MongoDB之Shard初步认识
准备工作
1、 什么是shard
副本集实现了网站的安全备份和故障的无缝转移,但是并不能实现数据的大容量存储,MongoDB实现的是分布式部署,把数据保存到其他机器上。实现这一过程的就是分片。
2、 什么时候需要分片
a) 用光了当前机器的磁盘空间
b) 单个的Mongod已经无法提供你要的写入性能了
c) 需要把大部分数据驻留在内存中籍此来提供更好的性能
3、 分片需要的三个部分
a) shard服务器(Shard Server)。Shard服务器是存储实际数据的分片,每个Shard可以是一个mongod实例,也可以是一组mongod实例构成的Replica Sets。MongoDB官方建议每个Shard为一组Replica Sets(结合了Master/Slave模式与自动数据容错、自动恢复的综合体,结构如下图)。
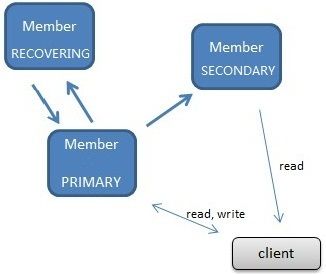
b) 配置服务器(Config Server)。它存储了所有Shard节点的配置信息,每个chunk的Shard key范围,chunk在各Shard的分布情况以及集群中所有DB和collection的Shard配置信息。
c) 路由进程(Route Process)。一个前端路由,客户端由此接入,首先询问配置服务器需要到那个Shard上查询或保存记录,然后连接相应Shard执行操作,最后将结果返回客户端。(类似于网络中路由器的功能)
4、 未分片和分片Client反问mongod 的区别如下图。

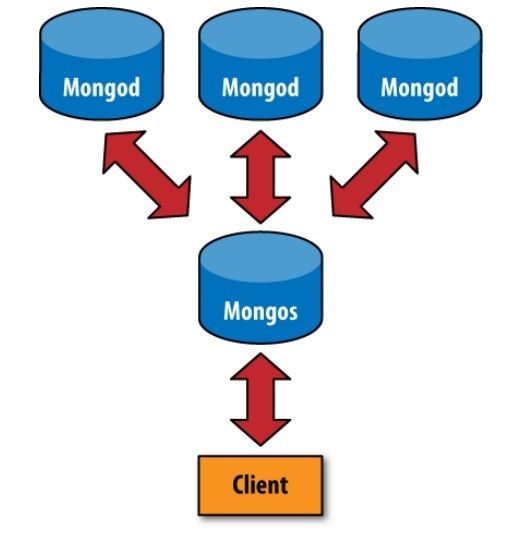
未分片客户端的连接 分片后客户端的连接
5、 Shard Keys
MongoDB主要根据Shard Keys来划分数据,Shard Keys可以由文档的一个或者多个物理键值组成,对于分片Key的选定直接决定了集群中数据分布是否均衡、集群性能是否合理。
配置命令(参考《MongoDB:The Definiive Guide》,以及官网上的《MongoDB Manual》, http://docs.mongodb.org/manual/MongoDB-Manual.pdf)
一. 整体架构
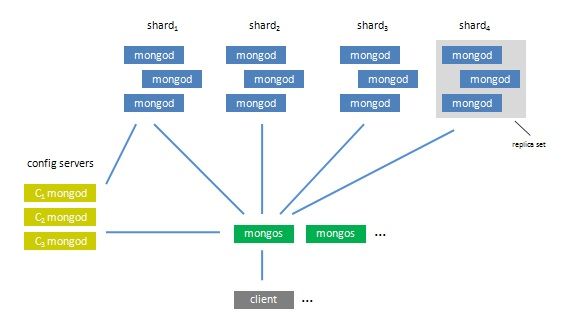
说明:
1. 由于config servers非常重要,建议使用3个config servers,但是可以只是用一个config servers。
2. 一个较好的Auto Sharding解决方案是将每个一shard(分片)定为一个Replica Sets(复制集)。一个Replica Sets由若干个mongod instance组成,在这个集合中,所有的instance的数据相同,这使得即使有某一台机子当掉了,其它机子还是可以正常运行,而且这部分的控制是由Mongo自动完成的,因而尽可能地减少了因当机而产生的错误及人工处理的部分。而Sharding是可以将庞大的数据库拆分为几个部分分别发放到每一个shard,一来降低了单一一台服务器的压力,同时通过减少潜在的损失比例来提高效率。也就是说一个基于Replica Sets的Auto Sharding结构,可以把一个完整而且庞大的数据库根据个人定制,拆分到若干个服务器集合,每个服务器集合中的服务器群又相互保持数据同步,所以除非一个服务器集合中的所有服务器都当掉了,否则某台或几台的当机对数据库的影响是微忽其微的。
3. 一个完整的Auto Sharding功能的实现需要用到mongod和mongos,其中mongos作为真正的应用接口,数据的输入输出都应经过它。然后还需要一个或多个config server(建议是三个),它是mongod,但它不会用来存储应用程序的数据库,通俗的来说而是存放了这整个结构的配置属性,mongos会从config server中读取配置来进行工作。最后是真正会存储数据的mongod们,它们按组分为若干个Replica Sets,用来存放mongos拆分下来的各个sharding。
4. Config服务器存储着集群的metadata信息,包括每个服务器,每个shard的基本信息和chunk(后面介绍)信息Config服务器主要存储的是chunk信息。每一个config服务器都复制了完整的chunk信息。
5. Set up a Sharded Cluster(一开始就允许shard)的步骤。详细命令介绍参考
(http://docs.mongodb.org/manual/administration/sharding/#list-databases-with-sharding-enabled)
a) Create data directories for each of the three config server instances.
b) Start the three config server instances.
c) Start a mongos instance.
d) Connect to one of the mongos instances.
e) Add shards to the cluster.
f) Enable sharding for each database you want to shard.OR Enable sharding on a per-collection basis.
二. Mongos

说明:
1. mongos作为真正的应用接口,数据的输入输出都应经过它。
2. 另外,mongos还有平衡shard的功能(后面介绍);
三. shardKey
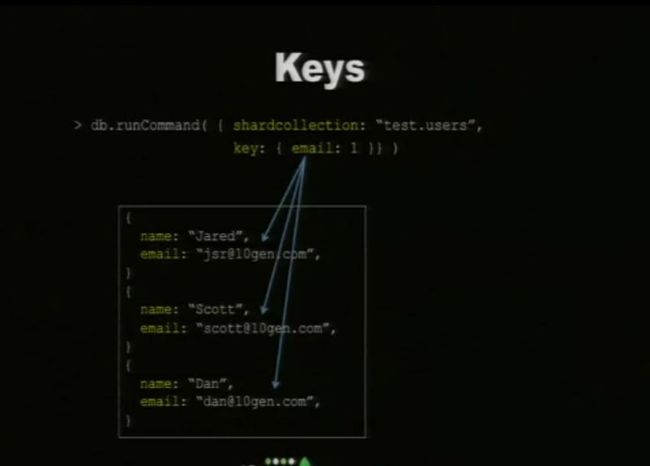
说明:
1. 命令:{ shardCollection: "<db>.<collection>", key: { "<shardkey>": 1 } }
2. MongoDB主要根据Shard Keys来划分数据,Shard Keys可以由文档的一个或者多个物理键值组成,对于分片Key的选定直接决定了集群中数据分布是否均衡、集群性能是否合理。
四. Chunks

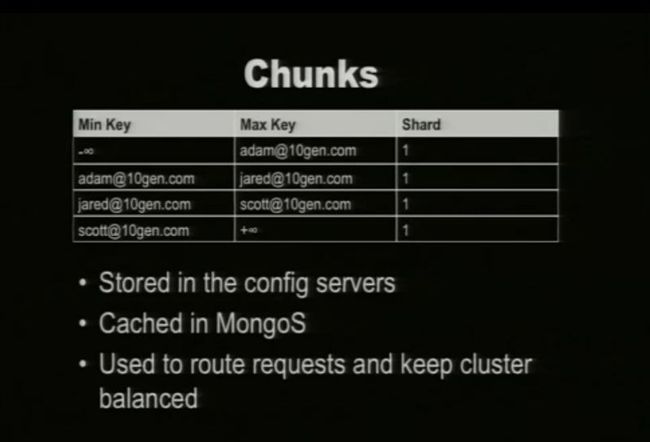
说明:
1. Chunk是一个来自特殊集合中的一个数据范围,(collection,minKey,maxKey)描叙一个chunk,它介于minKey和maxKey范围之间。例如chunks 的maxsize(默认值是64M)大小是100M,如果一个文件达到或超过这个范围时,会被切分到2个新的chunks中。当一个shard的数据过量时,chunks将会被迁移到其他的shards上。同样,chunks也可以迁移到其他的shards上。
2. Chunk包括了Shard Key取值在minKey和maxKey之间一组文档集合,但Chunk并不存放实际数据。整个MongoDB的chunk元信息存放在config数据库的chunks Colecttion中。
3. 当Chunk的大小达到maxsizeMongoDB会根据minKey和maxKey的一个中间值将一个Chunk分裂(Split)为两个Chunk,分裂完毕后,MongoDB会根据各个Shard的负载情况,决定是否将新Chunk移动到其他Shard。
4. 常用命令参考
(http://docs.mongodb.org/manual/administration/sharding/#list-databases-with-sharding-enabled)
五. Balance Shard
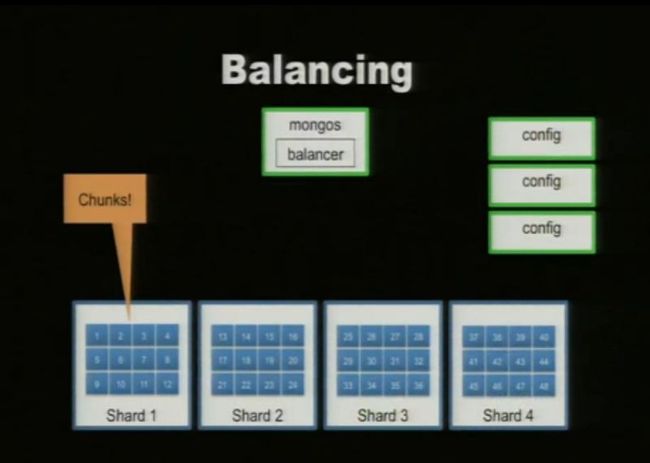
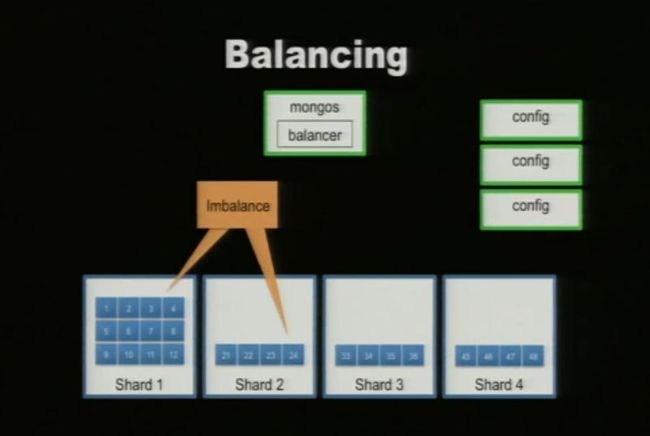
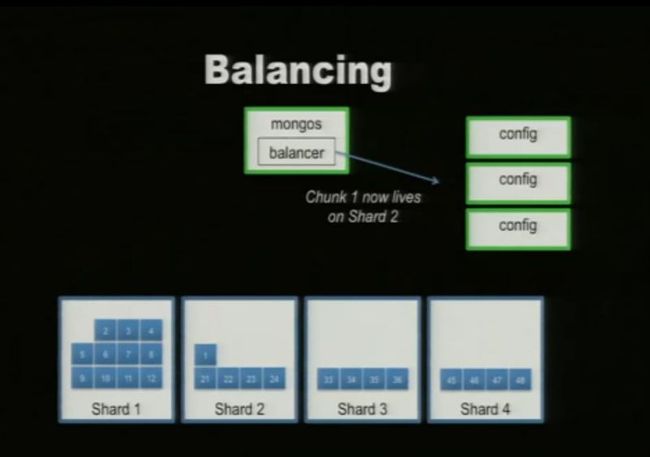
说明:
1. shard don’t a range of chunks but a block of chunks which have a range of data by shardKey.
2. > db.runCommand( { addshard : "10.0.4.85:27020", allowLocal : 1, maxSize:2 , minKey:1, maxKey:10} ) (网上有人测试出shard1中数据超过10M也没有分片,暂时感觉还有些问题,找了很多资料也没有找到)
六. Routed Request

说明:
1. 命令到达mongos,mongos判断出了query指向某个shard,将命令直接指向该shard并得到results并返回给用户。
七. Scatter Gather
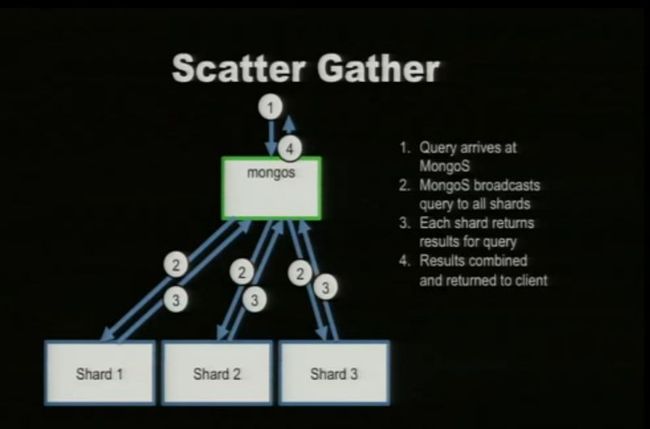
说明:
1. 命令到达mongos,比如说查询所有住在CA的说有用户,mongos判断出需要查询所有的shards,便将这个命令分散传达个每个shard,每个shard都得到相关的结果(并按照默认的shardKey进行排序)返回给mongos,mongos将所有shard返回的结果进行merge(也按照shardKey进行排序)返回给用户。
八. Distributed Merge Sort
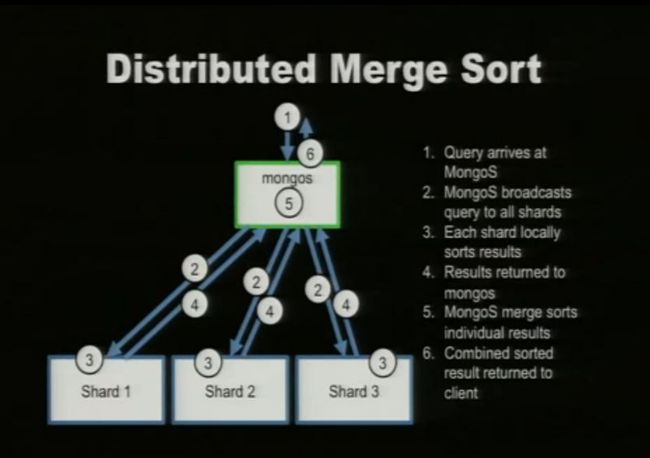
说明:
1. 命令到达mongos,比如说查询所有住在CA的说有用户并按照用户名排序,mongos判断出需要查询所有的shards,便将这个命令分散传达个每个shard,每个shard都得到相关的结果并按照用户名排序返回给mongos,mongos将所有shard返回的结果进行merge(按照用户名排序)返回给用户。
九. 操作命令

说明:
1. 当插入一个document时不含有shardKey的话会出现error。(Insert into it the documents which don’t have shardKey, it doesn‘t work).
十. 查询命令

以上的图片均来源于互联网和视频(http://www.mongodb.org/display/DOCS/Sharding),本人刚刚开始了解MangoDB,有错误的地方希望大家多多指正!