DBaaS与Trove
AWS数据库服务
通过AWS的数据库服务可以快速了解云服务中的DBaaS的轮廓。
Amazon Web Services提供了多种不同数据库服务,如RDS(关系型数据库服务),DynamoDB(键值数据库),Redshift(数据仓库服务)等。其中RDS作为目前数据库主流得到最广泛的关注。
Amazon RDS
Amazon RDS的目标用户是需要关系数据库的完整功能的开发人员或企业,或是希望对使用关系数据库的现有应用程序和工具进行迁移的用户。它能够使客户访问自己的 Amazon RDS数据库实例上运行的 MySQL、Oracle 或 SQL Server 数据库引擎的功能。
Amazon RDS的特点是使用简单,帮助客户处理复杂的数据库任务如备份、复制和扩展等。还能够与其他服务配合使用如EC2在同一个AZ区内减少延迟。通过预配置的 IOPS可以使客户自由选择选择的数据库服务并且能够轻松升级。除此之外,RDS还具备自动软件修补的能力,确保软件升级的性能提升和安全修复能得到利 用。
Amazon DynamoDB
DynamoDB是Amazon的NOSQL数据库服务,是一种快速、全面受管的NoSQL数据库服务,它能让用户以简单并且经济有效地方式存储和检索任何数据量,同时服务于任何程度的请求流量。
DynamoDB所有的数据项都存储在固态驱动器(SSD)中,同时在 3 个可用区域间进行复制,确保达到较高的可用性和持久性。DynamoDB 表没有固定的结构,每一个项目可以拥有不同数量的属性。多种数据类型增加了数据模型的丰富性而本地二级索引可以增加在执行查询时的灵活性,且不会影响性 能。
Trove: OpenStack的DBaaS
Trove是OpenStack实现Database as a Service(DBaaS)的项目,为要能过户提供可扩展和高可靠性的云数据库,并作为一个基本服务可以同时支持关系和非关系型数据库。
Trove在设计之初就计划在OpenStack上运行,目标是能够允许用户快速、简易的使用关系型数据库而不需要处理复杂的 数据库管理任务,用户和数据库管理员都可以管理多个数据库实例。Trove与OpenStack其他项目如Nova、Swift和Cinder交互完全通 过API来实现,因此对Nova等的配置没有任何要求。
Trove目前是一个 OpenStack 孵化器项目,现在致力于提供高性能前提下的资源隔离,并且提供自动化的复杂管理任务包括部署、配置、打补丁、备份、恢复和监控。
Trove 主要组件
Trove分为三个组件: trove-api, trove-taskmanager, trove-guestagent。
* task-api: 主要提供RESTful API并且支持JSON和XML,用来管理和掌控Trove实例。它是一个WSGI组件负责监听服务外部的请求。
* task-taskmanager: 主要完成具体的管理命令,如创建实例,管理实例的生命周期,完成对数据库的操作等等。它主要监听RabbitMQ topic来得到请求。
* task-guestagent: 主要提供具体数据库的运行和管理,并且对数据库本身进行操作。guestagent同样监听RabbitMQ topic来得到请求,并且运行在每一个数据库实例上。每一种数据库都需要一个自己的guestagent实现,目前只有MySQL agent。
Trove 主要逻辑
目前Trove支持用户创建一个数据库服务实例,在实例里可以创建多个数据库并进行管理。数据库服务实例目前通过Nova API来创建,然后同样通过Nova API创建一个Volume(未来通过Cinder API)作为存储,然后在Nova Instance里加载预定义的带有MySQL的Image来启动MySQL。此时用户在得到一个创建好的数据库服务实例以后可以通过API创建数据库并 且指定参数,Trove通过在数据库服务实例里的guest agent来完成相应的命令。下图是Trove处理请求的最主要流程。
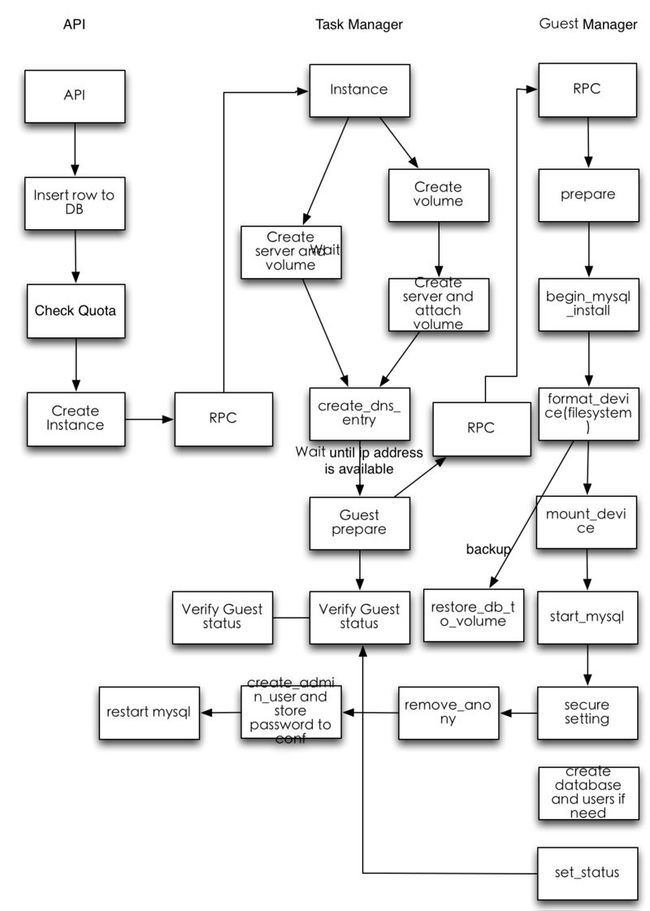
Trove 的进展与未来
Trove是Rackspace开源出来放到OpenStack项目,作为一个孵化器项目,其本身不太成熟并且缺少更多的数据 库类型支持。Trove目前有三个子项目: Trove本身,Trove-Client, Trove-integration(Trove与OpenStack整合的部署项目)。目前MySQL和percona(MySQL的衍生版本)是 Trove支持的数据库类型,不过Redis的支持已经在社区的实现进程之中。Trove本身代码并不是特别复杂,但由于本来是Rackspace内部项 目,在测试代码实现上非常Magic,目前Trove的实际维护者(实际上是后来接手的)也无法完全掌控项目。
Trove在未来进入OpenStack Core项目应该不是特别困难,但根据我对项目本身的理解和代码阅读,在短期内应该无法进入。在OpenStack I版本成为Core Project是一个不小的目标。