存区大小相等。
如果Key_blocks_used * key_cache_block_size 远小于key_buffer_size,那么就意味着内存被浪费了,应该调大key_buffer_size值。
默认情况,键高速缓冲管理系统采用LRU策略选择要收回的键高速缓冲块,但它也支持更复杂的方法,称之为“中点插入策略”。
当使用中点插入策略时,LRU链被分为两个部分:一条热子链和一条温子链。两部分之间的划分点不固定,但 键高速缓冲管理系统关注温部分不“太短”,总是包含至少key_cache_division_limit比例的 键高速缓冲块。key_cache_division_limit是结构式 键高速缓冲变量的一个组件,因此其值是一个可以根据每个缓存进行设置的参数。
当一个索引块从表中读入键高速缓冲,它被放入温子链的末端。经过一定量的访问后(访问块),它被提升给热子链。目前,需要用来提升一个块(3)的访问次数与所有索引块的相同。
提升到热子链的块被放到子链的末端。块然后在该子链中循环。如果块在子链的开头停留足够长的时间,它被降到温链。该时间由键高速缓冲key_cache_age_threshold组件的值确定。
对于包含N个块的 键高速缓冲,阈值表示,热子链开头的没有在最后N *key_cache_age_threshold/100次访问中被访问的块将被移动到温子链开头。该块然后变为第1个挤出的候选者,因为替换的块总是来自温子链的开头。
中点插入策略允许你将更有价值的块总是在缓存中。如果你想使用简单的LRU策略,使key_cache_division_limit值保持其默认值100。
若执行的查询要求索引扫描有效推出所有索引块对应有数值的高级B-树节点的缓存,中点插入策略可以帮助提高性能。要想避免,必须使用中点插入策略,而key_cache_division_limit设置为远小于100。然后在索引扫描操作过程中,有数值的经常访问的节点被保留在热子链中。
键高速缓冲可以通过更新其参数值随时重新构建。例如:
mysql> SET GLOBAL cold_cache。key_buffer_size=4*1024*1024;
如果你为key_buffer_size或key_cache_block_size键高速缓冲组件分配的值与组件当前的值不同,服务器将毁掉缓存的旧结构并根据新值创建一个新的。如果缓存包含任何脏的块,服务器在销毁前将它们保存到硬盘上并重新创建缓存。如果你设置其它 键高速缓冲参数,则不会发生重新构建。
当重新构建键高速缓冲时,服务器首先将任何脏缓存区的内容刷新到硬盘上。之后,缓存内容不再需要。然而,重新构建并不阻塞需要使用分配给缓存的索引的查询。相反,服务器使用原生文件系统缓存直接访问表索引。文件系统缓存不如使用 键高速缓冲有效,因此尽管查询可以执行,但速度会减慢。缓存被重新构建后,它又可以缓存分配给它的索引了,并且索引不再使用文件系统缓存。
5.键值缓存(索引块缓冲区)
mysql> show variables like 'key_buffer_size';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| key_buffer_size | 268435456 |
+-----------------+-----------+
1 row in set (0.00 sec)
参数:* key_buffer_size:MyISAM表的索引块分配了缓冲区,由所有线程共享。key_buffer_size是索引块缓冲区的大小。键值缓冲区即为键值缓存。
Key_buffer_size是MyISAM 存储引擎键高速缓存,对MyISAM表性能影响很大大。
mysql> show status like 'key_read%';
+-------------------+--------+
| Variable_name | Value |
+-------------------+--------+
| Key_read_requests | 115144 |
| Key_reads | 1311 |
+-------------------+--------+
2 rows in set (0.00 sec)参数:
* Key_read_requests:请求从缓存读入一个键值的次数(磁盘读取索引的请求次数)
* Key_reads:从硬盘读取键的数据块的次数
mysql> show status like 'key_write%';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| Key_write_requests | 0 |
| Key_writes | 0 |
+--------------------+-------+
2 rows in set (0.00 sec)
参数:
* Key_write_requests:将键的数据块写入缓存的请求数。
* Key_writes:向硬盘写入将键的数据块的物理写操作的次数。
key_buffer_size 参数用来设置用于缓存 MyISAM存储引擎中索引文件的内存区域大小。索引的缓存区,多线程共享,最大为4G,并且受到操作系统对每个进程使用RAM的限制,最好是设置为内存的25%。
增加该值,达到你可以提供的更好的索引处理(所有读和多个写操作)。通常为主要运行MySQL的机器内存的25%。但是,如果你将该值设得过大(例如,大于总内存的50%),系统将转换为页并变得极慢。MySQL依赖操作系统来执行数据读取时的文件系统缓存,因此你必须为文件系统缓存留一些空间。故注意:该参数值设置的过大反而会是服务器整体效率降低!
如果我们有足够的内存,这个缓存区域最好是能够存放下我们所有的 MyISAM 引擎表的所有索引,以尽可能提高性能。
此外,当我们在使用MyISAM 存储的时候有一个及其重要的点需要注意,由于 MyISAM 引擎的特性限制了他仅仅只会缓存索引块到内存中,而不会缓存表数据库块。理想情况下,对于这些块的请求应该来自于内存,而不是来自于磁盘。所以,我们的 SQL 一定要尽可能让过滤条件都在索引中,以便让缓存帮助我们提高查询效率。
只对MyISAM表起作用。即使你不使用MyISAM表,但是内部的临时磁盘表是MyISAM表,也要使用该值。
如果不使用MyISAM存储引擎,16MB足以,用来缓存一些系统表信息等。如果使用 MyISAM存储引擎,在内存允许的情况下,尽可能将所有索引放入内存。
合理设置key_buffer_size的方法:
你可以通过执行SHOW STATUS语句并检查Key_read_requests、Key_reads、Key_write_requests和Key_writes状态变量来检查键值缓冲区的性能。Key_reads 代表命中磁盘的请求个数, Key_read_requests 是总数。命中磁盘的读请求数除以读请求总数就是不中比率。如果每 1,000 个请求中命中磁盘的数目超过 1 个,就应该考虑增大关键字缓冲区了。
索引未命中缓存的概率=Key_reads / Key_read_requests * 100%
key_reads / key_read_requests的值应该尽可能的低,比如1:100,1:1000 ,1:10000。通常,Key_reads/Key_read_requests比例一般应小于0.01。
如果你使用更新和删除,Key_writes/Key_write_requests比例通常接近1,但如果你更新时会同时影响到多行或如果你正使用DELAY_KEY_WRITE表选项,可能小得多。同时写多行时要想速度更快,应使用LOCK TABLES。
注意,不能以Key_read_requests / Key_reads原则来设置key_buffer_size,因为在服务器刚启动的时候,大多数请求都要新建缓存,缓存命中比高不起来,需要运行稳定(几小时后) 再观察。但可以参考Key_reads 将这个值和系统的i/o做对比。
设置key_buffer_size值时,有人给出了一个简单的计算方法:不花很长时间在运行中调试,把数据库填满,达到设计时的最大值,看看这时候索引占了多大空间,然后把所有表的索引大小加起来,就是 key_buffer_size 可能达到的最大值,当然,还要留些余地,乘个 2 或 3 之类的。
设置key_buffer_size值,最关键的指标是key_blocks_unused(未使用的块数),只要还有剩余,就说明 key_buffer_size 没用满。
用key_buffer_size结合Key_blocks_unused状态变量和缓冲区块大小,可以确定使用的键值缓冲区的比例。从key_cache_block_size服务器变量可以获得缓冲区块大小。使用的缓冲区的比例为:
1 - ((Key_blocks_unused * key_cache_block_size) / key_buffer_size)
该值为约数,因为键值缓冲区的部分空间被分配用作内部管理结构。
可以创建多个MyISAM键值缓存。4GB限制可以适合每个缓存,而不是一个组。
对于内存在4GB左右的服务器该参数可设置为256M或384M。
每个连接到MySQL服务器的线程都需要有自己的缓冲,默认为其分配256K。事务开始之后,则需要增加更多的空间。运行较小的查询可能仅给指定的线程增加少量的内存消耗,例如存储查询语句的空间等。但如果对数据表做复杂的操作比较复杂,例如排序则需要使用临时表,此时会分配大约read_buffer_size,sort_buffer_size,read_rnd_buffer_size,tmp_table_size大小的内存空间。不过它们只是在需要的时候才分配,并且在那些操作做完之后就释放了。
MyISAM键高速缓冲
为了使硬盘I/O最小化,MyISAM存储引擎使用一个被许多数据库管理系统使用的策略。它使用一个缓存机制将经常访问的表锁在内存中:
· 对于索引块,维护一个称之为键高速缓冲(或键高速缓冲区)的特殊结构。该结构包含大量块缓存区,其中放置了最常用的索引块。
· 对于数据块,MySQL不使用特殊缓存。而使用原生的操作系统文件系统的缓存。
本节首先描述了MyISAM键高速缓冲的基本操作。然后讨论了提高 键高速缓冲性能并使你更好地控制缓存操作的最新的更改:
· 多个线程可以并行访问缓存。
· 可以设置多个键高速缓冲,并将表索引指定给具体缓存。
可以使用key_buffer_size系统变量控制 键高速缓冲的大小。如果该变量设置为零,不使用键高速缓冲。如果key_buffer_size值太小不能分配最小数量的块缓存区(8),也不使用 键高速缓冲。
如果键高速缓冲不工作,只使用操作系统提供的原生文件系统缓存区访问索引文件。(换句话说,使用与表数据块相同的策略表来访问索引块)。
索引块是一个连续的访问MyISAM索引文件的单位。通常一个索引块的大小等于索引B-树节点的大小。(在硬盘上使用B-树数据结构表示索引。树底部的节点为叶子节点。叶子节点上面的节点为非叶子节点)。
键高速缓冲结构中的所有块缓存区大小相同。该大小可以等于、大于或小于表索引块的大小。通常这两个值中的一个是另一个的几倍。
当必须访问表索引块中的数据时,服务器首先检查是否它可以用于键高速缓冲中的某些块缓存区。如果适用,服务器访问键高速缓冲中的数据而不是硬盘上的数据。也就是说,从缓存读取或写入缓存,而不是从硬盘读写。否则,服务器选择一个包含一个不同的表索引块的缓存块缓存区,并用需要的表索引块的拷贝替换那里的数据。一旦新的索引块位于缓存中,可以访问索引数据。
如果用于替换的块已经被修改了,块被视为“脏了”。在这种情况下,在替换前,其内容被刷新到它来自的表索引。
通常服务器遵从LRU(最近最少使用)策略:当选择一个块用于替换时,它选择最近最少使用的索引块。为了使该选择更容易, 键高速缓冲模块维护所有使用的块的专门队列(LRU链)。当访问块时,它被放到队列最后。当块需要替换时,队列开头的块是最近最少使用的块,并成为第1个候选者。
共享键高速缓冲访问
在以下条件下,线程可以同时访问键高速缓冲缓存区:
· 没有被更新的缓存区可以被多个线程访问。
· 正被更新的缓存区让需要使用它的线程等待直到更新完成。
· 多个线程可以发起请求替换缓存块,只要它们不彼此干扰(也就是说,只要它们需要不同的索引块,并且使不同的缓存块被替换)。
对键高速缓冲的共享访问允许服务器大大提高吞吐量。
多键高速缓冲
对键高速缓冲的共享访问可以提高性能但不能完全消除线程之间的竟争。它们仍然竞争对键高速缓冲缓存区的访问进行管理的控制结构。为了进一步降低 键高速缓冲访问竟争,MySQL 5.1还提供了多个键高速缓冲,允许你为不同的键高速缓冲分配不同的表索引。
有多个键高速缓冲时,当为给定的MyISAM表处理查询时,服务器必须知道使用哪个缓存。默认情况,所有MyISAM表索引被缓存到默认 键高速缓冲中。要想为具体键高速缓冲分配表索引,应使用CACHE INDEX语句(参见13.5.5.1节,“CACHE INDEX语法”)。
例如,下面的语句将表t1、t2和t3的索引分配给名为hot_cache的 键高速缓冲:
mysql> CACHE INDEX t1, t2, t3 IN hot_cache;
+---------+--------------------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+---------+--------------------+----------+----------+
| test.t1 | assign_to_keycache | status | OK |
| test.t2 | assign_to_keycache | status | OK |
| test.t3 | assign_to_keycache | status | OK |
+---------+--------------------+----------+----------+
可以用SET GLOBAL参数设置语句或使用服务器启动选项设置在CACHE INDEX语句中引用的键高速缓冲的大小来创建键高速缓冲。例如:
mysql> SET GLOBAL keycache1.key_buffer_size=128*1024;
要想删除键高速缓冲,将其大小设置为零:
mysql> SET GLOBAL keycache1.key_buffer_size=0;
请注意不能删除默认键高速缓冲。删除默认键高速缓冲的尝试将被忽略:
mysql> set global key_buffer_size = 0;
mysql> show variables like 'key_buffer_size';
+-----------------+---------+
| Variable_name | Value |
+-----------------+---------+
| key_buffer_size | 8384512 |
+-----------------+---------+
键高速缓冲变量是结构式系统变量,有一个名和组件。对于keycache1.key_buffer_size,keycache1是缓存变量名,key_buffer_size是缓存组件。关于引用结构式 键高速缓冲系统变量所使用的语法的描述,参见9.4.1节,“结构式系统变量”
默认情况下,表索引被分配给服务器启动时创建的主要(默认)键高速缓冲。当 键高速缓冲被删除后,所有分配给它的索引被重新分配给默认键高速缓冲。
对于一个忙的服务器,我们建议采用使用三个键高速缓冲的策略:
· 占用为所有键高速缓冲分配的空间的20%的“热”键高速缓冲。该缓存用于频繁用于搜索但没有更新的表。
· 占用为所有键高速缓冲分配的空间的20%的“冷”键高速缓冲。该缓存用于中等大小、大量修改的表,例如临时表。
· 占用键高速缓冲空间的20%的“温”键高速缓冲。使用它作为默认 键高速缓冲,默认情况被所有其它表使用。
使用3个键高速缓冲有好处的一个原因是对一个键高速缓冲结构的访问不会阻挡对其它的访问。访问分配给一个缓存的表的查询不会与访问分配给其它缓存的表的查询竞争。由于其它原因也会提高性能:
· 热缓存只用于检索查询,因此其内容决不会被修改。结果是,无论何时需要从硬盘上拉入索引块,选择用于替换的缓存块的内容不需要先刷新。
· 对于分配给热缓存的索引,如果没有查询需要索引扫描,很有可能对应索引B-树的非叶子节点的索引块仍然在缓存中。
· 当更新的节点位于缓存中并且不需要先从硬盘读入时,为临时表频繁执行的更新操作会执行得更快。如果临时表的索引的大小可以与冷键高速缓冲相比较,很可能更新的节点位于缓存中。
CACHE INDEX在一个表和 键高速缓冲之间建立一种联系,但每次服务器重启时该联系被丢失。如果你想要每次服务器重启时该联系生效,一个发办法是使用选项文件:包括配置 键高速缓冲的变量设定值,和一个init-file选项用来命名包含待执行的CACHE INDEX语句的一个文件。例如:
key_buffer_size = 4G
hot_cache.key_buffer_size = 2G
cold_cache.key_buffer_size = 2G
init_file=/path/to/data-directory/mysqld_init.sql
每次服务器启动时执行mysqld_init.sql中的语句。该文件每行应包含一个SQL语句。下面的例子分配几个表,分别对应hot_cache和cold_cache:
CACHE INDEX a.t1, a.t2, b.t3 IN hot_cache
CACHE INDEX a.t4, b.t5, b.t6 IN cold_cache
中点插入策略
默认情况,键高速缓冲管理系统采用LRU策略选择要收回的键高速缓冲块,但它也支持更复杂的方法,称之为“中点插入策略”。
当使用中点插入策略时,LRU链被分为两个部分:一条热子链和一条温子链。两部分之间的划分点不固定,但 键高速缓冲管理系统关注温部分不“太短”,总是包含至少key_cache_division_limit比例的 键高速缓冲块。key_cache_division_limit是结构式 键高速缓冲变量的一个组件,因此其值是一个可以根据每个缓存进行设置的参数。
当一个索引块从表中读入键高速缓冲,它被放入温子链的末端。经过一定量的访问后(访问块),它被提升给热子链。目前,需要用来提升一个块(3)的访问次数与所有索引块的相同。
提升到热子链的块被放到子链的末端。块然后在该子链中循环。如果块在子链的开头停留足够长的时间,它被降到温链。该时间由键高速缓冲key_cache_age_threshold组件的值确定。
对于包含N个块的 键高速缓冲,阈值表示,热子链开头的没有在最后N*key_cache_age_threshold/100次访问中被访问的块将被移动到温子链开头。该块然后变为第1个挤出的候选者,因为替换的块总是来自温子链的开头。
中点插入策略允许你将更有价值的块总是在缓存中。如果你想使用简单的LRU策略,使key_cache_division_limit值保持其默认值100。
若执行的查询要求索引扫描有效推出所有索引块对应有数值的高级B-树节点的缓存,中点插入策略可以帮助提高性能。要想避免,必须使用中点插入策略,而key_cache_division_limit设置为远小于100。然后在索引扫描操作过程中,有数值的经常访问的节点被保留在热子链中。
索引预加载
如果键高速缓冲内有足够的块以容纳整个索引的块,或者至少容纳对应其非叶节点的块,则在使用前,预装含索引块的键高速缓冲很有意义。预装可以以更有效的方式将表索引块放入 键高速缓冲缓存区中:通过顺序地从硬盘读取索引块。
不进行预装,块仍然根据查询需要放入键高速缓冲中。尽管块将仍然在缓存中(因为有足够的缓存区保存它们),它们以随机方式从硬盘上索取,而不是以顺序方式。
要想将索引预装到缓存中,使用LOAD INDEX INTO CACHE语句。例如,下面的语句可以预装表t1和t2索引的节点(索引块):
mysql> LOAD INDEX INTO CACHE t1, t2 IGNORE LEAVES;
+---------+--------------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+---------+--------------+----------+----------+
| test.t1 | preload_keys | status | OK |
| test.t2 | preload_keys | status | OK |
+---------+--------------+----------+----------+
IGNORE LEAVES修改器只允许预装索引非叶节点所用的块。这样,上述的语句预装t1中的所有索引块,但只预装t2中的非叶节点对应的块。
如果已经使用CACHE INDEX语句为一个索引分配了一个键高速缓冲,预装可以将索引块放入该缓存。否则,索引被装入默认键高速缓冲。
键高速缓冲块大小
可以使用key_cache_block_size变量为具体的 键高速缓冲指定块缓存区的大小。这样允许为索引文件调节I/O操作的性能。
当读缓存区的大小等于原生操作系统I/O缓存区的大小时,可以获得I/O操作的最佳性能。但是将关键字节点的大小设置为等于I/O缓存区的大小并不总是能保证最佳整体性能。当读取大的叶节点时,服务器读入大量的不需要的数据,结果防止读入其它叶子的节点。
目前,你不能控制表内索引块的大小。该大小由服务器在创建.MYI索引文件时设置,取决于表定义中索引的关键字大小。在大多数情况下,它被设置为与I/O缓存区大小相等。
重构键高速缓冲
键高速缓冲可以通过更新其参数值随时重新构建。例如:
mysql> SET GLOBAL cold_cache。key_buffer_size=4*1024*1024;
如果你为key_buffer_size或key_cache_block_size键高速缓冲组件分配的值与组件当前的值不同,服务器将毁掉缓存的旧结构并根据新值创建一个新的。如果缓存包含任何脏的块,服务器在销毁前将它们保存到硬盘上并重新创建缓存。如果你设置其它 键高速缓冲参数,则不会发生重新构建。
当重新构建键高速缓冲时,服务器首先将任何脏缓存区的内容刷新到硬盘上。之后,缓存内容不再需要。然而,重新构建并不阻塞需要使用分配给缓存的索引的查询。相反,服务器使用原生文件系统缓存直接访问表索引。文件系统缓存不如使用 键高速缓冲有效,因此尽管查询可以执行,但速度会减慢。缓存被重新构建后,它又可以缓存分配给它的索引了,并且索引不再使用文件系统缓存。
6.查询缓存
很多应用程序都严重依赖于数据库,但却会反复执行相同的查询。每次执行查询时,数据库都必须要执行相同的工作 —— 对查询进行分析,确定如何执行查询,从磁盘中加载信息,然后将结果返回给客户机。MySQL 有一个特性称为查询缓存,查询缓存会存储一个 SELECT 查询的文本与被传送到客户端的相应结果。如果之后接收到一个同样的查询,服务器将从查询缓存中检索结果,而不是再次分析和执行这个同样的查询。在很多情况下,这会极大地提高性能。不过,问题是查询缓存在默认情况下是禁用的。
如果你有一个不经常改变的表并且服务器收到该表的大量相同查询,查询缓存在这样的应用环境中十分有用。对于许多Web服务器来说存在这种典型情况,它根据数据库内容生成大量的动态页面。
注释:查询缓存不返回旧的数据。当表更改后,查询缓存值的相关条目被清空。
注释:如果你有许多mysqld服务器更新相同的MyISAM表,在这种情况下查询缓存不起作用。
注释:查询缓存不适用于服务器方编写的语句。如果正在使用服务器方编写的语句,要考虑到这些语句将不会应用查询缓存。
• 如果执行的所有查询是简单的(如从只有一行数据的表中选取一行),但查询是不同的,查询不能被缓存,查询缓存激活率是13%。这可以看作是最坏的情形。在实际应用中,查询要复杂得多,因此,查询缓存使用率一般会很低。
• 从只有一行的表中查找一行数据时,使用查询缓存比不使用速度快238%。这可以看作查询使用缓存时速度提高最小的情况。
服务器启动时要禁用查询缓存,设置query_cache_size系统变量为0。禁用查询缓存代码后,没有明显的速度提高。编译MySQL时,通过在configure中使用--without-query-cache选项,可以从服务器中彻底去除查询缓存能力。
mysql> show variables like 'have_query_cache';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| have_query_cache | YES |
+------------------+-------+
1 row in set (0.00 sec)
参数:
* hava_query_cache:指示查询缓存是否可用
mysql> show variables like 'query_cache%';
+------------------------------+-----------+
| Variable_name | Value |
+------------------------------+-----------+
| query_cache_limit | 2097152 |
| query_cache_min_res_unit | 2048 |
| query_cache_size | 536870912 |
| query_cache_type | ON |
| query_cache_wlock_invalidate | OFF |
+------------------------------+-----------+
5 rows in set (0.00 sec)参数:
* query_cache_limit:指定单个查询能够使用的缓冲区大小,缺省为1M,不缓存大于该值的结果。即控制可以被缓存的具体查询结果的最大值。
* query_cache_type :查询缓存类型。设置GLOBAL值可以设置后面的所有客户端连接的类型。客户端可以设置SESSION值以影响他们自己对查询缓存的使用。这个变量可以设置为下面的值:(如果查询缓存大小设置为大于0,query_cache_type变量影响其工作方式。)
0 或OFF 不缓存查询结果。
1 或ON 将允许缓存,以SELECT SQL_NO_CACHE 开始的查询语句除外。
2 或DEMAND , 仅对以SELECT SQL_CACHE 开始的那些查询语句启用缓存。
如果全部使用innodb存储引擎,建议为0,如果使用MyISAM 存储引擎,建议为2
* query_cache_min_res_unit:指定分配缓冲区空间的最小单位,缺省为4K。检查状态值Qcache_free_blocks,如果该值非常大,则表明缓冲区中碎片很多,这就表明查询结果都比较小,此时需要减小query_cache_min_res_unit。
* query_cache_size:为缓存查询结果分配的内存的数量(以字节指定) 。如果设置它为 0 ,查询缓冲将被禁止(缺省值为 0 )。请注意即使query_cache_type设置为0也将分配此数量的内存。* query_cache_wlock_invalidate:一般情况,当客户端对MyISAM表进行WRITE锁定时,如果查询结果位于查询缓存中,则其它客户端未被锁定,可以对该表进行查询。将该变量设置为1,则可以对表进行WRITE锁定,使查询缓存内所有对该表进行的查询变得非法。这样当锁定生效时,可以强制其它试图访问表的客户端来等待。(当有其他客户端正在对MyISAM表进行写操作时,如果查询在query cache中,是否返回cache结果还是等写操作完成再读表获取结果。)
相关参数:
* query_prealloc_size:用于查询分析和执行的固定缓冲区的大小。在查询之间该缓冲区不释放。如果你执行复杂查询,分配更大的query_prealloc_size值可以帮助提高性能,因为它可以降低查询过程中服务器分配内存的需求。
mysql> show status like 'qcache%';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| Qcache_free_blocks | 5216 |
| Qcache_free_memory | 14640664 |
| Qcache_hits | 2581646882|
| Qcache_inserts | 360210964 |
| Qcache_lowmem_prunes | 281680433 |
| Qcache_not_cached | 79740667 |
| Qcache_queries_in_cache | 16927 |
| Qcache_total_blocks | 47042|
+-------------------------+-----------+
8 rows in set (0.00 sec)参数:
* Qcache_free_blocks:缓存中相邻内存块的个数。数目大说明可能有碎片。FLUSH QUERY CACHE 会对缓存中的碎片进行整理,从而得到一个空闲块。
* Qcache_free_memory:缓存中的空闲内存。
* Qcache_hits:每次查询在缓存中命中时就增大。
* Qcache_inserts:每次插入一个查询时就增大。 未命中然后插入。
* Qcache_lowmem_prunes:的值非常大,则表明经常出现缓冲不够的情况。同时Qcache_hits的值非常大,则表明查询缓冲使用非常频繁,此时需要增加缓冲大小,Qcache_hits的值不大,则表明你的查询重复率很低,这种情况下使用查询缓冲反而会影响效率,那么可以考虑不用查询缓冲。这个数字最好长时间来看;如果这个数字在不断增长,就表示可能碎片非常严重,或者内存很少。(上面的 free_blocks 和 free_memory 可以告诉您属于哪种情况)。
* Qcache_not_cached: 不适合进行缓存的查询的数量,通常是由于这些查询不是 SELECT 语句。* Qcache_queries_in_cache: 当前缓存的查询(和响应)的数量。
* Qcache_total_blocks:缓存中块的数量。
Total number of queries = Qcache_inserts + Qcache_hits + Qcache_not_cached.
查询命中率 = Qcache_hits - Qcache_inserts / Qcache_hits
查询插入率 = Qcache_inserts / Com_select;
未插入率 = Qcache_not_cached / Com_select;Query cache 作用于整个 MySQL Instance,主要用来缓存 MySQL 中的 ResultSet,也就是一条SQL语句执行的结果集,所以仅仅只能针对select语句。
当我们打开了 Query Cache 功能,MySQL在接受到一条select语句的请求后,如果该语句满足Query Cache的要求(未显式说明不允许使用Query Cache,或者已经显式申明需要使用Query Cache),MySQL 会直接根据预先设定好的HASH算法将接受到的select语句以字符串方式进行hash,然后到Query Cache 中直接查找是否已经缓存。也就是说,如果已经在缓存中,该select请求就会直接将数据返回,从而省略了后面所有的步骤(如 SQL语句的解析,优化器优化以及向存储引擎请求数据等),极大的提高性能。
Query Cache 也有一个致命的缺陷,那就是当某个表的数据有任何任何变化,都会导致所有引用了该表的select语句在Query Cache 中的缓存数据失效。所以,当我们的数据变化非常频繁的情况下,使用Query Cache 可能会得不偿失。
Query Cache中最为关键参数是 query_cache_size 和 query_cache_type ,前者设置用于缓存 ResultSet 的内存大小,后者设置在何场景下使用 Query Cache。
如何合理设置Query_cache_size值:
query_cache_size 一般 256MB 是一个比较合适的大小。当然,可以通过计算Query Cache的命中率来进行调整。
Query Cache的合中率:Qcache_hits / (Qcache_hits + Qcache_inserts) * 100)
一般不建议太大,256MB可能已经差不多了,大型的配置型静态数据可适当调大。
当设置query_cache_size变量为非零值时,应记住查询缓存至少大约需要40KB来分配其数据结构。(具体大小取决于系统结构)。如果你把该值设置的太小,将会得到一个警告,如本例所示:
mysql> SET GLOBAL query_cache_size = 40000;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Warning
Code: 1282
Message: Query cache failed to set size 39936; new query cache size is 0
当一个查询结果(返回给客户端的数据)从查询缓冲中提取期间,它在查询缓存中排序。因此,数据通常不在大的数据块中处理。查询缓存根据数据排序要求分配数据块,因此,当一个数据块用完后分配一个新的数据块。因为内存分配操作是昂贵的(费时的),所以通过query_cache_min_res_unit系统变量给查询缓存分配最小值。当查询执行时,最新的结果数据块根据实际数据大小来确定,因此可以释放不使用的内存。根据你的服务器执行查询的类型,你会发现调整query_cache_min_res_unit变量的值是有用的:
query_cache_min_res_unit默认值是4KB。这应该适合大部分情况。
如果你有大量返回小结果数据的查询,默认数据块大小可能会导致内存碎片,显示为大量空闲内存块。由于缺少内存,内存碎片会强制查询缓存从缓存内存中修整(删除)查询。这时,你应该减少query_cache_min_res_unit变量的值。空闲块和由于修整而移出的查询的数量通过Qcache_free_blocks和Qcache_lowmem_prunes变量的值给出。
如果大量查询返回大结果(检查 Qcache_total_blocks和Qcache_queries_in_cache状态变量),你可以通过增加query_cache_min_res_unit变量的值来提高性能。但是,注意不要使它变得太大(参见前面的条目)。
通常,间隔几秒显示这些变量就可以看出区别,这可以帮助确定缓存是否正在有效地使用。运行 FLUSH STATUS 可以重置一些计数器,如果服务器已经运行了一段时间,这会非常有帮助。
使用非常大的查询缓存,期望可以缓存所有东西,这种想法非常诱人。但如果表有变动时,首先要把Query_cache和该表相关的语句全部置为失效,然后在写入更新。
那么如果Query_cache非常大,该表的查询结构又比较多,查询语句失效也慢,一个更新或是Insert就会很慢,这样看到的就是Update或是Insert怎么这么慢了。
所以在数据库写入量或是更新量也比较大的系统,该参数不适合分配过大。而且在高并发,写入量大的系统,建系把该功能禁掉。
作为一条规则,如果 FLUSH QUERY CACHE 占用了很长时间,那就说明缓存太大了。
查询高速缓冲状态和维护
可以使用下面的语句检查MySQL服务器是否提供查询缓存功能:
mysql> SHOW VARIABLES LIKE 'have_query_cache';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| have_query_cache | YES |
+------------------+-------+
可以使用FLUSH QUERY CACHE语句来清理查询缓存碎片以提高内存使用性能。该语句不从缓存中移出任何查询。
RESET QUERY CACHE语句从查询缓存中移出所有查询。FLUSH TABLES语句也执行同样的工作。
为了监视查询缓存性能,使用SHOW STATUS查看缓存状态变量:
mysql> SHOW STATUS LIKE 'Qcache%';
+-------------------------+--------+
|变量名 |值 |
+-------------------------+--------+
| Qcache_free_blocks | 36 |
| Qcache_free_memory | 138488 |
| Qcache_hits | 79570 |
| Qcache_inserts | 27087 |
| Qcache_lowmem_prunes | 3114 |
| Qcache_not_cached | 22989 |
| Qcache_queries_in_cache | 415 |
| Qcache_total_blocks | 912 |
+-------------------------+--------+
SELECT查询的总数量等价于:
Com_select + Qcache_hits + queries with errors found by parser
Com_select的值等价于:
Qcache_inserts + Qcache_not_cached + queries with errors found during columns/rights check
查询缓存使用长度可变块,因此Qcache_total_blocks和Qcache_free_blocks可以显示查询缓存内存碎片。执行FLUSH QUERY CACHE后,只保留一个空闲块。
每个缓存查询至少需要两个块(一个块用于查询文本,一个或多个块用于查询结果)。并且,每一个查询使用的每个表需要一个块。但是,如果两个或多个查询使用相同的表,仅需要分配一个块。
Qcache_lowmem_prunes状态变量提供的信息能够帮助你你调整查询缓存的大小。它计算为了缓存新的查询而从查询缓冲区中移出到自由内存中的查询的数目。查询缓冲区使用最近最少使用(LRU)策略来确定哪些查询从缓冲区中移出。
查询高速缓冲的工作原理
查询解析之前进行比较,因此下面的两个查询被查询缓存认为是不相同的:
SELECT * FROM tbl_name
Select * from tbl_name
查询必须是完全相同的(逐字节相同)才能够被认为是相同的。另外,同样的查询字符串由于其它原因可能认为是不同的。使用不同的数据库、不同的协议版本或者不同 默认字符集的查询被认为是不同的查询并且分别进行缓存。
从查询缓存中提取一个查询之前,MySQL检查用户对所有相关数据库和表的SELECT权限。如果没有权限,不使用缓存结果。
如果从查询缓存中返回一个查询结果,服务器把Qcache_hits状态变量的值加一,而不是Com_select变量。参见5.13.4节,“查询高速缓冲状态和维护”。
如果一个表被更改了,那么使用那个表的所有缓冲查询将不再有效,并且从缓冲区中移出。这包括那些映射到改变了的表的使用MERGE表的查询。一个表可以被许多类型的语句更改,例如INSERT、UPDATE、DELETE、TRUNCATE、ALTER TABLE、DROP TABLE或DROP DATABASE。
COMMIT执行完后,被更改的事务InnoDB表不再有效。
使用InnoDB表时,查询缓存也在事务中工作,使用该表的版本号来检测其内容是否仍旧是当前的。
在MySQL 5.1中,视图产生的查询被缓存。
SELECT SQL_CALC_FOUND_ROWS ...和SELECT FOUND_ROWS() type类型的查询使用查询缓存。即使因创建的行数也被保存在缓冲区内,前面的查询从缓存中提取,FOUND_ROWS()也返回正确的值。
如果一个查询包含下面函数中的任何一个,它不会被缓存:
BENCHMARK() CONNECTION_ID() CURDATE()
CURRENT_DATE() CURRENT_TIME() CURRENT_TIMESTAMP()
CURTIME() DATABASE() 带一个参数的ENCRYPT()
FOUND_ROWS() GET_LOCK() LAST_INSERT_ID()
LOAD_FILE() MASTER_POS_WAIT() NOW()
RAND() RELEASE_LOCK() SYSDATE()
不带参数的UNIX_TIMESTAMP() USER()
在下面的这些条件下,查询也不会被缓存:
• 引用自定义函数(UDFs)。
• 引用自定义变量。
• 引用mysql系统数据库中的表。
• 下面方式中的任何一种:
SELECT ...IN SHARE MODE
SELECT ...FOR UPDATE
SELECT ...INTO OUTFILE ...
SELECT ...INTO DUMPFILE ...
SELECT * FROM ...WHERE autoincrement_col IS NULL
最后一种方式不能被缓存是因为它被用作为ODBC工作区来获取最近插入的ID值。参见26.1.14.1节,“如何在ODBC中获取AUTO_INCREMENT列的值”。
• 被作为编写好的语句,即使没有使用占位符。例如,下面使用的查询:
char *my_sql_stmt = "SELECT a,b FROM table_c";
/* ...*/
mysql_stmt_prepare(stmt,my_sql_stmt,strlen(my_sql_stmt));
不被缓存。参见25.2.4节,“C API预处理语句”。
• 使用TEMPORARY表。
• 不使用任何表。
• 用户有某个表的列级权限。
7.线程使用情况
mysql> show status like 'Thread%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 4 |
| Threads_connected | 1 |
| Threads_created | 5 |
| Threads_running | 1 |
+-------------------+-------+
4 rows in set (0.00 sec)参数:
* Threads_cached:线程缓存内的线程数
* Threads_connected:当前打开的连接的数量
* Threads_created:创建用来处理连接的线程数。
* Threads_running:激活的(非睡眠状态)线程数。
mysql> show variables like 'thread%';
+-------------------+---------------------------+
| Variable_name | Value |
+-------------------+---------------------------+
| thread_cache_size | 8 |
| thread_handling | one-thread-per-connection |
| thread_stack | 196608 |
+-------------------+---------------------------+
3 rows in set (0.00 sec)
参数:
* thread_cache_size:可以复用的保存在中的线程的数量。如果有,新的线程从缓存中取得,当断开连接的时候如果有空间,客户的线置在缓存中。
* thread_handling:
* thread_stack:每个线程的堆栈大小,用crash-me测试检测出的许多限制取决于该值。 默认值足够大,可以满足普通操作。
线程缓存:mysqld 在接收连接时会根据需要生成线程。在一个连接变化很快的繁忙服务器上,对线程进行缓存便于以后使用可以加快最初的连接。
当客户端断开连接时,如果线程少于thread_cache_size,则客户端的线程被放入缓存。当请求线程时如果允许可以从缓存中重新利用线程,并且只有当缓存空了时才会创建新线程。如果新连接很多,可以增加该变量以提高性能。(一般情况,如果线程执行得很好,性能提高不明显)。检查Connections和Threads_created状态变量的差,你可以看见线程缓存的效率。
此处重要的值是 Threads_created,每次 mysqld 需要创建一个新线程时,这个值都会增加。如果这个数字在连续执行 SHOW STATUS 命令时快速增加,就应该尝试增大thread_cache_size值。缓存访问率的计算方法 Threads_created(新建的线程)/Connections(只要有线程连接,该值就增加)。
服务器应缓存多少线程以便重新使用。当客户端断开连接时,如果线程少于thread_cache_size,则客户端的线程被放入缓存,一般配置8。
每个连接到MySQL服务器的线程都需要有自己的缓冲,默认为其分配256K。事务开始之后,则需要增加更多的空间。运行较小的查询可能仅给指定的线程增加少量的内存消耗,例如存储查询语句的空间等。但如果对数据表做复杂的操作比较复杂,例如排序则需要使用临时表,此时会分配大约read_buffer_size,sort_buffer_size,read_rnd_buffer_size,tmp_table_size大小的内存空间。不过它们只是在需要的时候才分配,并且在那些操作做完之后就释放了。
8.打开的文件数
mysql> show status like '%open%file%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Open_files | 1 |
| Opened_files | 58 |
+---------------+-------+
2 rows in set (0.00 sec)
参数:
* Open_files:打开文件的个数,这个统计是服务器打开的正规文件的个数。不包括socket 及pipe。当打开myisam表数据时,他会增加两个(数据文件与索引文件),当打开innodb表时,该值不增加,当打开的myisam表已另一个别名打开时,Open_files只会增加一个。flush tables 会清空该值。
* Opened_files:当增加Open_files同时,他会已同样大小增加该值。当table_open_cache增加,或者flush tables 时,该值是不会减少,但也不增加的。
相关参数:
* Open_streams:打开流的数量(主要用于日志记载)
mysql> show variables like '%open_file%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| innodb_open_files | 300 |
| open_files_limit | 25000 |
+-------------------+-------+
2 rows in set (0.00 sec)参数:
* open_files_limit:操作系统允许mysqld打开的文件的数量。这是系统允许的实际值,可能与你在启动选项中赋给mysqld的值不同。若在系统中MySQL不能更改打开的文件的数量,则该值为0。
mysql打开的最大文件数,受两个参数的影响:系统打开的最大文件数(ulimit -n)和 open_files_limit 。
不过mysql打开的文件描述符限制都是OS的文件描述符限制,和配置文件中open_files_limit的设置没有关系。如果Open_files和open_files_limit接近,就应该增加open_files_limit的大小。
增加mysql打开的最大文件数,最好用sysctl或者修改/etc/sysctl.conf文件,同时还要在配置文件中把open_files_limit这个参数增大,对于4G内存服务器,open_files_limit至少要增大到4096,非特殊情况,设置成8192就可以了。
-------------------------------------------------------------
在/etc/my.cnf加入open_files_limit=8192
在/etc/security/limits.conf添加
* soft nofile 8192
* hard nofile 8192
--------------------------------------------------------------------9.打开表情况
mysql> show status like 'open%tables%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Open_tables | 95 |
| Opened_tables | 0 |
+---------------+-------+
2 rows in set (0.00 sec)参数:
* Open_tables:当前打开的表的数量。
* Opened_tables:已经打开的表的数量。
mysql> show variables like 'table%cache%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| table_definition_cache | 256 |
| table_open_cache | 256 |
+------------------------+-------+
2 rows in set (0.01 sec)
参数:
* table_definition_cache:
* table_open_cache:表高速缓存的数目。
mysql> show variables like 'open%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| open_files_limit | 622 |
+------------------+-------+
1 row in set (0.00 sec)
参数:
* open_files_limit:操作系统允许mysqld打开的文件的数量。
表缓存的说明:
当 Mysql 访问一个表时,如果该表在缓存中已经被打开,则可以直接访问缓存;如果还没有被缓存,但是在 Mysql 表缓冲区中还有空间,那么这个表就被打开并放入表缓冲区;如果表缓存满了,则会按照一定的规则将当前未用的表释放,或者临时扩大表缓存来存放,使用表缓存的好处是可以更快速地访问表中的内容。
每个连接进来,都会至少打开一个表缓存。因此, table_open_cache 的大小应与 max_connections 的设置有关。例如,对于 200 个并行运行的连接,应该让表的缓存至少有 200 × N ,这里N是可以执行的查询的一个联接中表的最大数量。几个参数的关系:
table_open_cache * 2 + max_connections=max_open_files
每个线程会独自持有一个数据文件的文件描述符,而索引文件的文件描述符是公用的。当table cache不够用的时候,MySQL会采用LRU算法踢掉最长时间没有使用的表。如果table_cache设置过小,MySQL就会反复打开、关闭 frm文件,造成一定的性能损失。如果table_cache设置过大,MySQL将会消耗很多CPU去做 table cache的算法运算。
而InnoDB的元数据管理是放在共享表空间里面做的,所以获取表的结构不需要去反复解析frm文件,这是比MyISAM强的地方。即使 table_cache设置过小,对于InnoDB的影响也是很小的,因为它根本不需要反复打开、关闭frm文件去获取元数据。
table_open_cache是所有线程打开的表的数目(一个表使用2个文件描述符),表数量多,就要大一些。增大该值可以增加mysqld需要的文件描述符的数量。根据数据库系统中表数量来决定该值,如2048。
合理设置table_open_cache的大小:
通过查看open_tables,opened_tables,flush tables 的值来比较,察看当前的表缓存情况。
清空表缓存:mysql> flush tables;
如果 open_tables接近table_open_cache的时候,并且Opened_tables这个值在逐步增加,说明table_cache不够用,表缓存没有完全用上,那就要考虑增加table_cache的大小了。还有就是Table_locks_waited比较高的时候,也需要增加table_cache如果发现 open_tables 接近 table_cache 的时候,如果 Opened_tables 随着重新运行 SHOW STATUS 命令快速增加,就说明缓存命中率不够,并且多次执行FLUSH TABLES(通过shell > mysqladmin -uroot -ppassword variables status ),那就说明可能 table_cache 设置的偏小,经常需要将缓存的表清出,将新的表放入缓存,这时可以考虑增加这个参数的大小来改善访问的效率。
如果 Open_tables 比 table_open_cache 设置小很多,就说明table_cache 设的太大了。
table_open_cache的值在2G内存以下的机器中的值默认时256到512,如果机器有4G内存则默认这个值是2048,但这决意味着机器内存越大,这个值应该越大,因为table_open_cache加大后,使得mysql对SQL响应的速度更快了,不可避免的会产生更多的死锁(dead lock),这样反而使得数据库整个一套操作慢了下来,严重影响性能。
注意,不能盲目地把table_open_cache设置成很大的值。如果设置得太高,可能会造成文件描述符不足,从而造成性能不稳定或者连接失败。
对于有1G内存的机器,推荐值是128-256。
MySQL如何打开和关闭表
table_cache、max_connections和max_tmp_tables系统变量影响服务器保持打开的文件的最大数量。如果你增加这些值其中的一个或两个,会遇到操作系统为每个进程打开文件描述符的数量强加的限制。许多操作系统允许你增加打开的文件的限制,尽管该方法随系统的不同而不同。查阅操作系统文档以确定是否可以增加限制以及如何操作。
table_cache与max_connections有关。例如,对于200个并行运行的连接,应该让表的缓存至少有200 * N,这里N是可以执行的查询的一个联接中表的最大数量。还需要为临时表和文件保留一些额外的文件描述符。
确保操作系统可以处理table_cache设置所指的打开的文件描述符的数目。如果table_cacheis设得太高,MySQL可能为文件描述符耗尽资源并拒绝连接,不能执行查询,并且很不可靠。还必须考虑到MyISAM存储引擎需要为每个打开的表提供两个文件描述符。可以在mysqld_safe中使用--open-files-limit启动选项来增加MySQL适用的文件描述符的数量。参见A.2.17节,“文件未找到”。
打开表的缓存可以保持在table_cache条。 默认为64;可以用mysqld的--table_cache选项来更改。请注意 MySQL可以临时打开更多的 表以执行查询。
在下面的条件下,未使用的表将被关闭并从表缓存中移出:
• 当缓存满了并且一个线程试图打开一个不在缓存中的表时。
• 当缓存包含超过table_cache个条目,并且缓存中的表不再被任何线程使用。
• 当表刷新操作发生。当执行FLUSH TABLES语句或执行mysqladmin flush-tables或mysqladmin refresh命令时会发生。
当表缓存满时,服务器使用下列过程找到一个缓存入口来使用:
• 当前未使用的表被释放,以最近最少使用顺序。
• 如果缓存满了并且没有表可以释放,但是一个新表需要打开,缓存必须临时被扩大。
如果缓存处于一个临时扩大状态并且一个表从在用变为不在用状态,它被关闭并从缓存中释放。
对每个并发访问打开一个表。这意味着,如果2个线程访问同一个表或在同一个查询中访问表两次(例如,将表连接为自身时),表需要被打开两次。每个并行的打开要求在表缓存中有一个条目。任何表的第一次打开占2个文件描述符:一个用于数据文件另一个用于索引文件。表的每一次额外使用仅占一个数据文件的文件描述符。索引文件描述符在所有线程之间共享。
如果你正用HANDLER tbl_name OPEN语句打开一个表,将为该线程专门分配一个表。该表不被其它线程共享,只有线程调用HANDLER tbl_name CLOSE或线程终止后才被关闭。表关闭后,被拉回表缓存中(如果缓存不满)。参见13.2.3节,“HANDLER语法”。
可以通过检查mysqld的状态变量Opened_tables确定表缓存是否太小:
mysql> SHOW STATUS LIKE 'Opened_tables';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Opened_tables | 2741 |
+---------------+-------+
如果值很大,即使你没有发出许多FLUSH TABLES语句,也应增加表缓存的大小。参见5.3.3节,“服务器系统变量”和5.3.4节,“服务器状态变量”。
MySQL如何计算打开的表
当运行mysqladmin status时,将看见象这样的一些东西:
Uptime: 426 Running threads: 1 Questions: 11082
Reloads: 1 Open tables: 12
如果你仅有6个表,Open tables值为12可能有点令人困惑。
MySQL是多线程的,因此许多客户可以同时在同一个表上进行查询。为了使多个客户线程在同一个表上有不同状态的问题减到最小,表被每个并发进程独立地打开。这样需要额外的内存但一般会提高性能。对于MyISAM表,数据文件需要为每个打开表的客户提供一个额外的文件描述符。(索引文件描述符在所有线程之间共享)。
10.系统锁(表锁/行锁)情况
mysql> show status like ‘%lock%’;
+——————————-+———+
| Variable_name | Value |
+——————————-+———+
| Com_lock_tables | 0 |
| Com_unlock_tables | 0 |
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 0 |
| Innodb_row_lock_time_avg | 0 |
| Innodb_row_lock_time_max | 0 |
| Innodb_row_lock_waits | 0 |
| Table_locks_immediate | 2667760 |
| Table_locks_waited | 0 |
变量:
* Table_locks_immediate: 产生表级锁定的次数(立即获得的表的锁的次数);
* Table_locks_waited: 出现表级锁定争用而发生等待的次数(不能立即获得的表的锁的次数)。
这两个状态变量记录MySQL内部表级锁定的情况,两个状态值都是从系统启动后开始记录,每出现一次对应的事件则数量加1。如果这里的Table_locks_waited状态值比较高,那么说明系统中表级锁定争用现象比较严重,就须要进一步分析为什么会为有较多的锁定资源争用了。由于Table_locks_waited显示了多少表被锁住并导致了mysql的锁等待,可以开启慢查询看一下。
对于InnoDB所使用的行级锁定,系统是通过另外一组更为详细的状态变量来记录的InnoDB的行级锁定状态变量不仅记录了锁定等待的次数,还记录了锁定总时长、每次平均时长、以及最大时长,此外还有一个非累计状态量显示了当前正在等待的数量。对各个状态的说明如下:
* Innodb_row_lock_current_waits:当前正在等待锁定的数量
* Innodb_row_lock_time : 从系统启动到现在锁定的总时间长度(行锁定用的总时间(ms))
* Innodb_row_lock_time_avg : 每次等待所花平均时间(行锁定的平均时间(ms)),该值大,说明锁冲突大
* Innodb_row_lock_time_max: 从系统启动到现在等待最长的一次所花的时间(行锁定的最长时间(ms));
* Innodb_row_lock_waits : 从系统启动到现在总共等待的次数(行锁定必须等待的时间(ms)),该值大,说明锁冲突大对于这5个状态变量,比较重要的是 Innodb_row_lock_time_avg,Innodb_row_lock_waits 以及Innodb_row_lock_time这三项。尤其是当等待次数很高,而且每次等待时长也不小的时候,就须要分析系统中为什么又如此多的等待,然后根据分析结果着手制定优化计划。
2.使用mysqlreport关注Table Locks,InnoDB Lock
__ Questions ___________________________________________________________
Total 3.38M 81.4/s
DMS 2.88M 69.3/s %Total: 85.11
QC Hits 382.70k 9.2/s 11.32
Com_ 90.50k 2.2/s 2.68
COM_QUIT 30.15k 0.7/s 0.89
+Unknown 18 0.0/s 0.00
Slow 1 s 92 0.0/s 0.00 %DMS: 0.00 Log: OFF
。。。。。。
__ Table Locks _________________________________________________________
Waited 0 0/s %Total: 0.00
Immediate 2.67M 64.2/s
。。。。。。
__ InnoDB Lock _________________________________________________________
Waits 0 0/s
Current 0
Time acquiring
Total 0 ms
Average 0 ms
Max 0 ms
。。。。。。
如果wait过多,平均时间过长,那就是查询设计的有问题,仔细关注下超长时间的查询,并打开slow_query_log。
锁定事宜
1.锁定方法
MySQL 5.1支持对MyISAM和MEMORY表进行表级锁定,对BDB表进行页级锁定,对InnoDB表进行行级锁定。
在许多情况下,可以根据培训猜测应用程序使用哪类锁定类型最好,但一般很难说出某个给出的锁类型就比另一个好。一切取决于应用程序,应用程序的不同部分可能需要不同的锁类型。
为了确定是否想要使用行级锁定的存储引擎,应看看应用程序做什么并且混合使用什么样的选择和更新语句。例如,大多数Web应用程序执行许多选择,而很少进行删除,只对关键字的值进行更新,并且只插入少量具体的表。基本MySQL MyISAM设置已经调节得很好。
在MySQL中对于使用表级锁定的存储引擎,表锁定时不会死锁的。这通过总是在一个查询开始时立即请求所有必要的锁定并且总是以同样的顺序锁定表来管理。
对WRITE,MySQL使用的表锁定方法原理如下:
• 如果在表上没有锁,在它上面放一个写锁。
• 否则,把锁定请求放在写锁定队列中。
对READ,MySQL使用的锁定方法原理如下:
• 如果在表上没有写锁定,把一个读锁定放在它上面。
• 否则,把锁请求放在读锁定队列中。
当一个锁定被释放时,锁定可被写锁定队列中的线程得到,然后是读锁定队列中的线程。
这意味着,如果你在一个表上有许多更新,SELECT语句将等待直到没有更多的更新。
可以通过检查table_locks_waited和table_locks_immediate状态变量来分析系统上的表锁定争夺:
mysql> SHOW STATUS LIKE 'Table%';
+-----------------------+---------+
| Variable_name | Value |
+-----------------------+---------+
| Table_locks_immediate | 1151552 |
| Table_locks_waited | 15324 |
+-----------------------+---------+
如果INSERT语句不冲突,可以自由为MyISAM表混合并行的INSERT和SELECT语句而不需要锁定。也就是说,你可以在其它客户正读取MyISAM表的时候插入行。如果数据文件中间不包含空闲块,不会发生冲突,因为在这种情况下,记录总是插入在数据文件的尾部。(从表的中部删除或更新的行可能导致空洞)。如果有空洞,当所有空洞填入新的数据时,并行的插入能够重新自动启用。
如果不能同时插入,为了在一个表中进行多次INSERT和SELECT操作,可以在临时表中插入行并且立即用临时表中的记录更新真正的表。
这可用下列代码做到:
mysql> LOCK TABLES real_table WRITE, insert_table WRITE;
mysql> INSERT INTO real_table SELECT * FROM insert_table;
mysql> TRUNCATE TABLE insert_table;
mysql> UNLOCK TABLES;
InnoDB使用行锁定,BDB使用页锁定。对于这两种存储引擎,都可能存在死锁。这是因为,在SQL语句处理期间,InnoDB自动获得行锁定和BDB获得页锁定,而不是在事务启动时获得。
行级锁定的优点:
• 当在许多线程中访问不同的行时只存在少量锁定冲突。
• 回滚时只有少量的更改。
• 可以长时间锁定单一的行。
行级锁定的缺点:
• 比页级或表级锁定占用更多的内存。
• 当在表的大部分中使用时,比页级或表级锁定速度慢,因为你必须获取更多的锁。
• 如果你在大部分数据上经常进行GROUP BY操作或者必须经常扫描整个表,比其它锁定明显慢很多。
• 用高级别锁定,通过支持不同的类型锁定,你也可以很容易地调节应用程序,因为其锁成本小于行级锁定。
在以下情况下,表锁定优先于页级或行级锁定:
• 表的大部分语句用于读取。
• 对严格的关键字进行读取和更新,你可以更新或删除可以用单一的读取的关键字来提取的一行:
UPDATE tbl_name SET column=value WHERE unique_key_col=key_value;
DELETE FROM tbl_name WHERE unique_key_col=key_value;
• SELECT 结合并行的INSERT语句,并且只有很少的UPDATE或DELETE语句。
• 在整个表上有许多扫描或GROUP BY操作,没有任何写操作。
不同于行级或页级锁定的选项:
• 版本(例如,为并行的插入在MySQL中使用的技术),其中可以一个写操作,同时有许多读取操作。这说明数据库或表支持数据依赖的不同视图,取决于访问何时开始。其它共同的术语是“时间跟踪”、“写复制”或者“按需复制”。
• 按需复制在许多情况下优先于页级或行级锁定。然而,在最坏的情况下,它可能比使用常规锁定使用更多的内存。
• 除了行级锁定外,你可以使用应用程序级锁定,例如在MySQL中使用GET_LOCK()和RELEASE_LOCK()。这些是建议性锁定,它们只能在运行良好的应用程序中工作。
2.表锁定事宜
为达到最高锁定速度,除InnoDB和BDB之外,对所有存储引擎,MySQL使用表锁定(而不是页、行或者列锁定)。
对于InnoDB和BDB表,如果你用LOCK TABLES显式锁定表,MySQL只使用表锁定。对于这些表类型,我们建议你根本不要使用LOCK TABLES,因为InnoDB使用自动行级锁定而BDB使用页级锁定来保证事务隔离。
对于大表,对于大多数应用程序,表锁定比行锁定更好,但存在部分缺陷。
表锁定使许多线程同时从一个表中进行读取操作,但如果一个线程想要对表进行写操作,它必须首先获得独占访问。更新期间,所有其它想要访问该表的线程必须等待直到更新完成。
表更新通常情况认为比表检索更重要,因此给予它们更高的优先级。这应确保更新一个表的活动不能“饿死”,即使该表上有很繁重的SELECT活动。
表锁定在这种情况下会造成问题,例如当线程正等待,因为硬盘已满并且在线程可以处理之前必须有空闲空间。在这种情况下,所有想要访问出现问题的表的线程也被设置成等待状态,直到有更多的硬盘空间可用。
表锁定在下面的情况下也存在问题:
• 一个客户发出长时间运行的查询。
• 然后,另一个客户对同一个表进行更新。该客户必须等待直到SELECT完成。
• 另一个客户对同一个表上发出了另一个SELECT语句。因为UPDATE比SELECT优先级高,该SELECT语句等待UPDATE完成,并且等待第1个SELECT完成。
下面描述了一些方法来避免或减少表锁定造成的竞争:
• 试图使SELECT语句运行得更快。你可能必须创建一些摘要(summary)表做到这点。
• 用--low-priority-updates启动mysqld。这将给所有更新(修改)一个表的语句以比SELECT语句低的优先级。在这种情况下,在先前情形的第2个SELECT语句将在UPDATE语句前执行,而不需要等候第1个SELECT完成。
• 可以使用SET LOW_PRIORITY_UPDATES=1语句指定具体连接中的所有更新应使用低优先级。参见13.5.3节,“SET语法”
• 可以用LOW_PRIORITY属性给与一个特定的INSERT、UPDATE或DELETE语句较低优先级。
• 可以用HIGH_PRIORITY属性给与一个特定的SELECT语句较高优先级。参见13.2.7节,“SELECT语法”。
• 为max_write_lock_count系统变量指定一个低值来启动mysqld来强制MySQL在具体数量的插入完成后临时提高所有等待一个表的SELECT语句的优先级。这样允许在一定数量的WRITE锁定后给出READ锁定。
• 如果你有关于INSERT结合SELECT的问题,切换到使用新的MyISAM表,因为它们支持并发的SELECT和INSERT。
• 如果你对同一个表混合插入和删除,INSERT DELAYED将会有很大的帮助。参见13.2.4.2节,“INSERT DELAYED语法”。
• 如果你对同一个表混合使用SELECT和DELETE语句出现问题,DELETE的LIMIT选项可以有所帮助。参见13.2.1节,“DELETE语法”。
• 对SELECT语句使用SQL_BUFFER_RESULT可以帮助使表锁定时间变短。参见13.2.7节,“SELECT语法”。
• 可以更改mysys/thr_lock.c中的锁代码以使用单一的队列。在这种情况下,写锁定和读锁定将具有相同的优先级,对一些应用程序会有帮助。
这里是一些MySQL中表锁定相关的技巧:
• 如果不混合更新与需要在同一个表中检查许多行的选择,可以进行并行操作。
• 可以使用LOCK TABLES来提高速度,因为在一个锁定中进行许多更新比没有锁定的更新要快得多。将表中的内容切分为几个表也可以有所帮助。
• 如果在MySQL中表锁定时遇到速度问题,可以将你的表转换为InnoDB或BDB表来提高性能。参见15.2节,“InnoDB存储引擎”和15.5节,“BDB (BerkeleyDB)存储引擎”。
11.表扫描情况
mysql> show status like 'handler_read%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Handler_read_first | 0 |
| Handler_read_key | 0 |
| Handler_read_next | 0 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 0 |
| Handler_read_rnd_next | 20 |
+-----------------------+-------+
6 rows in set (0.00 sec)参数:
* Handler_read_first:使用全索引扫描的次数。
* Handler_read_key:使用索引次数,该值越高越好。
* Handler_read_next:按照键顺序读下一行的请求数。使用索引描述时,从数据文件取数据的次数
* Handler_read_prev:使用索引描述时,按索引倒序从数据文件取数据的次数。一般是order by/desc查询
* Handler_read_rnd:查询直接操作数据文件的次数,有可能未使用索引
* Handler_read_rnd_next:在数据文件中读下一行的请求数。若该值非常大,说明使用了大量的表扫描,索引使用率不高或没有使用索引。
mysql> show status like 'com_select';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Com_select | 318243|
+---------------+-------+
1 row in set (0.00 sec)参数:
* Com_select:执行select操作次数
相关参数:
* read_buffer_size:MySql读入缓冲区大小
* read_rnd_buffer_size:MySql的随机读缓冲区大小
* handler_read_rnd_next:在数据文件中读下一行的请求数。若该值非常大,说明使用了大量的表扫描,索引使用率不高或没有使用索引。
MySQL 会分配一些内存来读取表。理想情况下,索引提供了足够多的信息,可以只读入所需要的行,但是有时候查询(设计不佳或数据本性使然)需要读取表中大量数据。要理解这种行为,需要知道运行了多少个 SELECT 语句,以及需要读取表中的下一行数据的次数(而不是通过索引直接访问)。
表扫描比率:Handler_read_rnd_next / Com_select
如果表扫描比率值超过 4000,就应该调优静态参数read_buffer_size。如read_buffer_size=1M,若超过8M,那么就要优化SQL了。
当某个查询运行时,MySQL需要为当前查询字符串分配内存。
* 对表进行顺序扫描的请求将分配一个缓存区(变量read_buffer_size)。
* 当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读 缓存区(变量read_rnd_buffer_size)以避免硬盘搜索。
每个线程对表进行连续扫描时都会为扫描的每个表分配缓冲区,read_buffer_size变量控制这一缓冲区的大小。如果进行多次连续扫描,可能需要增加该值, 默认值为131072。和sort_buffer_size一样,该参数对应的分配内存也是每连接独享。
当排序后按排序后的顺序读取行时,则通过随机读缓冲区读取行,避免搜索硬盘。read_rnd_buffer_size是控制这一缓冲区的大小,将该变量设置为较大的值可以大大改进ORDER BY的性能。如果需要排序大量数据,可适当调高该值。但是,这是为每个客户端分配的缓冲区(即该参数对应的分配内存是每连接独享的),因此你不应将全局变量设置为较大的值。相反,只为需要运行大查询的客户端更改会话变量。
12.排序情况
mysql> show variables like 'sort_buffer_size';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| sort_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.00 sec)
参数:
* sort_buffer_size:每个排序线程分配的缓冲区的大小。增加该值可以加快ORDER BY或GROUP BY操作。
mysql> show status like 'sort%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Sort_merge_passes | 0 |
| Sort_range | 0 |
| Sort_rows | 0 |
| Sort_scan | 0 |
+-------------------+-------+
4 rows in set (0.00 sec)参数:
* Sort_merge_passes:排序算法已经执行的合并的数量。
* Sort_range:
* Sort_rows:
* Sort_scan:
一般的,查询sort都会经历三个步骤
1. 查找where条件的值
2. 排序值
3. 读排序后的行
如果在第一步时增加Select_scan,则第三步就会是增加Sort_scan;如果第一步是增加 Select_range,则第三步就是 增加Sort_range。
Sort_merge_passes 包括两步:MySQL 首先会尝试在内存中做排序,使用的内存大小由系统变量 Sort_buffer_size 决定,如果它的大小不够把所有的记录都读到内存中,MySQL 就会把每次在内存中排序的结果存到临时文件中,这时候会增加Sort_merge_passes。等 MySQL 找到所有记录之后,再把临时文件中的记录做一次排序。实际上,MySQL 会用另一个临时文件来存再次排序的结果,所以通常会看到 Sort_merge_passes 增加的数值是建临时文件数的两倍。因为用到了临时文件,所以速度可能会比较慢,增加 Sort_buffer_size 会减少 Sort_merge_passes 和 创建临时文件的次数。但盲目的增加 Sort_buffer_size 并不一定能提高速度。
如果 sort_merge_passes 状态变量很大,这就指示了磁盘的活动情况,表示需要注意 sort_buffer_size(说明排序缓冲区太小)。
sort_buffer_size表示每个排序线程分配的缓冲区的大小。增加该值可以加快ORDER BY或GROUP BY操作。当 MySQL 必须要进行排序时,就会在从磁盘上读取数据时分配一个排序缓冲区来存放这些数据行。如果要排序的数据太大,那么数据就必须保存到磁盘上的临时文件中,并再次进行排序。
注意:该参数对应的分配内存是每个连接独享,如果有100个连接,那么实际分配的总共排序缓冲区大小为100 × 6 = 600MB。所以,对于内存在4GB左右的服务器推荐设置为6-8M。相关参数:
* myisam_sort_buffer_size:当在REPAIR TABLE或用CREATE INDEX创建索引或ALTER TABLE过程中排序 MyISAM索引分配的缓冲区。
* max_length_for_sort_data:filesort算法的索引值大小的限值
* max_seeks_for_key:限制根据键值寻找行时的最大搜索数。
参见A.4.4节,“MySQL将临时文件储存在哪里”。
13.全联接
mysql> show status like '%select_full__%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| Select_full_join | 0 |
| Select_full_range_join | 0 |
+------------------------+-------+
2 rows in set (0.00 sec)参数:
* Select_full_joing:全联接
* Select_full_range_join:范围查询联接
相关变量:
* join_buffer_size:联接查询操作所能使用的缓冲区大小
一般情况获得快速联接的最好方法是添加索引。当增加索引时不可能通过增加join_buffer_size值来获得快速完全联接。将为两个表之间的每个完全联接分配联接缓冲区。对于多个表之间不使用索引的复杂联接,需要多联接缓冲区。join_buffer_size用于完全联接的缓冲区的大小(当不使用索引的时候使用联接操作)。和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享。
一般应避免无索引的完全联接操作,如果 Select_full_range_join过高,则说明系统运行了很多范围查询联接。
相关参数:
* max_join_size:通过设置该值,你可以捕获键使用不正确并可能花很长时间的SELECT语句。如果用户想要执行没有WHERE子句的花较长时间或返回数百万行的联接,则设置它。
14.临时表情况
mysql> show status like 'created_tmp%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| Created_tmp_disk_tables | 0 |
| Created_tmp_files | 5 |
| Created_tmp_tables | 0 |
+-------------------------+-------+
3 rows in set (0.00 sec)
参数:* Created_tmp_disk_tables:服务器执行语句时在硬盘上自动创建的临时表的数量
* Created_tmp_files: mysqld创建的临时文件个数
* Created_tmp_tables: 服务器执行语句时在内存上自动创建的临时表的数量,如果Created_tmp_disk_tables较大,你可能要增加tmp_table_size值使临时表基于内存而不基于硬盘。
Create_tmp_disk_tables为0表示不需要使用磁盘上的临时表
mysql> show variables like 'tmp_table%';
+----------------+-----------+
| Variable_name | Value |
+----------------+-----------+
| tmp_table_size | 257949696 |
+----------------+-----------+
1 row in set (0.00 sec)
变量:* tmp_table_size:临时表容量
mysql> show variables like 'max_heap%';
+---------------------+-----------+
| Variable_name | Value |
+---------------------+-----------+
| max_heap_table_size | 257949696 |
+---------------------+-----------+
1 row in set (0.00 sec)变量:
* max_heap_table_size:内存表容量
临时表可以在更高级的查询中使用,其中数据在进一步进行处理(例如 GROUP BY 字句)之前,都必须先保存到临时表中;理想情况下,在内存中创建临时表。但是如果临时表变得太大,就需要写入磁盘中。
每次使用临时表都会增大 Created_tmp_tables;基于磁盘的表也会增大 Created_tmp_disk_tables。对于这个比率,并没有什么严格的规则,因为这依赖于所涉及的查询。长时间观察 Created_tmp_disk_tables 会显示所创建的磁盘表的比率,您可以确定设置的效率。 tmp_table_size 和 max_heap_table_size 都可以控制临时表的最大大小,因此请确保在 my.cnf 中对这两个值都进行了设置。由于当数据超过临时表的最大值设定时,自动转为磁盘表,此时因需要进行IO操作,性能会大大下降,而内存表不会,内存表满后,会提示数据满错误。
如果Created_tmp_disk_tables值较高,则有可能是因为:tmp_table_size或者max_heap_table_size太小或者是选择blob、text属性的时候创建了临时表;如果Created_tmp_tables 过高的话,那么就需要优化查询。
变量tmp_table_size指示临时表的容量,如果内存内的临时表超过该值,MySQL自动将它转换为硬盘上的MyISAM表。如果你执行许多高级GROUP BY查询并且有大量内存,则可以增加tmp_table_size的值。
变量max_heap_table_size指示内存表的容量,该变量设置MEMORY (HEAP)表可以增长到的最大空间大小。该变量用来计算MEMORY表的MAX_ROWS值。在已有的MEMORY表上设置该变量没有效果,除非用CREATE TABLE或TRUNCATE TABLE等语句重新创建表。
相关变量:
* tmpdir:保存临时文件和临时表的目录。该变量可以设置为几个路径,按round-robin模式使用。在Unix中应该用冒号(‘:’)间隔开路径,在Windows、NetWare和OS/2中用分号(‘;’)。用来将负荷分散到几个物理硬盘上。如果MySQL服务器为复制从服务器,你不应将tmpdir设置为指向基于内存的文件系统上的目录或当服务器主机重启时声明的目录。复制从服务器需要部分临时文件来在机器重启后仍可用,以便它可以复制临时表或执行LOAD DATA INFILE操作。如果服务器重启时临时文件夹中的文件丢失了,则复制失败。但是,如果你使用MySQL 4.0.0或更新版本,你可以使用 slave_load_tmpdir变量设置从服务器的临时目录。在这种情况下,从服务器不再使用常规tmpdir,说明你可以将tmpdir设置到一个非固定位置。
15.二进制日志缓存
mysql> show status like'%binlog%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| Binlog_cache_disk_use | 0 |
| Binlog_cache_use | 69166 |
| Com_binlog | 0 |
| Com_show_binlog_events | 0 |
| Com_show_binlogs | 0 |
+------------------------+-------+
5 rows in set (0.00 sec)
参数:* Binlog_cache_disk_use:在硬盘上创建的临时文件数量
* Binlog_cache_use: 在内存中创建的临时文件数量
* Com_binlog: 二进制日志数量
* Com_show_binlog_events:服务器执行show binlog event语句的次数
* Com_show_binglogs:
mysql> show variables like'%binlog%';
+-----------------------------------------+------------+
| Variable_name | Value |
+-----------------------------------------+------------+
| binlog_cache_size | 4194304 |
| binlog_direct_non_transactional_updates | OFF |
| binlog_format | MIXED |
| innodb_locks_unsafe_for_binlog | OFF |
| max_binlog_cache_size | 8388608 |
| max_binlog_size | 1073741824 |
| sync_binlog | 0 |
+-----------------------------------------+------------+
7 rows in set (0.00 sec)变量:
* binlog_cache_size:同时开启事务和二进制日志时,每个客户端日志的缓存大小
* binlog_direct_non_transactional_update:
* binlog_format:
* innodb_locks_unsafe_for_binlog:
* max_binlog_cache_size:多语句事务需要的内存
* max_binlog_size:二进制日志文件的大小限制,缺省值1G
* sync_binlog:控制二进制日志到硬盘的同步。
mysql-bin.000001、mysql-bin.000002等文件是数据库的操作日志,例如UPDATE一个表,或者DELETE一些数据,即使该语句没有匹配的数据,这个命令也会存储到日志文件中,还包括每个语句执行的时间,也会记录进去的。
Binlog Cache 用于在打开了二进制日志(binlog)记录功能的环境,是 MySQL 用来提高binlog的记录效率而设计的一个用于短时间内临时缓存binlog数据的内存区域。一般来说,如果我们的数据库中没有什么大事务,写入也不是特别频繁,2MB~4MB是一个合适的选择。但是如果我们的数据库大事务较多,写入量比较大,可与适当调高binlog_cache_size。
同时,我们可以通过binlog_cache_use 以及 binlog_cache_disk_use来分析设置的binlog_cache_size是否足够,是否有大量的binlog_cache由于内存大小不够而使用临时文件(binlog_cache_disk_use)来缓存了。如果Binlog_cache_disk_use 和 Binlog_cache_use 比例很大,那么就应该增加binlog_cache_size的值。
binlog_cache_size指示了在事务过程中容纳二进制日志SQL语句的缓存大小。如果你经常使用大的,多语句事务,你可以增加binlog_cache_size的值以获得更有的性能。Binlog_cache_use和Binlog_cache_disk_use状态变量可以用来调整该变量的大小。
Max_binlog_cache_size显示了多语句事务需要更大的内存,如果多语句事务需要更大的内存,你会得到错误Multi-statement transaction required more than 'max_binlog_cache_size' bytes of storage。
如果二进制日志写入的内容超出Max_binlog_size给定值,日志就会发生滚动。你不能将该变量设置为大于1GB或小于4096字节。 默认值是1GB。
请注意如果你正使用事务:事务以一个块写入二进制日志,因此不不能被几个二进制日志拆分。因此,如果你有大的事务,二进制日志可能会大于max_binlog_size。
如果max_relay_log_size为0, max_binlog_size的值也适用于中继日志。
sync_binlog值如果为正,当每个sync_binlog'th写入该二进制日志后,MySQL服务器将它的二进制日志同步到硬盘上(fdatasync())。请注意如果在autocommit模式,每执行一个语句向二进制日志写入一次,否则每个事务写入一次。
sync_binlog默认值是0,不与硬盘同步。值为1是最安全的选择,因为崩溃时,你最多丢掉二进制日志中的一个语句/事务;但是,这是最慢的选择(除非硬盘有电池备份缓存,从而使同步工作较快)。
相关参数:
* max_relay_log_size如果复制从服务器写入中继日志时超出给定值,则滚动中继日志。通过该变量你可以对中继日志和二进制日志设置不同的限制。但是,将该变量设置为0,MySQL可以对二进制日志和中继日志使用max_binlog_size。max_relay_log_size必须设置在4096字节和1GB(包括)之间,或为0。 默认值是0。
MySQL如何使用内存
下面的列表中列出了mysqld服务器使用内存的一些方法。在适用的地方,给出了内存相关的系统变量名:
• 键缓存(变量key_buffer_size)被所有线程共享;服务器使用的其它缓存则根据需要分配。参见7.5.2节,“调节服务器参数”。
• 每个连接使用具体线程的空间:
o 堆栈(默认64KB,变量thread_stack)
o 连接缓存区(变量net_buffer_length)
o 结果缓存区(变量net_buffer_length)
连接缓存区和结果缓存区可以根据需要动态扩充到max_allowed_packet。当某个查询运行时,也为当前查询字符串分配内存。
• 所有线程共享相同的基本内存。
• 只有压缩MyISAM表映射到内存。这是因为4GB的32位内存空间不足以容纳大多数大表。当64位地址空间的系统变得越来越普遍后,我们可以增加常规的内存映射支持。
• 对表进行顺序扫描的请求将分配一个缓存区(变量read_buffer_size)。
• 当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读 缓存区(变量read_rnd_buffer_size)以避免硬盘搜索。
• 所有联合在一个令牌内完成,并且大多数联合甚至可以不用临时表即可以完成。大多数临时表是基于内存的(HEAP)表。具有大的记录长度的临时表 (所有列的长度的和)或包含BLOB列的表存储在硬盘上。
如果某个内部heap(堆积)表大小超过tmp_table_size,MySQL可以根据需要自动将内存中的heap表改为基于硬盘的MyISAM表。还可以通过设置mysqld的tmp_table_size选项来增加临时表的大小,或设置客户程序中的SQL选项SQL_BIG_TABLE。参见13.5.3节,“SET语法”。
• 进行排序的大多数请求将分配一个排序缓存区,并根据结果集的大小为两个临时文件分配零。参见A.4.4节,“MySQL将临时文件储存在哪里”。
• 几乎所有解析和计算在局部内存中完成。小项目不需要内存,因此避免了普通的慢内存分配和释放。只为不期望的大字符串分配内存;使用函数malloc()和free()来完成。
• 对于每个打开的MyISAM表,索引文件打开一次;数据文件为每个并行运行的线程打开一次。对于每个并行线程,将分配一个表结构、一个每个列的列结构和大小为3 * N的缓存区(其中N是最大行的长度,而不是计算BLOB列)。一个BLOB列需要5至8个字节加上BLOB数据的长度。MyISAM 存储引擎维护一个额外的行缓存区供内部应用。
• 对于每个具有BLOB列的表,将对缓存区进行动态扩大以读入大的BLOB 值。如果你扫描一个表,则分配一个与最大的BLOB值一样大的缓存区。
• 所有使用的表的句柄结构保存在高速缓存中并以FIFO管理。默认情况,高速缓存有64个入口。如果某个表同时被两个运行的线程使用,高速缓存则为该提供两个入口。参见7.4.9节,“MySQL如何打开和关闭表”。
• 当并行执行的线程结束时,FLUSH TABLE语句或mysqladmin flush-table命令可以立即关闭所有不使用的表并将所有使用中的表标记为已经关闭。这样可以有效释放大多数使用中的内存。FLUSH TABLE在关闭所有表之前不返回结果。
ps和其它系统状态程序可以报导mysqld使用很多内存。这可以是在不同的内存地址上的线程栈造成的。例如,Solaris版本的ps将栈间未用的内存算作已用的内存。你可以通过用swap -s检查可用交换区来验证它。我们用商业内存漏洞探查器测试了mysqld,因此应该有没有内存漏洞。
16.InnoDB相关状态
关于InnoDB的性能分析,MySQL官方文档中有一节作专门分析:InnoDB性能调节揭示。
变量:
mysql> show variables like 'innodb%';
+---------------------------------+------------------------+
| Variable_name | Value |
+---------------------------------+------------------------+
| innodb_adaptive_hash_index | ON |
| innodb_additional_mem_pool_size | 2097152 |
| innodb_autoextend_increment | 8 |
| innodb_autoinc_lock_mode | 1 |
| innodb_buffer_pool_size | 17825792 |
| innodb_checksums | ON |
| innodb_commit_concurrency | 0 |
| innodb_concurrency_tickets | 500 |
| innodb_data_file_path | ibdata1:10M:autoextend |
| innodb_data_home_dir | |
| innodb_doublewrite | ON |
| innodb_fast_shutdown | 1 |
| innodb_file_io_threads | 4 |
| innodb_file_per_table | OFF |
| innodb_flush_log_at_trx_commit | 1 |
| innodb_flush_method | |
| innodb_force_recovery | 0 |
| innodb_lock_wait_timeout | 50 |
| innodb_locks_unsafe_for_binlog | OFF |
| innodb_log_buffer_size | 8388608 |
| innodb_log_file_size | 16777216 |
| innodb_log_files_in_group | 2 |
| innodb_log_group_home_dir | .\ |
| innodb_max_dirty_pages_pct | 90 |
| innodb_max_purge_lag | 0 |
| innodb_mirrored_log_groups | 1 |
| innodb_open_files | 300 |
| innodb_rollback_on_timeout | OFF |
| innodb_stats_on_metadata | ON |
| innodb_support_xa | ON |
| innodb_sync_spin_loops | 20 |
| innodb_table_locks | ON |
| innodb_thread_concurrency | 8 |
| innodb_thread_sleep_delay | 10000 |
+---------------------------------+------------------------+
34 rows in set (0.05 sec)
参数:
mysql> show status like 'innodb%';
+-----------------------------------+---------+
| Variable_name | Value |
+-----------------------------------+---------+
| Innodb_buffer_pool_pages_data | 96 | 分配出去,正在被使用页的数量,包括脏页。单位page
| Innodb_buffer_pool_pages_dirty | 0 |脏页但没有被flush除去的页面数。单位page
| Innodb_buffer_pool_pages_flushed | 795 |已经flush的页面数。单位page
| Innodb_buffer_pool_pages_free | 992 |当前空闲页面数。单位page
| Innodb_buffer_pool_pages_misc | 64 |缓存池中当前已经被用作管理用途或hash index而不能用作为普通数据页的数目。单位page
| Innodb_buffer_pool_pages_total | 4096 |缓冲区总共的页面数。单位page
| Innodb_buffer_pool_read_ahead_rnd | 8 |随机预读的次数
| Innodb_buffer_pool_read_ahead_seq | 1 |顺序预读的次数
| Innodb_buffer_pool_read_requests | 1725871 |从缓冲池中读取页的次数
| Innodb_buffer_pool_reads | 2108 |从磁盘读取页的次数。缓冲池里面没有, 就会从磁盘读取
| Innodb_buffer_pool_wait_free | 0 |缓冲池等待空闲页的次数,当需要空闲块而系统中没有时,就会等待空闲页面
| Innodb_buffer_pool_write_requests | 2296 |缓冲池总共发出的写请求次数
| Innodb_data_fsyncs | 695 |总共完成的fsync次数
| Innodb_data_pending_fsyncs | 0 | innodb当前等待的fsync次数
| Innodb_data_pending_reads | 0 | innodb当前等待的读的次数
| Innodb_data_pending_writes | 0 | innodb当前等待的写的次数
| Innodb_data_read | 44044288 |总共读入的字节数
| Innodb_data_reads | 2191 | innodb完成的读的次数
| Innodb_data_writes | 1296 | innodb完成的写的次数
| Innodb_data_written | 26440192 |总共写出的字节数
| Innodb_dblwr_pages_written | 795 |
| Innodb_dblwr_writes | 90 |
| Innodb_log_waits | 0 |因日志缓存太小而必须等待其被写入所造成的等待数。单位是次
| Innodb_log_write_requests | 0 |
| Innodb_log_writes | 1 |
| Innodb_os_log_fsyncs | 3 |
| Innodb_os_log_pending_fsyncs | 0 |
| Innodb_os_log_pending_writes | 0 |
| Innodb_os_log_written | 512 |
| Innodb_page_size | 16384 |
| Innodb_pages_created | 0 |
| Innodb_pages_read | 96 |
| Innodb_pages_written | 0 |
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 0 |
| Innodb_row_lock_time_avg | 0 |
| Innodb_row_lock_time_max | 0 |
| Innodb_row_lock_waits | 0 |
| Innodb_rows_deleted | 0 |
| Innodb_rows_inserted | 0 |
| Innodb_rows_read | 0 |
| Innodb_rows_updated | 0 |
+-----------------------------------+---------+
42 rows in set (0.00 sec)
innodb_buffer_pool_size:这是InnoDB最重要的设置,对InnoDB性能有决定性的影响。innodb_buffer_pool_size 定义了 InnoDB 存储引擎的表数据和索引数据的最大内存缓冲区大小。即用来设置用于缓存 InnoDB 索引及数据块的内存区域大小,类似于 MyISAM 存储引擎的 key_buffer_size 参数。和 MyISAM 存储引擎不同, MyISAM 的 key_buffer_size 只能缓存索引键,而 innodb_buffer_pool_size 却可以缓存数据块和索引键。简单来说,当我们操作一个 InnoDB 表的时候,返回的所有数据或者去数据过程中用到的任何一个索引块,都会在这个内存区域中走一遭。适当的增加这个参数的大小,可以有效的减少 InnoDB 类型的表的磁盘 I/O 。为Innodb加速优化首要参数。默认值8M。
如果不使用InnoDB存储引擎,可以不用调整这个参数,如果需要使用,在内存允许的情况下,尽可能将所有的InnoDB数据文件存放如内存中。这个参数不能动态更改,所以分配需多考虑。分配过大,会使Swap占用过多,致使Mysql的查询特慢。在只有InnoDB存储引擎的数据库服务器上面,可以设置60-80%的内存。更精确一点,在内存容量允许 的情况下面设置比InnoDB tablespaces大10%的内存大小。即如果你的数据量不大,并且不会暴增,那么可分配是你的数据大小+10%左右做为这个参数的值。例如:数据大小为50M,那么给这个值分配innodb_buffer_pool_size=64M
命中率=innodb_buffer_pool_read_requests / (innodb_buffer_pool_read_requests + innodb_buffer_pool_read_ahead + innodb_buffer_pool_reads)
也可以通过 (Innodb_buffer_pool_read_requests – Innodb_buffer_pool_reads) / Innodb_buffer_pool_read_requests * 100% 计算缓存命中率,并根据命中率来调整 innodb_buffer_pool_size 参数大小进行优化。
innodb_additional_mem_pool_size:
作用:设置了InnoDB存储引擎用来存放数据字典信息以及一些内部数据结构的内存空间大小这个值不用分配太大,系统可以自动调。不用设置太高。通常比较大数据设置16M够用了,如果表比较多,可以适当的增大。如果这个值自动增加,会在error log有中显示的。20M足够了。
innodb_log_file_size
作用:指定日志的大小,该参数决定了recovery speed。太大的话recovery就会比较慢,太小了影响查询性能,一般取256M可以兼顾性能和recovery的速度。
分配原则:几个日志成员大小加起来差不多和你的innodb_buffer_pool_size相等。在高写入负载尤其是大数据集的情况下很重要。这个值越大则性能相对越高,但是要注意到可能会增加恢复时间。说明:这个值分配的大小和数据库的写入速度,事务大小,异常重启后的恢复有很大的关系。
innodb_log_buffer_size:
这是 InnoDB 存储引擎的事务日志所使用的缓冲区。由于磁盘速度是很慢的,直接将log写道磁盘会影响InnoDB的性能,该参数设定了log buffer的大小,一般4M。如果有大的blob操作,可以适当增大。类似于 Binlog Buffer,InnoDB 在写事务日志的时候,为了提高性能,也是先将信息写入 Innofb Log Buffer 中,当满足 innodb_flush_log_trx_commit 参数所设置的相应条件(或者日志缓冲区写满)之后,才会将日志写到文件(或者同步到磁盘)中。可以通过 innodb_log_buffer_size 参数设置其可以使用的最大内存空间。
作用:事务在内存中的缓冲。
分配原则:控制在2-8M.这个值不用太多的。他里面的内存一般一秒钟写到磁盘一次。具体写入方式和你的事务提交方式有关。一般最大指定为4M比较合适。
参考:Innodb_os_log_written(show global status 可以拿到)
如果这个值增长过快,可以适当的增加innodb_log_buffer_size
另外如果你需要处理大理的text,或是blog字段,可以考虑增加这个参数的值。
默认的设置在中等强度写入负载以及较短事务的情况下,服务器性能还可以。如果存在更新操作峰值或者负载较大,就应该考虑加大它的值了。如果它的值设置太高了,可能会浪费内存 -- 它每秒都会刷新一次,因此无需设置超过1秒所需的内存空间。通常 8-16MB 就足够了。越小的系统它的值越小。
innodb_flush_log_at_trx_commit:
作用:控制事务的提交方式;innodb_flush_log_trx_commit 参数对 InnoDB Log 的写入性能有非常关键的影响。
分配原则:这个参数只有3个值,0,1,2请确认一下自已能接受的级别。默认为1,主库请不要更改了。性能更高的可以设置为0或是2,但会丢失一秒钟的事务。
值为1时:innodb 的事务LOG在每次提交后写入日志文件,并对日志刷新到磁盘。这个可以做到不丢任何一个事务。Truly ACID.速度慢。
值为2时,也就是不把日志刷新到磁盘上,而只刷新到操作系统的缓存上。日志仍然会每秒刷新到磁盘中去,因此通常不会丢失每秒1-2次更新的消耗。只有操作系统崩溃或掉电才会删除最后一秒的事务,不然不会丢失事务。值为 0时 就快很多了,不过也相对不安全了:日志缓冲每秒一次地被写到日志文件,并且对日志文件做到磁盘操作的刷新。任何mysqld进程的崩溃会删除崩溃前最后一秒的事务。设置为 2 只会丢失刷新到操作系统缓存的那部分事务。
MySQL文档中提到,这几种设置中的每秒同步一次的机制,可能并不会完全确保非常准确的每秒就一定会发生同步,还取决于进程调度的问题。实际上,InnoDB 能否真正满足此参数所设置值代表的意义正常 Recovery 还是受到了不同 OS 下文件系统以及磁盘本身的限制,可能有些时候在并没有真正完成磁盘同步的情况下也会告诉 mysqld 已经完成了磁盘同步。
transaction-isolation=READ-COMITTED: 如果应用程序可以运行在READ-COMMITED隔离级别,做此设定会有一定的性能提升。
innodb_file_per_table:
作用:使每个Innodb的表,有自已独立的表空间。可以存储每个InnoDB表和它的索引在它自己的文件中。如删除文件后可以回收那部分空间。
分配原则:只有使用不使用。但DB还需要有一个公共的表空间。
InnoDB 默认会将所有的数据库InnoDB引擎的表数据存储在一个共享空间中:ibdata1,增删数据库的时候,ibdata1文件不会自动收缩,单个数据库的备份也将成为问题。通常只能将数据使用mysqldump 导出,然后再导入解决这个问题。
查看是否开启:
mysql> show variables like ‘%per_table%’;
开启
innodb_file_per_table=1
innodb_open_files:
作用:限制Innodb能打开的表的数据。
分配原则:如果库里的表特别多的情况,请增加这个。这个值默认是300。这个值必须超过你配置的innodb_data_file_path个数。请适当的增加innodb_open_files。
innodb_flush_method:Innodb和系统打交道的一个IO模型。
作用:设置InnoDB同步IO的方式
分配原则:Windows不用设置。UNIX可以设置:Default,O_DIRECT,和O_DSYNC1) Default – 使用fsync()。
2) O_DSYNC – 以sync模式打开文件,通常比较慢。
3) O_DIRECT – 在Linux上使用Direct IO.可以显着提高速度,特别是在RAID系统上。避免额外的数据复制和double buffering(mysql buffering 和OS buffering)。O_DIRECT跳过了操作系统的文件系统Disk Cache,让MySQL直接读写磁盘。 有数据表明,如果是大量随机写入操作,O_DIRECT会提升效率。但是顺序写入和读取效率都会降低。
innodb_max_dirty_pages_pct:
这个参数和上面的各个参数不同,他不是用来设置用于缓存某种数据的内存大小的一个参数,而是用来控制在 InnoDB Buffer Pool 中可以不用写入数据文件中的Dirty Page 的比例(已经被修但还没有从内存中写入到数据文件的脏数据)。这个比例值越大,从内存到磁盘的写入操作就会相对减少,所以能够一定程度下减少写入操作的磁盘IO。但是,如果这个比例值过大,当数据库 Crash 之后重启的时间可能就会很长,因为会有大量的事务数据需要从日志文件恢复出来写入数据文件中。同时,过大的比例值同时可能也会造成在达到比例设定上限后的 flush 操作“过猛”而导致性能波动很大。
作用:控制Innodb的脏页在缓冲中在那个百分比之下,值在范围1-100,默认为90.
O_DIRECT的flush_method更适合于操作系统内存有限的情况下(可以避免不必要的对交换空间的读写操作),否则,它会由于禁用了os的缓冲降低对数据的读写操作的效能。
使用memlock可以避免MySQL内存进入swap
innodb_data_file_path:
作用:指定表数据和索引存储的空间,可以是一个或者多个文件。最后一个数据文件必须是自动扩充的,也只 有最后一个文件允许自动扩充。这样,当空间用完后,自动扩充数据文件就会自动增长(以8MB为单位)以容纳额外的数据。例如: innodb_data_file_path=/disk1/ibdata1:900M;/disk2/ibdata2:50M:autoextend两 个数据文件放在不同的磁盘上。数据首先放在ibdata1中,当达到900M以后,数据就放在ibdata2中。一旦达到50MB,ibdata2将以 8MB为单位自动增长。如果磁盘满了,需要在另外的磁盘上面增加一个数据文件。
innodb_autoextend_increment:
默认是8M, 如果一次insert数据量比较多的话, 可以适当增加。
innodb_data_home_dir:作用:放置表空间数据的目录,默认在mysql的数据目录,设置到和MySQL安装文件不同的分区可以提高性能。
innodb_thread_concurrency:
作用:InnoDB kernel最大的线程数。
1) 最少设置为(num_disks+num_cpus)*2.
2) 可以通过设置成1000来禁止这个限制注: MySQL 中为了减少磁盘物理IO而设计的几个主要参数,对 MySQL 的性能起到了至关重要的作用,参数包括:query_cache_size/query_cache_type(global)、binlog_cache_size(global)、key_buffer_size(global)、bulk_insert_buffer_size(thread)、innodb_buffer_pool_size(global)、innodb_log_buffer_size(global)、innodb_max_dirty_pages_pct(global).
如果Unix顶层工具或者Windows任务管理器显示,你的数据库的工作负荷的CPU使用率小于70%,则你的工作负荷可能是磁盘绑定的,可能你正生成太多的事务和提交,或者缓冲池太小。使得缓冲池更大一些会有帮助的,但不要设置缓冲池等于或超过物理内存的80%.
把数个修改裹进一个事务里。如果事务对数据库修改,InnoDB在该事务提交时必须刷新日志到磁盘。因为磁盘旋转的速度至多167转/秒,如果磁盘没有骗操作系统的话,这就限制提交的数目为同样的每秒167次。
如果你可以接受损失一些最近的已提交事务,你可以设置my.cnf文件里的参数innodb_flush_log_at_trx_commit为0。 无论如何InnoDB试着每秒刷新一次日志,尽管刷新不被许可。
使用大的日志文件,让它甚至与缓冲池一样大。当InnoDB写满日志文件时,它不得不在一个检查点把缓冲池已修改的内容写进磁盘。小日志文件导致许多不必要的吸盘写操作。大日志文件的缺点时恢复时间更长。
也让日志缓冲相当大(与8MB相似的数量)。
如果你存储变长度字符串,或者列可能包含很多NULL值,则使用VARCHAR列类型而不是CHAR类型。一个CHAR(N)列总是占据N 字节来存储,即使字符串更短或字符串的值是NULL。越小的表越好地适合缓冲池并且减少磁盘I/O。
当使用row_format=compact (MySQL 5.1中默认的InnoDB记录格式)和可变长度字符集,比如UTF-8或sjis,CHAR(N)将占据可变数量的空间,至少为N 字节。
在一些版本的GNU/Linux和Unix上,用Unix的fsync()(InnoDB默认使用的)把文件刷新到磁盘,并且其他相似的方法是惊人的慢。如果你不满意数据库的写性能,你可以试着设置my.cnf里的innodb_flush_method为O_DSYNC,虽然O_DSYNC在多数系统上看起来更慢。
当在Solaris 10上,为x86_64架构(AMD Opteron)使用InnoDB存储引擎,重要的是使用forcedirectio选项来安装任何为存储与InnoDB相关的文件而使用的数据系统。(默认在Solaris 10/x86_64上不使用这个文件系统安装选项)。使用forcedirectio 失败会导致InnoDB在这个平台上的速度和性能严重退化。
当导入数据到InnoDB中之时,请确信MySQL没有允许autocommit模式,因为允许autocommit模式会需要每次插入都要刷新日志到磁盘。要在导入操作规程中禁止autocommit模式,用SET AUTOCOMMIT和COMMIT语句来包住导入语句:
SET AUTOCOMMIT=0;
/* SQL import statements ... */
COMMIT;
如果你使用mysqldump 选项--opt,即使不用SET AUTOCOMMIT和COMMIT语句来包裹,你也使得快速的转储文件被导入到InnoDB表中。
小心大宗插入的大回滚:InnoDB在插入中使用插入缓冲来节约磁盘I/O,但是在相应的回滚中没有使用这样的机制。一个磁盘绑定的回滚可以用相应插入花费时间的30倍来执行。杀掉数据库进程没有是帮助的,因为回滚在服务器启动时会再次启动。除掉一个失控的回滚的唯一方法是增大缓冲池使得回滚变成CPU绑定且跑得快,或者使用专用步骤,请参阅15.2.8.1节,“强制恢复”。
也要小心其它大的磁盘绑定操作。用DROP TABLE或CREATE TABLE来清空一个表,而不是用DELETE FROM tbl_name。
如果你需要插入许多行,则使用多行插入语法来减少客户端和服务器之间的通讯开支:
INSERT INTO yourtable VALUES (1,2), (5,5), ...;
这个提示对到任何表类型的插入都是合法的,不仅仅是对InnoDB类型。
如果你在第二个键上有UNIQUE约束,你可以在导入会话中暂时关闭唯一性检查以加速表的导入:
SET UNIQUE_CHECKS=0;
对于大表,这节约了大量磁盘I/O,因为InnoDB可以使用它的插入缓冲来在一批内写第二个索引记录。
如果你对你的表有FOREIGN KEY约束,你可以在导入会话过程中通过关闭外键检查来提速表的导入:
SET FOREIGN_KEY_CHECKS=0;
对于大表,这可以节约大量的磁盘I/O。
如果你经常有对不经常更新的表的重发查询,请使用查询缓存:
[mysqld]
query_cache_type = ON
query_cache_size = 10M
其它参数
1.bulk_insert_buffer_size (thread)
和key_buffer_size一样,这个参数同样也仅作用于使用 MyISAM存储引擎,用来缓存批量插入数据的时候临时缓存写入数据。当我们使用如下几种数据写入语句的时候,会使用这个内存区域来缓存批量结构的数据以帮助批量写入数据文件:
insert … select …
insert … values (…) ,(…),(…)…
load data infile… into… (非空表)
MyISAM 使用专用树状缓存来使INSERT ... SELECT、INSERT ... VALUES (...)、(...)、 ...和LOAD DATA INFILE的大块插入更快。该变量用每线程的字节数限制缓存树的大小。将它设置为0禁用优化。
2.delay_key_write / delayed_insert_limit
mysql> show variables like 'delay%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| delay_key_write | ON |
| delayed_insert_limit | 100 |
| delayed_insert_timeout | 300 |
| delayed_queue_size | 1000 |
+------------------------+-------+
4 rows in set (0.00 sec)
变量:
* delay_key_write:
* delayed_insert_limit:
* delayed_insert_timeout:
* delayed_queue_size:
mysql> show status like '%delay%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| Delayed_errors | 0 |
| Delayed_insert_threads | 0 |
| Delayed_writes | 0 |
| Not_flushed_delayed_rows | 0 |
+--------------------------+-------+
4 rows in set (0.06 sec)
参数:
* Delayed_errors:用INSERT DELAYED写入的发生某些错误(可能重复键值)的行数
* Delayed_insert_threads:正在使用的延迟插入处理器线程的数量
* Delayed_writes:用INSERT DELAYED写入的行数
* Not_flushed_delayed_rows:在INSERT DELAY队列中等待写入的行的数量
对数据的插入,如果可以容忍结果几秒以后再生效的,就可以用 INSERT DELAYED INTO语句。DELAYED调节符应用于INSERT和REPLACE语句。当DELAYED插入操作到达的时候,服务器把数据行放入一个队列中,并立即给客户端返回一个状态信息,这样客户端就可以在数据表被真正地插入记录之前继续进行操作了。如果读取者从该数据表中读取数据,队列中的数据就会被保持着,直到没有读取者为止。接着服务器开始插入延迟数据行(delayed-row)队列中的数据行。在插入操作的同时,服务器还要检查是否有新的读取请求到达和等待。如果有,延迟数据行队列就被挂起, 允许读取者继续操作。当没有读取者的时候,服务器再次开始插入延迟的数据行。 这个过程一直进行,直到队列空了为止。
使用SHOW PROCESSLIST,可以看到用户名为 DELAYED 的进程,进程数量等于 INSERT DELAYED 的表的数量,因为表级锁的存在,每个表一条以上的 DELAYED 进程是没有意义的。
注意事项:
* INSERT DELAYED应该仅用于指定值清单的INSERT语句。服务器忽略用于INSERT DELAYED...SELECT语句的DELAYED。
* 服务器忽略用于INSERT DELAYED...ON DUPLICATE UPDATE语句的DELAYED。
* 因为在行被插入前,语句立刻返回,所以您不能使用LAST_INSERT_ID()来获取AUTO_INCREMENT值。AUTO_INCREMENT值可能由语句生成。
* 对于SELECT语句,DELAYED行不可见,直到这些行确实被插入了为止。
* DELAYED在从属复制服务器中被忽略了,因为DELAYED不会在从属服务器中产生与主服务器不一样的数据。
注意,目前在队列中的各行只保存在存储器中,直到它们被插入到表中为止。这意味着,如果您强行中止了mysqld(例如,使用kill -9) 或者如果mysqld意外停止,则所有没有被写入磁盘的行都会丢失。关于Delay插入的功能,相关参数为:
* delay_key_write:该选项只适用MyISAM表。如果启用了DELAY_KEY_WRITE,说明使用该项的表的键缓冲区在每次更新索引时不被清空,只有关闭表时才清空。遮掩盖可以大大加快键的写操作,但如果你使用该特性,你应用--myisam-recover选项启动服务器,为所有MyISAM表添加自动检查(例如,--myisam-recover=BACKUP,FORCE)。
请注意--external-locking不为使用延迟键写入的表提供索引破坏保护
本参数具有下述值可以影响CREATE TABLE语句使用的DELAY_KEY_WRITE表选项的处理。
OFF:DELAY_KEY_WRITE被忽略。
ON:MySQL在CREATE TABLE中用DELAY_KEY_WRITE选项。这是 默认值。
ALL:用启用DELAY_KEY_WRITE选项创建表的相同方法对所有新打开表的进行处理。
* delayed_insert_timeout:INSERT DELAYED处理器线程终止前应等待INSERT语句的时间。
* delayed_queue_size:这是各个表中处理INSERT DELAYED语句时队列中行的数量限制。如果队列满了,执行INSERT DELAYED语句的客户端应等待直到队列内再有空间。
3.low_priority_updates
MySQL允许改变语句调度的优先级,它可以使来自多个客户端的查询更好地协作,这样单个客户端就不会由于锁定而等待很长时间。改变优先级还可以确保特定类型的查询被处理得更快。
MySQL的默认的调度策略可用总结如下:
* 写入操作优先于读取操作。
* 对某张数据表的写入操作某一时刻只能发生一次,写入请求按照它们到达的次序来处理。
* 某张数据表的多个读取操作可以同时地进行。
MySQL提供了几个语句调节符,允许你修改它的调度策略:
* LOW_PRIORITY关键字应用于DELETE、INSERT、LOAD DATA、REPLACE和UPDATE。
* HIGH_PRIORITY关键字应用于SELECT和INSERT语句。
* DELAYED关键字应用于INSERT和REPLACE语句。
LOW_PRIORITY和HIGH_PRIORITY调节符影响那些使用数据表锁的存储引擎(例如MyISAM和MEMORY)。DELAYED调节符作用于MyISAM和MEMORY数据表。
LOW_PRIORITY关键字影响DELETE、INSERT、LOAD DATA、REPLACE和UPDATE语句的执行调度。通常情况下,某张数据表正在被读取的时候,如果有写入操作到达,那么写入者一直等待读取者完成操作(查询开始之后就不能中断,因此允许读取者完成操作)。如果写入者正在等待的时候,另一个读取操作到达了,该读取操作也会被阻塞(block),因为默认的调度策略是写入者优先于读取者。当第一个读取者完成操作的时候,写入者开始操作,并且直到该写入者完成操作,第二个读取者才开始操作。
如果写入操作是一个LOW_PRIORITY(低优先级)请求,那么系统就不会认为它的优先级高于读取操作。在这种情况下,如果写入者在等待的时候,第二个读取者到达了,那么就允许第二个读取者插到写入者之前。只有在没有其它的读取者的时候,才允许写入者开始操作。理论上,这种调度修改暗示着,可能存在LOW_PRIORITY写入操作永远被阻塞的情况。如果前面的读取操作在进行的过程中一直有其它的读取操作到达,那么新的请求都会插入到LOW_PRIORITY写入操作之前。
SELECT查询的HIGH_PRIORITY(高优先级)关键字也类似。它允许SELECT插入正在等待的写入操作之前,即使在正常情况下写入操作的优先级更高。另外一种影响是,高优先级的SELECT在正常的SELECT语句之前执行,因为这些语句会被写入操作阻塞。
如果你希望所有支持LOW_PRIORITY选项的语句都默认地按照低优先级来处理,那么请使用--low-priority-updates选项来启动服务器。通过使用INSERT HIGH_PRIORITY来把INSERT语句提高到正常的写入优先级,可以消除该选项对单个INSERT语句的影响。
读为主可以设置low_priority_updates=1,写的优先级调低,告诉MYSQL尽量先处理读求
* --low-priority-updates启动mysqld。这将给所有更新(修改)一个表的语句以比SELECT语句低的优先级。在这种情况下,在先前情形的第2个SELECT语句将在UPDATE语句前执行,而不需要等候第1个SELECT完成。
* 可以使用SET LOW_PRIORITY_UPDATES=1语句指定具体连接中的所有更新应使用低优先级。参见13.5.3节,“SET语法”
* 可以用LOW_PRIORITY属性给与一个特定的INSERT、UPDATE或DELETE语句较低优先级。
* 可以用HIGH_PRIORITY属性给与一个特定的SELECT语句较高优先级。参见13.2.7节,“SELECT语法”。
* 为max_write_lock_count系统变量指定一个低值来启动mysqld来强制MySQL在具体数量的插入完成后临时提高所有等待一个表的SELECT语句的优先级。这样允许在一定数量的WRITE锁定后给出READ锁定。
* 如果你有关于INSERT结合SELECT的问题,切换到使用新的MyISAM表,因为它们支持并发的SELECT和INSERT。
* 如果你对同一个表混合插入和删除,INSERT DELAYED将会有很大的帮助。参见13.2.4.2节,“INSERT DELAYED语法”。
参数:low_priority_updates,缺省值为OFF,如果设置为1,所有INSERT、UPDATE、DELETE和LOCK TABLE WRITE语句将等待直到受影响的表没有挂起的SELECT或LOCK TABLE READ。
相关参数的建议值
这里列一下根据以往经验得到的相关参数的建议值:
* query_cache_type : 如果全部使用innodb存储引擎,建议为0,如果使用MyISAM 存储引擎,建议为2,同时在SQL语句中显式控制是否是哟你gquery cache
* query_cache_size: 根据 命中率(Qcache_hits/(Qcache_hits+Qcache_inserts)*100))进行调整,一般不建议太大,256MB可能已经差不多了,大型的配置型静态数据可适当调大
* binlog_cache_size: 一般环境2MB~4MB是一个合适的选择,事务较大且写入频繁的数据库环境可以适当调大,但不建议超过32MB
* key_buffer_size: 如果不使用MyISAM存储引擎,16MB足以,用来缓存一些系统表信息等。如果使用 MyISAM存储引擎,在内存允许的情况下,尽可能将所有索引放入内存,简单来说就是“越大越好”
* bulk_insert_buffer_size: 如果经常性的需要使用批量插入的特殊语句(上面有说明)来插入数据,可以适当调大该参数至16MB~32MB,不建议继续增大,某人8MB
* innodb_buffer_pool_size: 如果不使用InnoDB存储引擎,可以不用调整这个参数,如果需要使用,在内存允许的情况下,尽可能将所有的InnoDB数据文件存放如内存中,同样将但来说也是“越大越好”
* innodb_additional_mem_pool_size: 一般的数据库建议调整到8MB~16MB,如果表特别多,可以调整到32MB,可以根据error log中的信息判断是否需要增大
* innodb_log_buffer_size: 默认是1MB,系的如频繁的系统可适当增大至4MB~8MB。当然如上面介绍所说,这个参数实际上还和另外的flush参数相关。一般来说不建议超过32MB
* innodb_max_dirty_pages_pct: 根据以往的经验,重启恢复的数据如果要超过1GB的话,启动速度会比较慢,几乎难以接受,所以建议不大于 1GB/innodb_buffer_pool_size(GB)*100 这个值。当然,如果你能够忍受启动时间比较长,而且希望尽量减少内存至磁盘的flush,可以将这个值调整到90,但不建议超过90
InnoDB Monitors
InnoDB包含InnoDB Monitors,它打印有关InnoDB内部状态的信息。你可以使用SQL语句SHOW INNODB STATUS来取标准InnoDB Monitor的输出送到你的SQL客户端。这个信息在性能调节时有用。
mysql> SHOW INNODB STATUS\G
另一个使用InnoDB Monitors的方法时让它们不断写数据到mysqld服务器的标准输出。在这种情况下,没有输出被送到客户端。当被打开的时候,InnoDB Monitors每15秒打印一次数据。服务器输出通常被定向到MySQL数据目录里的.err日志。这个数据在性能调节时有用。在Windows上,如果你想定向输出到窗口而不是到日志文件,你必须从控制台窗口的命令行使用--console选项来启动服务器。
监视器输出包括下列类型的信息:
• 被每个激活事务持有的表和记录锁定
• 事务的锁定等待
• 线程的信号等待
• 未解决的文件I/O请求
• 缓冲池统计数据
• 主InnoDB线程的净化和插入缓冲合并活动
要让标准InnoDB Monitor写到mysqld的标准输出,请使用下列SQL语句:
CREATE TABLE innodb_monitor(a INT) ENGINE=INNODB;
监视器可以通过发出下列语句来被停止:
DROP TABLE innodb_monitor;
CREATE TABLE语法正是通过MySQL的SQL解析程序往InnoDB引擎传递命令的方法:唯一有问题的事情是表名字innodb_monitor及它是一个InnoDB表。对于InnoDB Monitor, 表的结构根本不相关。如果你在监视器正运行时关闭服务器,并且你想要再次启动监视器,你必须在可以发出新CREATE TABLE语句启动监视器之前移除表。这个语法在将来的发行版本中可能会改变。
你可以以相似的方式使用innodb_lock_monitor。除了它也提供大量锁定信息之外,它与innodb_monitor相同。一个分离的 innodb_tablespace_monitor打印存在于表空间中已创建文件片断的一个列表,并且确认表空间分配数据结构。此外,有innodb_table_monitor,用它你可以打印InnoDB内部数据词典的内容。
关于这个输出一些要注意的:
• 如果TRANSACTIONS节报告锁定等待,你的应用程序可能有锁定竞争。输出也帮助跟踪事务死锁的原因。
• SEMAPHORES节报告等待一个信号的线程和关于线程对一个互斥体或rw-lock信号需要多少次回滚或等待的统计数据。大量等待信号的线程可能是磁盘I/O的结果或者InnoDB内竞争问题的结果。竞争可能是因为查询的严重并行,或者操作系统线程计划的问题。设置innodb_thread_concurrency小于默认值在这种情况下是有帮助的。
• BUFFER POOL AND MEMORY节给你关于页面读写的统计数据。你可以从这些数计算你当前的查询正做多少文件数据I/O操作。
• ROW OPERATIONS节显示主线程正在做什么。
InnoDB发送诊断输出到stderr或文件,而不是到stdout或者固定尺寸内存缓冲,以避免底层缓冲溢出。作为一个副效果,SHOW INNODB STATUS的输出每15秒钟写到一个状态文件。这个文件的名字是innodb_status.pid,其中pid 是服务器进程ID。这个文件在MySQL数据目录里创建。正常关机之时,InnoDB删除这个文件。如果发生不正常的关机, 这些状态文件的实例可能被展示,而且必须被手动删除。在移除它们之前,你可能想要检查它们来看它们是否包含有关不正常关机的原因的有用信息。仅在配置选项innodb_status_file=1被设置之时,innodb_status.pid文件被创建。
附:SHOW STATUS的一些参数:
参数
说明
基本情况
Aborted_clients
由于客户没有正确关闭连接已经死掉,已经放弃的连接数量
Aborted_connects
尝试已经失败的MySQL服务器的连接的次数。
Connections
连接服务器(不管是否成功)的次数
Uptime
服务器工作时间
Max_used_connections
同时使用的最大连接数量
Open_files
打开文件的数量。
Open_tables
当前打开的表的数量。
Opened_tables
已经打开的表的数量。调优静态变量表缓存数table_cache:如果open_tables接近table_cache,并且opened_tables不断增长,就需要增加table_cache的值。
table_cache是所有线程打开的表的数目(一个表使用2个文件描述符),表数量多,就要大一些。增大该值可以增加mysqld需要的文件描述符的数量。根据数据库系统中表数量来决定该值,如2048。
线程使用情况
Threads_cached
线程缓存内的线程数
Threads_connected
当前打开的线程数
Threads_created
创建过的线程数。调优静态变量线程缓存数thread_cache:如果该值增加很快,当前thread_cache_size的值可能太小。缓存访问率是Threads_created/Connections。
服务器应缓存多少线程以便重新使用。当客户端断开连接时,如果线程少于thread_cache_size,则客户端的线程被放入缓存,一般配置8。
Threads_running
运行(非睡眠)状态的线程数
查询缓存
Qcache_free_blocks
缓存中相邻内存块的个数。数目大说明可能有碎片。调优方法:FLUSH QUERY CACHE;会对缓存中的碎片进行整理,从而得到一个空闲块,如果flush运行的时间很长,说明缓存太大了,可以适当调小静态变量query_cache_size的值。
Qcache_free_memory
缓存中剩余的内存。调优静态参数query_cache_size:如果剩余内存不足,可以增加该值,如设置query_cache_size=64M
Qcache_hits
查询缓存命中次数,该值越大越好
Qcache_inserts
插入查询缓存的次数。缓存命中率 = 1 – Qcache_hits/ Qcache_inserts。80%以上的查询缓存命中率就算合格。
Qcache_lowmem_prunes
查询缓存过低的次数。缓存出现内存不足并且必须要进行清理以便为更多查询提供空间的次数。这个数字最好长时间来看;如果这个数字在不断增长,就表示可能碎片非常严重,或者内存很少。(上面的free_blocks 和 free_memory 可以告诉您属于哪种情况)。
Qcache_not_cached
不适合进行缓存的查询的数量,通常是由于这些查询不是 SELECT 语句。
Qcache_queries_in_cache
当前缓存的查询(和响应)的数量。
Qcache_total_blocks
缓存中块的数量。
SQL执行频率
Com_select
执行select操作次数
Com_insert
执行insert操作次数
Com_update
执行update操作次数
Com_delete
执行delete操作次数
Com_commit
事务执行commit操作次数
Comm_rollback
事务执行rollback操作次数。如果回滚频繁,就说明程序存在某些问题。
Slow_queries
慢查询的次数。调优SQL性能:如果该值增加很快,需要分析慢查询日志,针对查询SQL优化。
Innodb_rows_read
执行select返回的行数。以下几个InnoDB的。
Innodb_rows_inserted
执行insert操作的行数。通过这几个参数,可以知道数据库是查询为主还是插入为主。
Innodb_rows_updated
执行update操作的行数
Innodb_rows_deleted
执行delete操作的行数
Sort_merge_passes
排序算法已经执行的合并的数量。调优静态变量sort_buffer_size:如果该值很大,说明排序缓冲区太小,如设置sort_buffer_size = 5M
当 MySQL 必须要进行排序时,就会在从磁盘上读取数据时分配一个排序缓冲区来存放这些数据行。如果要排序的数据太大,那么数据就必须保存到磁盘上的临时文件中,并再次进行排序。
索引使用情况
Handler_read_first
使用全索引扫描的次数。如SELECT col1 FROM foo,假定col1有索引
Handler_read_key
使用索引次数,该值越高越好。
Handler_read_next
按照键顺序读下一行的请求数。使用索引描述时,从数据文件取数据的次数
Handler_read_prev
使用索引描述时,按索引倒序从数据文件取数据的次数。一般是order by/desc查询
Handler_read_rnd
查询直接操作数据文件的次数,有可能未使用索引
Handler_read_rnd_next
在数据文件中读下一行的请求数。若该值非常大,说明使用了大量的表扫描,索引使用率不高或没有使用索引。Handler_read_rnd_next/Com_select是表扫描比率,如果该值超过 4000,就应该调优静态参数read_buffer_size。如read_buffer_size=1M,若超过8M,那么就要优化SQL了。
锁使用情况
Innodb_row_lock_current_waits
当前等待行锁的行数
Innodb_row_lock_time
行锁定用的总时间(ms)
Innodb_row_lock_time_avg
行锁定的平均时间(ms)。该值大,说明锁冲突大
Innodb_row_lock_time_max
行锁定的最长时间(ms)
Innodb_row_lock_waits
行锁定必须等待的时间(ms)。该值大,说明锁冲突大
Created_tmp_tables 当执行语句时,已经被创造了的隐含临时表的数量。
Delayed_insert_threads 正在使用的延迟插入处理器线程的数量。
Delayed_writes 用INSERT DELAYED写入的行数。
Delayed_errors 用INSERT DELAYED写入的发生某些错误(可能重复键值)的行数。
Flush_commands 执行FLUSH命令的次数。Handler_delete 请求从一张表中删除行的次数。
Handler_update 请求更新表中一行的次数。
Handler_write 请求向表中插入一行的次数。Key_blocks_used 用于关键字缓存的块的数量。
Key_read_requests 请求从缓存读入一个键值的次数。
Key_reads 从磁盘物理读入一个键值的次数。
Key_write_requests 请求将一个关键字块写入缓存次数。
Key_writes 将一个键值块物理写入磁盘的次数。Not_flushed_key_blocks 在键缓存中已经改变但是还没被清空到磁盘上的键块。
安装要求
安装环境:CentOS-6.3
安装方式:源码编译安装
软件名称:mysql-cluster-gpl-7.2.6-linux2.6-x86_64.tar.gz
下载地址:http://mysql.mirror.kangaroot.net/Downloads/
软件安装位置:/usr/local/mysql
数据存放位置:/var/mysql/data
日志存放位置:/var/mysql/logs集群设计
首先设计集群的安装分配方式,我共需要5台服务器,服务器分配如下:
管理节点: 192.168.15.231
sql节点1: 192.168.15.232
sql节点2: 192.168.15.233
数据节点1: 192.168.15.234
数据节点2: 192.168.15.235
设备的连接方式如下图所示:
注意:目前这种设计存在的问题是管理节点是单点的,231挂掉后整个集群就会瘫痪,先不管这个问题,首先把这个简单的MySQL集群先搭建起来。
检查安装的mysql
检查系统中已经安装过的mysql信息,操作如下:[root@localhost /]# rpm -qa | grep mysql [root@localhost /]# service mysql status如果安装过其他版本的mysql,请卸载,操作如下:
[root@localhost /]# /etc/init.d/mysqld stop //关闭目前的mysql服务 [root@localhost /]# ps -ef | grep mysql //检验mysql是否已经关闭 #如果没关闭,执行kill -9 端口号 #执行删除 rpm -e --allmatches --nodeps mysql mysql-server rm -rf /var/lib/mysql // 删除mysql的安装目录管理节点
管理节点安装
安装管理节点(192.168.15.231)
[root@localhost /]# groupadd mysql [root@localhost /]# useradd mysql -g mysql [root@localhost /]# cd /usr/local [root@localhost local]# tar -zxv -f mysql-cluster-gpl-7.2.6-linux2.6-x86_64.tar.gz [root@localhost local]# mv mysql-cluster-gpl-7.2.6-linux2.6-x86_64 mysql [root@localhost local]# chown -R mysql:mysql mysql [root@localhost local]# cd mysql [root@localhost mysql]# scripts/mysql_install_db --user=mysql管理节点配置
[root@localhost ~]# mkdir /var/lib/mysql-cluster [root@localhost ~]# cd /var/lib/mysql-cluster [root@localhost mysql-cluster]# vi + /var/lib/mysql-cluster/config.ini在config.ini 中添加以下内容:
[NDBD DEFAULT] NoOfReplicas=1 [TCP DEFAULT] portnumber=3306 [NDB_MGMD] #设置管理节点服务器 HostName=192.168.15.231 DataDir=/var/mysql/data [NDBD] #设置存储节点服务器(NDB节点) HostName=192.168.15.234 DataDir=/var/mysql/data [NDBD] #第二个NDB节点 HostName=192.168.15.235 DataDir=/var/mysql/data [MYSQLD] #设置SQL节点服务器 HostName=192.168.15.232 [MYSQLD] #第二个SQL节点 HostName=192.168.15.233管理节点启动
[root@localhost ~]#/usr/local/mysql/bin/ndb_mgmd -f /var/lib/mysql-cluster/config.ini [root@localhost ~]# mkdir /var/mysql/logs [root@localhost ~]# netstat -lntpu看到tcp 0 0 0.0.0.0:1186开放说明启动正常
开启管理节点服务器的1186端口管理节点检验
执行以下操作:
[root@localhost /]# ndb_mgm // 管理节点 -- NDB Cluster -- Management Client -- ndb_mgm> show Connected to Management Server at: localhost:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 (not connected, accepting connect from 192.168.15.234) id=3 (not connected, accepting connect from 192.168.15.235) [ndb_mgmd(MGM)] 1 node(s) id=1 @192.168.15.231 (mysql-5.5.22 ndb-7.2.6) [mysqld(API)] 2 node(s) id=4 (not connected, accepting connect from 192.168.15.232) id=5 (not connected, accepting connect from 192.168.15.233)管理节点关闭
[root@localhost /]# /usr/local/mysql/bin/ndb_mgm -e shutdown #成功后终端打印出以下信息 Connected to Management Server at: 192.168.15.236:1186 3 NDB Cluster node(s) have shutdown. Disconnecting to allow management server to shutdown.数据节点
数据节点安装
数据节点1: 192.168.15.234
数据节点2: 192.168.15.235[root@localhost /]# groupadd mysql [root@localhost /]# useradd mysql -g mysql [root@localhost /]# cd /usr/local [root@localhost local]# tar -zxv -f mysql-cluster-gpl-7.2.6-linux2.6-x86_64.tar.gz [root@localhost local]# mv mysql-cluster-gpl-7.2.6-linux2.6-x86_64 mysql [root@localhost local]# chown -R mysql:mysql mysql [root@localhost local]# cd mysql [root@localhost mysql]# scripts/mysql_install_db --user=mysql [root@localhost mysql]# cp support-files/my-medium.cnf /etc/my.cnf [root@localhost mysql]# cp support-files/mysql.server /etc/init.d/mysqld数据节点配置
对数据节点进行配置,执行以下操作:
[root@localhost mysql]# mkdir /var/mysql/data [root@localhost mysql]# mkdir /var/mysql/logs [root@localhost mysql]# vi /etc/my.cnf向文件追加以下内容:
[MYSQLD] ndbcluster ndb-connectstring=192.168.15.231 [MYSQL_CLUSTER] ndb-connectstring=192.168.15.231 [NDB_MGM] connect-string=192.168.15.231数据节点启动
启动此处时,管理节点服务器防火墙必须开启1186,3306端口。
注意:只是在第一次启动或在备份/恢复或配置变化后重启ndbd时,才加–initial参数!
第一次启动如下:[root@localhost mysql]#/usr/local/mysql/bin/ndbd --initial 2013-01-30 13:43:53 [ndbd] INFO -- Angel connected to '192.168.15.231:1186' 2013-01-30 13:43:53 [ndbd] INFO -- Angel allocated nodeid: 2正常启动方式:
[root@localhost mysql]# /usr/local/mysql/bin/ndbd数据节点关闭
[root@localhost /]# /etc/rc.d/init.d/mysqld stop或者
[root@localhost mysql]# /etc/init.d/mysql stop Shutting down MySQL.. SUCCESS!/usr/local/mysql/bin/mysqladmin -uroot shutdownSQL节点安装
SQL节点安装
SQL节点和存储节点(NDB节点)安装相同,都执行以下操作;
sql节点1: 192.168.15.232
sql节点2: 192.168.15.233[root@localhost /]# groupadd mysql [root@localhost /]# useradd mysql -g mysql [root@localhost /]# cd /usr/local [root@localhost local]# tar -zxv -f mysql-cluster-gpl-7.2.6-linux2.6-x86_64.tar.gz [root@localhost local]# mv mysql-cluster-gpl-7.2.6-linux2.6-x86_64 mysql [root@localhost local]# chown -R mysql:mysql mysql [root@localhost local]# cd mysql [root@localhost mysql]# scripts/mysql_install_db --user=mysql [root@localhost mysql]# cp support-files/my-medium.cnf /etc/my.cnf [root@localhost mysql]# cp support-files/mysql.server /etc/init.d/mysqldSQL节点配置
执行以下操作:
[root@localhost mysql]# mkdir /var/mysql/data //创建存储数据的文件夹 [root@localhost mysql]# mkdir /var/mysql/logs //创建存储日志的文件夹 [root@localhost mysql]# vi /usr/local/mysql/my.cnf //修改配置文件追加以下内容:
[MYSQLD] ndbcluster ndb-connectstring=192.168.15.231 [MYSQL_CLUSTER] ndb-connectstring=192.168.15.231 [NDB_MGM] connect-string=192.168.15.231SQL节点启动
执行以下操作:
[root@localhost mysql]# service mysqld start Starting MySQL.. SUCCESS!SQL节点关闭
最直接的方式:
[root@localhost mysql]# /usr/local/mysql/bin/mysqladmin -uroot shutdown[root@localhost /]# /etc/rc.d/init.d/mysqld stop或者
[root@localhost mysql]# /etc/init.d/mysql stop Shutting down MySQL.. SUCCESS!功能测试
在管理节点(192.168.15.231)上查看服务状态
[root@localhost ~]# /usr/local/mysql/bin/ndb_mgm -- NDB Cluster -- Management Client -- ndb_mgm> show Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 @192.168.15.234 (mysql-5.5.22 ndb-7.2.6, Nodegroup: 0, Master) id=3 @192.168.15.235 (mysql-5.5.22 ndb-7.2.6, Nodegroup: 1) [ndb_mgmd(MGM)] 1 node(s) id=1 @192.168.15.231 (mysql-5.5.22 ndb-7.2.6) [mysqld(API)] 2 node(s) id=4 @192.168.15.232 (mysql-5.5.22 ndb-7.2.6) id=5 @192.168.15.233 (mysql-5.5.22 ndb-7.2.6)可以看到这里的数据节点、管理节点、sql节点都是正常的。
注意:
- 在建表的时候一定要用ENGINE=NDB或ENGINE=NDBCLUSTER指定使用NDB集群存储引擎,或用ALTER TABLE选项更改表的存储引擎。
- NDB表必须有一个主键,因此创建表的时候必须定义主键,否则NDB存储引擎将自动生成隐含的主键。
- Sql节点的用户权限表仍然采用MYISAM存储引擎保存的,所以在一个Sql节点创建的MySql用户只能访问这个节点,如果要用同样的用户访
问别的Sql节点,需要在对应的Sql节点追加用户。虽然在MySql Cluster7.2版本开始提供了”用户权限共享”。数据同步性测试
在一个数据节点上进行相关数据库的创建,然后到另外一个数据节点上看看数据是否同步。
第1步:
SQL节点1(192.168.15.232)上增加数据:[root@localhost mysql]# /etc/rc.d/init.d/mysqld status //检验mysql是否运行 [root@localhost mysql]# /etc/rc.d/init.d/mysqld start //启动mysql [root@localhost mysql]# /usr/local/mysql/bin/mysql -u root -p Enter password: mysql> show databases; mysql> create database testdb2; mysql> use testdb2; mysql> CREATE TABLE td_test2 (i INT) ENGINE=NDB; //这里必须指定数据库表的引擎为NDBCLUSTER,与配置文件中的名称相同 mysql> INSERT INTO td_test2() VALUES (1); mysql> INSERT INTO td_test2() VALUES (152); mysql> SELECT * FROM td_test2;第2步:
进入到SQL节点2(192.168.15.233)上查看数据mysql> use testdb2; Database changed mysql> SELECT * FROM td_test2; +------+ | i | +------+ | 126 | | 1 | +------+ 2 rows in set (0.01 sec)查看表的引擎是不是NDB:
>show create table td_test2;第3步:
反向测试,SQL节点2(192.168.15.233)上增加数据:mysql> create database bb; mysql> use bb; mysql> CREATE TABLE td_test3 (i INT) ENGINE=NDB; mysql> INSERT INTO td_test3 () VALUES (98); mysql> SELECT * FROM td_test3;SQL节点1(192.168.15.232)上查看数据:
mysql> use bb; Database changed mysql> SELECT * FROM td_test3; +------+ | i | +------+ | 98 | +------+ 1 row in set (0.00 sec)关闭集群
先关闭管理节点,然后关闭SQL节点和数据节点。
集群启动操作顺序
要再次启动集群,按照以下顺序执行:
管理节点 -> 数据节点 –> SQL节点注意:此次启动数据节点时不要加”–initial”参数。安装及测试中的错误
启动中的错误
错误提示:
Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
解决办法1(端口占用) netstat -anp |grep 3306
kill -9 进程号
解决办法1(权限问题) [root@localhost mysql]# chown -R mysql:mysql /var/mysql //修改自定义文件夹的访问权限
三台服务器篇一、介绍
========
这篇文档旨在介绍如何安装配置基于2台服务器的MySQL集群。并且实现任意一台服务器出现问题或宕机时MySQL依然能够继续运行。注意!
虽
然这是基于2台服务器的MySQL集群,但也必须有额外的第三台服务器作为管理节点,但这台服务器可以在集群启动完成后关闭。同时需要注意的是
并不推荐在集群启动完成后关闭作为管理节点的服务器。尽管理论上可以建立基于只有2台服务器的MySQL集群,但是这样的架构,一旦一台服务器宕机之后集
群就无法继续正常工作了,这样也就失去了集群的意义了。出于这个原因,就需要有第三台服务器作为管理节点运行。另外,可能很多朋友都没有3台服务器的实际环境,可以考虑在VMWare或其他虚拟机中进行实验。
下面假设这3台服务的情况:
Server1: mysql1.vmtest.net 192.168.0.1 Server2: mysql2.vmtest.net 192.168.0.2 Server3: mysql3.vmtest.net 192.168.0.3Servers1
和Server2作为实际配置MySQL集群的服务器。对于作为管理节点的Server3则要求较低,只需对Server3的系
统进行很小的调整并且无需安装MySQL,Server3可以使用一台配置较低的计算机并且可以在Server3同时运行其他服务。二、在Server1和Server2上安装MySQL
=================================
从http://www.mysql.com上下载mysql-max-4.1.9-pc-linux-gnu-i686.tar.gz
注意:必须是max版本的MySQL,Standard版本不支持集群部署!以下步骤需要在Server1和Server2上各做一次
# mv mysql-max-4.1.9-pc-linux-gnu-i686.tar.gz /usr/local/ # cd /usr/local/ # groupadd mysql # useradd -g mysql mysql # tar -zxvf mysql-max-4.1.9-pc-linux-gnu-i686.tar.gz # rm -f mysql-max-4.1.9-pc-linux-gnu-i686.tar.gz # mv mysql-max-4.1.9-pc-linux-gnu-i686 mysql # cd mysql # scripts/mysql_install_db --user=mysql # chown -R root . # chown -R mysql data # chgrp -R mysql . # cp support-files/mysql.server /etc/rc.d/init.d/mysqld # chmod +x /etc/rc.d/init.d/mysqld # chkconfig --add mysqld此时不要启动MySQL!
三、安装并配置管理节点服务器(Server3)
=====================================
作为管理节点服务器,Server3需要ndb_mgm和ndb_mgmd两个文件:从http://www.mysql.com上下载mysql-max-4.1.9-pc-linux-gnu-i686.tar.gz
# mkdir /usr/src/mysql-mgm # cd /usr/src/mysql-mgm # tar -zxvf mysql-max-4.1.9-pc-linux-gnu-i686.tar.gz # rm mysql-max-4.1.9-pc-linux-gnu-i686.tar.gz # cd mysql-max-4.1.9-pc-linux-gnu-i686 # mv bin/ndb_mgm . # mv bin/ndb_mgmd . # chmod +x ndb_mg* # mv ndb_mg* /usr/bin/ # cd # rm -rf /usr/src/mysql-mgm现在开始为这台管理节点服务器建立配置文件:
# mkdir /var/lib/mysql-cluster # cd /var/lib/mysql-cluster # vi config.ini在config.ini中添加如下内容:
[NDBD DEFAULT] NoOfReplicas=2 [MYSQLD DEFAULT] [NDB_MGMD DEFAULT] [TCP DEFAULT] # Managment Server [NDB_MGMD] HostName=192.168.0.3 #管理节点服务器Server3的IP地址 # Storage Engines [NDBD] HostName=192.168.0.1 #MySQL集群Server1的IP地址 DataDir= /var/lib/mysql-cluster [NDBD] HostName=192.168.0.2 #MySQL集群Server2的IP地址 DataDir=/var/lib/mysql-cluster # 以下2个[MYSQLD]可以填写Server1和Server2的主机名。 # 但为了能够更快的更换集群中的服务器,推荐留空,否则更换服务器后必须对这个配置进行更改。 [MYSQLD] [MYSQLD]保存退出后,启动管理节点服务器Server3:
# ndb_mgmd启动管理节点后应该注意,这只是管理节点服务,并不是管理终端。因而你看不到任何关于启动后的输出信息。
四、配置集群服务器并启动MySQL
=============================
在Server1和Server2中都需要进行如下改动:# vi /etc/my.cnf [mysqld] ndbcluster ndb-connectstring=192.168.0.3 #Server3的IP地址 [mysql_cluster] ndb-connectstring=192.168.0.3 #Server3的IP地址保存退出后,建立数据目录并启动MySQL:
# mkdir /var/lib/mysql-cluster # cd /var/lib/mysql-cluster # /usr/local/mysql/bin/ndbd --initial # /etc/rc.d/init.d/mysqld start可以把/usr/local/mysql/bin/ndbd加到/etc/rc.local中实现开机启动。
注意:只有在第一次启动ndbd时或者对Server3的config.ini进行改动后才需要使用--initial参数!五、检查工作状态
================
回到管理节点服务器Server3上,并启动管理终端:# /usr/bin/ndb_mgm
键入show命令查看当前工作状态:(下面是一个状态输出示例)[root@mysql3 root]# /usr/bin/ndb_mgm -- NDB Cluster -- Management Client -- ndb_mgm> show Connected to Management Server at: localhost:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 @192.168.0.1 (Version: 4.1.9, Nodegroup: 0, Master) id=3 @192.168.0.2 (Version: 4.1.9, Nodegroup: 0) [ndb_mgmd(MGM)] 1 node(s) id=1 @192.168.0.3 (Version: 4.1.9) [mysqld(API)] 2 node(s) id=4 (Version: 4.1.9) id=5 (Version: 4.1.9) ndb_mgm>如果上面没有问题,现在开始测试MySQL:
注意,这篇文档对于MySQL并没有设置root密码,推荐你自己设置Server1和Server2的MySQL root密码。在Server1中:
# /usr/local/mysql/bin/mysql -u root -p > use test; > CREATE TABLE ctest (i INT) ENGINE=NDBCLUSTER; > INSERT INTO ctest () VALUES (1); > SELECT * FROM ctest;应该可以看到1 row returned信息(返回数值1)。
如果上述正常,则换到Server2上重复上面的测试,观察效果。如果成功,则在Server2中执行INSERT再换回到Server1观察是否工作正常。
如果都没有问题,那么恭喜成功!六、破坏性测试
==============
将Server1或Server2的网线拔掉,观察另外一台集群服务器工作是否正常(可以使用SELECT查询测试)。测试完毕后,重新插入网线即可。如果你接触不到物理服务器,也就是说不能拔掉网线,那也可以这样测试:
在Server1或Server2上:# ps aux | grep ndbd
将会看到所有ndbd进程信息:root 5578 0.0 0.3 6220 1964 ? S 03:14 0:00 ndbd
root 5579 0.0 20.4 492072 102828 ? R 03:14 0:04 ndbd
root 23532 0.0 0.1 3680 684 pts/1 S 07:59 0:00 grep ndbd然后杀掉一个ndbd进程以达到破坏MySQL集群服务器的目的:
# kill -9 5578 5579
之后在另一台集群服务器上使用SELECT查询测试。并且在管理节点服务器的管理终端中执行show命令会看到被破坏的那台服务器的状态。
测试完成后,只需要重新启动被破坏服务器的ndbd进程即可:# ndbd
注意!前面说过了,此时是不用加--inital参数的!至此,MySQL集群就配置完成了!