服务器维护常用命令
一、 常用命令
pstree查看进程树。可以很清楚的看到进程之间的关系;
Top:查看各进程的占用资源的情况;
du -h --max-depth=1 显示当前目录中所有子目录的大小;
w 查看服务器的load情况
bigip 在预发布机器上使用命令“bigip sh ${ip/机器名} {username}” 可以检查机器是在F5上状态是disable还是enable.
gm.sh "curl http://localhost/monitor/ok.html" 在预发布机器上检查各个服务器的健康检查页面。
gm.sh "ps amx | grep httpd | wc -l" 在预发布机器上检查各个服务器的http链接数
二、 proc下的伪文件。 如:meminfo 检查内存信息,cpuinfo 内核信息。
cat /proc/cpuinfo 检查cpu的信息。我们的一些程序根据cpu内核的数量做过优化(如:memcached,假的多核可能会引起一些bug。)
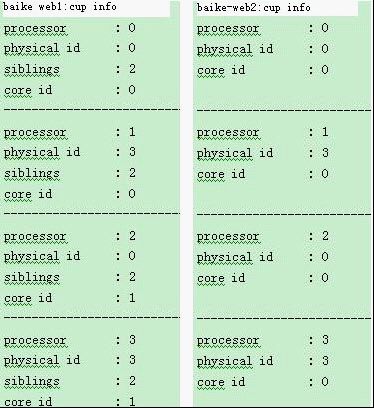
如上图 baike-web1 是4核的,baike-web2是双核超线程的。
拥有相同 physical id 的所有逻辑处理器共享同一个物理插座。每个 physical id 代表一个唯一的物理封装。Siblings 表示位于这一物理封装上的逻辑处理器的数量,如果不存在表示1。每个 core id 均代表一个唯一的处理器内核。所有带有相core id 的逻辑处理器均位于同一个处理器内核上。如果有一个以上逻辑处理器拥有相同的 core id 和 physical id,则说明系统支持超线程(HT)技术。如果有两个或两个以上的逻辑处理器拥有相同的 physical id,但是 core id不同,则说明这是一个多内核处理器。
三、 网络连接
netstat: -t: 显示TCP链接信息;-u: 显示UDP链接信息;-n直接显示ip,不做名称转换;-p: 显示相应的进程PID以及名称(要root权限)
如果要查看关于sockets更详细占用信息等,可以使用lsof.
a) netstat -anp|grep java|grep 3306|wc –l检查Java进程中数据库的链接数量
b) netstat -na|grep ESTABLISHED|awk '{print $4}'|grep ":80$"|wc –l 检查已经建立的80端口的连接数
c) netstat -na |grep “:2088” 检查搜索引擎的连接数
四、 dump java进程堆栈
a) kill -3 ${java进程Id},可以在java进程的日志中看到输出(jboss 记录在jboss_stdout.log中)
b) jstack $pid. 直接dump当前进程的的堆栈信息。
对于thread dump信息,主要关注的是线程的状态和其执行堆栈,特别是load很高的时候,通过thread dump可以看到线程到底在干嘛,从中找出问题。 线程的状态一般为三类: runable:当前可以运行的线程, Waiting on monitor:线程主动wait, Waiting for monitor entry:线程等锁. Cpu很忙则关注runnable的线程,Cpu闲则关注waiting for monitor entry的线程。
五、 java内存溢出
1、 可以先用 jstat -gcutil ${pid} {interval} 看看java内存回收的动态信息。 interval– 表示间隔打印的时间,单位为毫秒
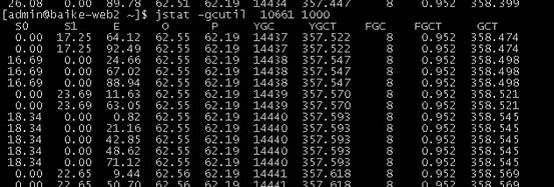
图中参数含义如下:
S0 — Heap上的 Survivor space 0区已使用空间的百分比
S1 — Heap上的 Survivor space 1 区已使用空间的百分比
E — Heap上的 Eden space 区已使用空间的百分比
O — Heap上的 Old space 区已使用空间的百分比
P — Perm space 区已使用空间的百分比
YGC — 从应用程序启动到采样时发生 Young GC 的次数
YGCT– 从应用程序启动到采样时 Young GC 所用的时间(单位秒)
FGC — 从应用程序启动到采样时发生 Full GC 的次数
FGCT– 从应用程序启动到采样时 Full GC 所用的时间(单位秒)
2. 使用jmap 来dump java内存中全部对象,分析死锁的位置。
jmap -histo $pid 快速查看当前内存中各个Java对象的大小和数量
jmap -dump:live,format=b,file=heap.dmp $pid 可以将jvm堆栈中的信息全部复制到文件head.dmp中,注意这个heap.dmp文件会比较大, 线上jboss分配的内存一般为2g,当内存溢出时dump出来的head.dmp文件也是2g,所以dump的时间也比较长,一般会有半个小时.
日志文件生成后运行命令“jhat -J-mx768m -port 7001 heap.dmp”分析堆栈日志(注意不要在线上服务器上分析)。 访问 http://localhost:7001可以查看分析报告。
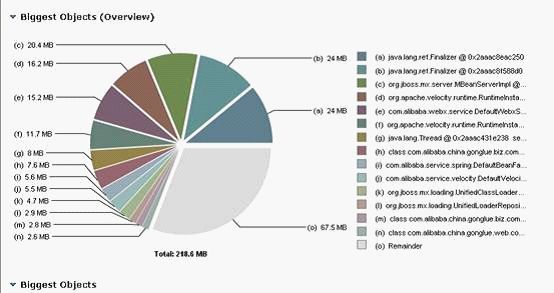
或者可以使用eclipse 的mat插件分析,它可以以图形形式分析出内存中的java对象的分布: (插件地址http://download.eclipse.org/mat/1.0/update-site/).导入后可以生成一个图形报表
六、 7001端口报警。
一般情况是jboss挂掉了。因为java进程已经退出。1首先需要查看:jboss_stdout.log,它会告诉你jboss crash的一些信息,它还会告诉你在jboss crash有一个详细的出错报告, 位置在/web-deploy/bin/hs_err_pid.log
七、 cookie日志分析
cat cookie_log|awk '{print $1} '|grep -v "172.16"|grep -v "127.0.0.1"|sort|uniq -c|sort -n |tail -n 10 提取访问量前10位的ip.
cat cookie_log |grep '09/Dec/2010:18:01'|wc –l 检查18:01这一分钟的访问总量。
cat cookie_log|grep 'HTTP/.../" [4|5]'|more 查看响应出错的请求。
cat cookie_log |grep -E 'Googlebot|Baiduspider'|wc –l统计google和baike爬虫的访问量。
一、linux重定向
1基本概念
(这是理解后面的知识的前提,请务必理解)
a、 I/O重定向通常与 FD(File Descriptor:文件描述符)有关,shell的FD通常为10个,即 0~9;
b、 常用FD有3个,为0(stdin,标准输入)、1(stdout,标准输出)、2(stderr,标准错误输出),默认与keyboard、monitor有关;
c、 用 < 来改变读进的数据信道(stdin),使之从指定的档案读进;
d、 用 > 来改变送出的数据信道(stdout, stderr),使之输出到指定的档案;
e、 0 是 < 的默认值,因此 < 与 0<是一样的;同理,> 与 1> 是一样的;
f、 在IO重定向 中,stdout 与 stderr 的管道会先准备好,才会从 stdin 读进资料;
g、 管道“|”(pipe line):上一个命令的 stdout 接到下一个命令的 stdin;
h、 tee 命令是在不影响原本 I/O 的情况下,将 stdout 复制一份到档案去;
i、 bash(ksh)执行命令的过程:分析命令-变量求值-命令替代(``和$( ))-重定向-通配符展开-确定路径-执行命令;
j、 ( ) 将 command group 置于 sub-shell 去执行,也称 nested sub-shell,它有一点非常重要的特性是:继承父shell的Standard input, output, and
error plus any other open file descriptors。
k、 exec 命令:常用来替代当前 shell 并重新启动一个 shell,换句话说,并没有启动子 shell。使用这一命令时任何现有环境都将会被清除。exec 在对文件描述符进行操作的时候
,也只有在这时,exec 不会覆盖你当前的 shell 环境。
2基本IO
- cmd > file 把 stdout 重定向到 file 文件中;
- cmd >> file 把 stdout 重定向到 file 文件中(追加);
- cmd 1> file 把 stdout 重定向到 file 文件中;
- cmd > file 2>&1 把 stdout 和 stderr 一起重定向到 file 文件中;
- cmd 2> file 把 stderr 重定向到 file 文件中;
- cmd 2>> file 把 stderr 重定向到 file 文件中(追加);
- cmd >> file 2>&1 把 stdout 和 stderr 一起重定向到 file 文件中(追加);
- cmd < file >file2 cmd 命令以 file 文件作为 stdin,以 file2 文件作为 stdout;
- cat <>file 以读写的方式打开 file;
- cmd < file cmd 命令以 file 文件作为 stdin;
- cmd << delimiter Here document,从 stdin 中读入,直至遇到 delimiter 分界符。
3进阶IO
>&n 使用系统调用 dup (2) 复制文件描述符 n 并把结果用作标准输出;
<&n 标准输入复制自文件描述符 n;
<&- 关闭标准输入(键盘);
>&- 关闭标准输出;
n<&- 表示将 n 号输入关闭;
n>&- 表示将 n 号输出关闭;
上述所有形式都可以前导一个数字,此时建立的文件描述符由这个数字指定而不是缺省的 0 或 1。如:
... 2>file 运行一个命令并把错误输出(文件描述符 2)定向到 file。
... 2>&1 运行一个命令并把它的标准输出和输出合并。(严格的说是通过复制文件描述符 1 来建立文件描述符 2 ,但效果通常是合并了两个流。)
我们对 2>&1详细说明一下 :2>&1 也就是 FD2=FD1 ,这里并不是说FD2 的值 等于FD1的值,因为 > 是改变送出的数据通道,也就是说把 FD2 的 “数据输出通道” 改为 FD1
的 “数据输出通道”。如果仅仅这样,这个改变好像没有什么作用,因为 FD2 的默认输出和 FD1的默认输出本来都是 monitor,一样的! 但是,当 FD1 是其他文件,甚至是其他 FD
时,这个就具有特殊的用途了。请大家务必理解这一点。
- exec 1>outfilename # 打开文件outfilename作为stdout。
- exec 2>errfilename # 打开文件 errfilename作为 stderr。
- exec 0<&- # 关闭 FD0。
- exec 1>&- # 关闭 FD1。
- exec 5>&- # 关闭 FD5。
from: http://baike.baidu.com/view/2173319.htm
二、VI几个常用的技巧
0 光标定位到当前行行首,非输入模式
$ (shift+4)光标定位到当前行行尾,非输入模式
1G 文件头(注:这里的1表示要去到的行号,如果转到第2行,则是2G,这里一定是大写的G)
G(shift+g,大写锁定键+g) 文尾
A(Shift+a)当前行行尾,并进入编辑状态
ctrl+f 向上翻页
ctrl+b 向下翻页
ctrl+u 向上翻半页
ctrl+d 向下翻半页
查找:
/pattern<Enter> :向下查找pattern匹配字符串
?pattern<Enter>:向上查找pattern匹配字符串
使用了查找命令之后,使用如下两个键快速查找:
n:按照同一方向继续查找
N:按照反方向查找
Example:
如我们要搜索"password",只需要输入"/password"回车即可
除此之外,pattern还可以使用一些特殊字符,包括(/、^、$、*、.),其中前三个这两个是vi与vim通用的,“/”为转义字符。
Example:
- /^abc<Enter> #查找以abc开始的行,不包括以空格开头的行
- /abc$<Enter> #查找以abc结束的行
- //^test<Enter> #查找^test字符串
替换:
:[%]s/old/new/[g]
- :s/old_value/new_value/ #替换当前行第一个 old_value 为 new_value
- :s/old_value/new_value/g #替换当前行所有 old_value 为 new_value
- :n,$s/old_value/new_value/ #替换第 n 行开始到最后一行中每一行的第一个 old_value 为 new_value
- :n,$s/old_value/new_value/g #替换第 n 行开始到最后一行中每一行所有 old_value 为 new_value(n 为数字,若 n 为 .,表示从当前行开始到最后一行)
- :%s/old_value/new_value/ #(等同于 :g/old_value/s//new_value/) 替换每一行的第一个 old_value 为 new_value
- :%s/old_value/new_value/g #(等同于 :g/old_value/s//new_value/g) 替换每一行中所有 old_value 为 new_value
以上的操作都不是在编辑状态下使用的,机使用前需要先猛击ESC.
三、Linux xargs命令
xargs是给命令传递参数的一个过滤器,也是组合多个命令的一个工具。它把一个数据流分割为一些足够小的块,以方便过滤器和命令进行处理。通常情况下,xargs从管道或者stdin中读取数据,但是它也能够从文件的输出中读取数据。xargs的默认命令是echo,这意味着通过管道传递给xargs的输入将会包含换行和空白,不过通过xargs的处理,换行和空白将被空格取代。
xargs 是一个强有力的命令,它能够捕获一个命令的输出,然后传递给另外一个命令,下面是一些如何有效使用xargs 的实用例子。
1. 当你尝试用rm 删除太多的文件,你可能得到一个错误信息:/bin/rm Argument list too long. 用xargs 去避免这个问题
# find ~ -name ‘*.log’ -print0 | xargs -0 rm -f
2. 获得/etc/ 下所有*.conf 结尾的文件列表,有几种不同的方法能得到相同的结果,下面的例子仅仅是示范怎么实用xargs ,在这个例子中实用 xargs将find 命令的输出传递给ls -l
# find /etc -name "*.conf" | xargs ls –l
3. 假如你有一个文件包含了很多你希望下载的URL, 你能够使用xargs 下载所有链接
# cat url-list.txt | xargs wget –c
4. 查找所有的jpg 文件,并且压缩它
# find / -name *.jpg -type f -print | xargs tar -cvzf images.tar.gz
5. 拷贝所有的图片文件到一个外部的硬盘驱动
# ls *.jpg | xargs -n1 -i cp {} /external-hard-drive/directory
其他的示列:
find /tmp -name core -type f -print | xargs /bin/rm -f
查找目录/tmp下面为core的文件并删除,不过这里需要注意的是如果文件名中有空格或者换行符,该命令就不会正确的执行.
find /tmp -name core -type f -print0 | xargs -0 /bin/rm -f
查找目录/tmp下面为core的文件并删除,这时候就可以正确的处理文件名中有空格或者换行符的文件了.
find /tmp -depth -name core -type f -delete
查找目录/tmp下面为core的文件并删除,此时不需要使用fork和exec来启动,因为我们不需要使用额外的xargs处理.
cut -d: -f1 < /etc/passwd | sort | xargs echo
显示/etc/passwd中的用户名