Cocos2Dx之渲染流程
渲染时一个游戏引擎最重要的部分。渲染的效率决定了游戏的流畅度清晰度,跟前面的介绍的内容相比,渲染是最具技术含量的事情,也是一个需要很多专业知识的事情。这里我们有这个机会,来学习下一个游戏引擎的渲染是怎么做的。Cocos2Dx是一个2D框架,可以简单地看做z轴在一个平面上,Cocos2Dx采用的OpenGL技术决定了往3D渲染上面走也不是不行的。最新3.2版本已经支持3D骨骼动画的CCSprite。3.2版本还有很多其他的变化,可谓是一次伤筋动骨的大版本,现在还不跳跃,继续基于2.2.3进行分析。
这篇文章先分析简单的CCSprite和CCLayer是怎么渲染出来的,过一下整个渲染的流程。后续我们再分析一些高级功能。
要能够使用OpenGL,肯定第一步是要先初始化OpenGL,并且创建一个可以在上面绘制的场景的窗口。OpenGL本身是跟操作系统,窗口系统无关的图形接口。因此初始化肯定也是平台相关。这就是为什么CCEGLView在每个平台下面都有自己实现的原因。继续使用Windows平台进行分析,其他平台大同小异。
回忆前面讲到游戏启动流程的时候,我们会在AppDelegate::applicationDidFinishLaunching调用pDirector->setOpenGLView(CCEGLView::sharedOpenGLView())来设置OpenGL使用的View。sharedOpenGLView是CCEGLView的一个单例访问接口。CCEGLView::sharedOpenGLView第一次被调用的时候会首先创建一个平台相关的CCEGLView对象,然后调用其Create()函数。
Windows上面的Create函数我们已经看过,它会设置窗口样式,然后创建一个窗口。窗口创建完毕后会调用CCEGLView::initGL。
//file:\cocos2dx\platform\win32\CCEGLView.cpp
bool CCEGLView::initGL()
{
m_hDC = GetDC(m_hWnd);
SetupPixelFormat(m_hDC);
m_hRC = wglCreateContext(m_hDC);
wglMakeCurrent(m_hDC, m_hRC);
const GLubyte* glVersion = glGetString(GL_VERSION);
if ( atof((const char*)glVersion) < 1.5 )
{
return false;
}
GLenum GlewInitResult = glewInit();
if (GLEW_OK != GlewInitResult)
{
return false;
}
if(glew_dynamic_binding() == false)
{
return false;
}
glEnable(GL_VERTEX_PROGRAM_POINT_SIZE);
return true;
}
CCEGLView::initGL首先设置像素格式。像素格式是OpenGL窗口的重要属性,它包括是否使用双缓冲,颜色位数和类型以及深度位数等。像素格式可由Windows系统定义的所谓像素格式描述子结构来定义(PIXELFORMATDESCRIPTOR)。应用程序通过调用ChoosePixelFormat函数来寻找最接近应用程序所设置的象素格式,然后调用SetPixelFormat来设置使用的像素格式。WglCreateContext函数创建一个新的OpenGL渲染描述表,此描述表必须适用于绘制到由m_hDC返回的设备。这个渲染描述表将有和设备上下文(DC)一样的像素格式。wglMakeCurrent将刚刚创建的渲染描述符表设置为当前线程使用的渲染环境。完成这些操作之后,OpenGL的基本环境已经准备好了。后续的处理是为了使用OpenGL扩展。glewInit初始化GLEW。GLEW(OpenGL Extension Wrangler Library)是一个跨平台的C/C++库,用来查询和加载OpenGL扩展。OpenGL并存的版本比较多,有些特性并没有存在于OpenGL核心当中,是以扩展形式存在。作为一个跨平台的游戏框架,处理OpenGL的版本差异是必须要做的。glew_dynamic_binding启用帧缓冲对象(FBO)。
static void SetupPixelFormat(HDC hDC)
{
int pixelFormat;
PIXELFORMATDESCRIPTOR pfd =
{
sizeof(PIXELFORMATDESCRIPTOR), // 大小
1, // 版本
PFD_SUPPORT_OPENGL | // 像素格式必须支持OpenGL
PFD_DRAW_TO_WINDOW | // 渲染到窗口中
PFD_DOUBLEBUFFER, // 支持双缓冲
PFD_TYPE_RGBA, // 申请RGBA颜色格式
32, // 选定的颜色深度
0, 0, 0, 0, 0, 0, // 忽略的色彩位
0, // 无Alpha缓存
0, // 忽略Shift Bit
0, // 无累加缓存
0, 0, 0, 0, // 忽略聚集位
24, // 24位的深度缓存
8, // 蒙版缓存
0, // 无辅助缓存
PFD_MAIN_PLANE, // 主绘图层
0, // 保留
0, 0, 0, // 忽略层遮罩
};
pixelFormat = ChoosePixelFormat(hDC, &pfd);
SetPixelFormat(hDC, pixelFormat, &pfd);
}
从设置的像素格式上可以看出,Windows上启用了双缓冲,使用RGBA颜色,32位颜色深度。
不同平台上面,OpenGL的初始化流程不完全一样。详细的区别可以查看平台相关的CCEGLView类。
OpenGL初始化完成后,就可以进行绘制操作了。CCDisplayLinkDirector::mainLoop会调用drawScene()来绘制场景。drawScene本身做的工作还比较多,比如前面介绍的调度器处理。这里我们抛开渲染无关的内容,只看跟渲染紧密相关的代码实现。
void CCDirector::drawScene(void)
{
//清除颜色缓冲区和深度缓冲去
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
//该节点的转换矩阵入栈
kmGLPushMatrix();
// draw the scene
if (m_pRunningScene)
{
m_pRunningScene->visit();
}
// 该节点的转换矩阵出栈
kmGLPopMatrix();
// 交换缓冲区
if (m_pobOpenGLView)
{
m_pobOpenGLView->swapBuffers();
}
}
一个场景包含当前窗口可以看到的所有内容。由于OpenGL是基于状态的,比如设置的颜色,如果不去清楚或者修改就一直会使用下去。我们当然不希望上一次绘制场景产生的缓冲区数据被绘制到现在的场景当中。所以drawScene()首先清楚颜色缓冲区和深度缓冲区。
关于kmGLPushMatrix和kmGLPopMatrix,有必要先介绍下背景。Cocos2Dx使用了模型视图矩阵、投影矩阵和纹理矩阵。模型视图矩阵完成模型和视图的变换,包括平移、旋转和缩放。投影矩阵完成三维空间的顶点映射到二维的屏幕上,有两种投影:正射投影和透视投影。纹理矩阵用来对纹理进行变换。关于矩阵变换参考注1的资料。
OpenGL通过使用齐次坐标,平移、旋转和缩放变换都可以通过矩阵乘法完成。但是矩阵乘法是有顺序的,左乘和右乘的结果是不一样的,因此应该变换的顺序很重要。由于存在多个矩阵,并且为了简化复杂模型变换,OpenGL使用栈来存放矩阵。kmGLPushMatrix()函数将当前栈的栈顶矩阵复制后压栈,对应的kmGLPopMatrix()用于出栈,还有kmGLLoadIdentity()用于将栈顶矩阵初始化成单位矩阵。需要注意的是,OpenGL使用的矩阵是列优先的矩阵。
kmGLPushMatrix()内部调用lazyInitialize()来延迟初始化Cocos2Dx使用的三类矩阵:模型视图矩阵、投影矩阵和纹理矩阵。初始化的过程中,不但为三个类型的矩阵都创建了一个堆栈(内部通过数组实现的),还在每个堆栈中都压入一个单位矩阵。单位矩阵左乘任何顶点,顶点不会变化。单位矩阵不会影响后续的变换。current_stack表示了当前使用的堆栈,可以通过kmGLMatrixMode(mode)来切换当前使用的矩阵堆栈。
void lazyInitialize()
{
if (!initialized) {
kmMat4 identity;
km_mat4_stack_initialize(&modelview_matrix_stack);
km_mat4_stack_initialize(&projection_matrix_stack);
km_mat4_stack_initialize(&texture_matrix_stack);
current_stack = &modelview_matrix_stack;
initialized = 1;
kmMat4Identity(&identity);
km_mat4_stack_push(&modelview_matrix_stack, &identity);
km_mat4_stack_push(&projection_matrix_stack, &identity);
km_mat4_stack_push(&texture_matrix_stack, &identity);
}
}
CCDirector::drawScene()第一次被调用的时候,会初始化模型视图矩阵、投影矩阵和纹理矩阵分别对应的矩阵栈。然后在每个栈中压入一个单位矩阵。随后kmGLPushMatrix()复制一个模式视图矩阵栈的单位矩阵,然后放到栈顶上。然后渲染当前的场景,最后将栈顶的矩阵出栈。为什么要这样做呢?设想当前的节点需要做一个平移操作,对应的变换矩阵是T1(压栈),假设当前节点的子节点Z序比当前节点大,那么当前节点的所有顶点执行T1p以后,对于它的子节点也需要做平移,使用的同样是变换矩阵T1。这个节点绘制完以后,就该绘制下一个节点了(出栈),下一个节点的变换矩阵为T2(压栈),再用T2做该节点及其子节点的变换。可以看出,这样的处理方式非常自然、简单。
CCScene的visit继承的是CCNode的visit,它的实现我们前面已经分析过了。这里再看看跟渲染相关的内容。CCNode::visit()先复制一个栈顶元素并压栈,然后计算出一个此节点相对于父节点的变换矩阵,然后把它转换为OpenGL格式的矩阵并右乘在当前绘图矩阵之上,从而得到此节点的世界变换矩阵。随后,根据子节点的Z序确定渲染顺序,然后根据渲染顺序依次渲染子节点或自身。如果是渲染自身,直接调用draw函数。CCSprite的draw函数为空,什么都不做。当前节点及其子节点绘制完成之后,再执行出栈操作。
void CCNode::visit()
{
kmGLPushMatrix();
this->transform();
CCNode* pNode = NULL;
unsigned int i = 0;
if(m_pChildren && m_pChildren->count() > 0)
{
sortAllChildren();
// draw children zOrder < 0
ccArray *arrayData = m_pChildren->data;
for( ; i < arrayData->num; i++ )
{
pNode = (CCNode*) arrayData->arr[i];
if ( pNode && pNode->m_nZOrder < 0 )
{
pNode->visit();
}
else
{
break;
}
}
// self draw
this->draw();
for( ; i < arrayData->num; i++ )
{
pNode = (CCNode*) arrayData->arr[i];
if (pNode)
{
pNode->visit();
}
}
}
else
{
this->draw();
}
kmGLPopMatrix();
}
CCNode::visit的核心是transform()。transform()根据当前节点的位置、旋转角度和缩放比例等属性计算出一个此节点相对于父节点的变换矩阵,然后把它转换为OpenGL格式的矩阵并右乘在当前绘图矩阵之上。transform()是负责CCSprite处理的各种变换的核心函数。下一篇文章继续讨论。
现在继续分析渲染的流程。前面提到了,CCScrene的draw()函数不做任何事情。下面我们依次看CCSprite和CCLayer是如何绘制出来的。
void CCSprite::draw(void)
{
CC_PROFILER_START_CATEGORY(kCCProfilerCategorySprite, "CCSprite - draw");
CC_NODE_DRAW_SETUP();
ccGLBlendFunc( m_sBlendFunc.src, m_sBlendFunc.dst );
ccGLBindTexture2D( m_pobTexture->getName() );
ccGLEnableVertexAttribs( kCCVertexAttribFlag_PosColorTex );
long offset = (long)&m_sQuad;
// vertex
int diff = offsetof( ccV3F_C4B_T2F, vertices);
glVertexAttribPointer(kCCVertexAttrib_Position, 3, GL_FLOAT, GL_FALSE, kQuadSize, (void*) (offset + diff));
// texCoods
diff = offsetof( ccV3F_C4B_T2F, texCoords);
glVertexAttribPointer(kCCVertexAttrib_TexCoords, 2, GL_FLOAT, GL_FALSE, kQuadSize, (void*)(offset + diff));
// color
diff = offsetof( ccV3F_C4B_T2F, colors);
glVertexAttribPointer(kCCVertexAttrib_Color, 4, GL_UNSIGNED_BYTE, GL_TRUE, kQuadSize, (void*)(offset + diff));
glDrawArrays(GL_TRIANGLE_STRIP, 0, 4);
CHECK_GL_ERROR_DEBUG();
CC_INCREMENT_GL_DRAWS(1);
CC_PROFILER_STOP_CATEGORY(kCCProfilerCategorySprite, "CCSprite - draw");
}
CCSprite::draw()首先设置使用的OpenGL状态。然后设置混合函数,绑定纹理。随后设置顶点数据,包括顶点坐标、顶点颜色和纹理坐标。因为使用的是顶点数组的方式绘图,所以调用glDrawArrays绘制。GL_TRIANGLE_STRIP参数的意义见注2。代码里面用了很多EMSCRIPTEN宏,他是一个Javscript的LLVM后端处理库,应该是跟JS相关的支持代码。
CC_NODE_DRAW_SETUP设置绘图环境。实际上设置了OpenGL服务器端的状态和着色器。OpenGL是C/S架构,因此客户端和服务器端都有状态需要维护。ccGLEnable在当前版本上什么都没有做,使用服务器端默认状态。着色器的设置,首先选择当前顶点或片段使用的着色器,然后检查同一着色器使用的Uniform数据是否有变化,有变化的话,重新设置着色器使用的Uniform数据。关于Uniform,参见注4。
#define CC_NODE_DRAW_SETUP() \
do { \
ccGLEnable(m_eGLServerState); \
{ \
getShaderProgram()->use(); \
getShaderProgram()->setUniformsForBuiltins(); \
} \
} while(0)
混合的设置在渲染的过程中也非常重要。它决定了在视景框内不同深度的模型颜色如何显示出来,透明效果就依靠它实现。渲染的过程是有顺序的,glBlendFunc函数决定后画上去的颜色与已经存在的颜色如何混合到一起。把将要画上去的颜色称为“源颜色”,把原来的颜色称为“目标颜色”。OpenGL 会把源颜色和目标颜色各自取出,并乘以一个系数(源颜色乘以的系数称为“源因子”,目标颜色乘以的系数称为“目标因子”),然后相加,这样就得到了新的颜色。关于OpenGL混合的详细计算模型,参考注5。
CCSprite混合使用的源因子和目标因子,以及使用的着色器在CCSprite::initWithTexture里面指定的。可以看出CCSprite的源因子是GL_ONE(CC_BLEND_SRC),目标因子是GL_ONE_MINUS_SRC_ALPHA(CC_BLEND_DST)。这样的参数组合,表示使用1.0作为源因子,实际上相当于完全的使用了这种源颜色参与混合运算,目标颜色乘以1.0减去源颜色的alpha值。CCSprite使用的着色器是kCCShader_PositionTextureColor。
CCSprite::draw使用glVertexAttribPointer来设置定点数据。它的原型:
void glVertexAttribPointer( GLuint index, GLint size, GLenum type, GLboolean normalized, GLsizei stride,const GLvoid * pointer);
index是要修改的定点属性的索引值。实际上就是指定,现在设置的顶点数据是顶点坐标,还是纹理坐标,还是顶点颜色。
size是顶点数据的大小。
type是顶点数据的类型。CCSprite::draw设置的顶点坐标是3个浮点数表示的;纹理坐标是两个浮点数表示的;颜色是4个无符号数表示的。
normalized是否进行归一化。颜色需要归一化操作,也就是讲[0-255]整数的颜色,归一化为[0-1]浮点数的颜色。
stride是设置同一类型的数据之间的间隔。这个标志可以让我们把颜色数据、顶点坐标数据和纹理坐标数据放到一个数组里面。
pointer指向数据地址。
CCSprite使用了一个四元组ccV3F_C4B_T2F_Quad来存放四个顶点ccV3F_C4B_T2F,ccV3F_C4B_T2F包含了顶点的坐标、颜色和纹理坐标。因此对于顶点坐标数据,第一个坐标与第二个坐标之间,还有一个大小为ccV3F_C4B_T2F的数据间隔。这就是为什么glVertexAttribPointer的stride参数设置kQuadSize。纹理坐标和颜色放在顶点坐标之后,在通过glVertexAttribPointer设置它们的时候需要计算偏移,offsetof就是完成这个计算的。
typedef struct _ccV3F_C4B_T2F_Quad
{
ccV3F_C4B_T2F tl; //! top left
ccV3F_C4B_T2F bl; //! bottom left
ccV3F_C4B_T2F tr; //! top right
ccV3F_C4B_T2F br; //! bottom right
} ccV3F_C4B_T2F_Quad;
typedef struct _ccV3F_C4B_T2F
{
ccVertex3F vertices; //! vertices (3F)
ccColor4B colors; //! colors (4B)
ccTex2F texCoords; // tex coords (2F)
} ccV3F_C4B_T2F;
由于CCSprite继承了CCNodeRGBA,它可以设置绘制使用的颜色和不透明度。默认颜色是黑色(255, 255, 255, 255)。
CCLayer并没有draw()的缺省实现,使用的是它继承的CCNode的draw()函数,什么都不做。但它的子类CCLayerColor可以自己绘制出来,它继承了CCLayerRGBA和CCBlendProtocol(CCSprite通过CCTextureProtocol间接继承CCBlendProtocol)。我们看看CCLayerColor是如何绘制自身的。
void CCLayerColor::draw()
{
CC_NODE_DRAW_SETUP();
ccGLEnableVertexAttribs( kCCVertexAttribFlag_Position | kCCVertexAttribFlag_Color );
// vertex
glVertexAttribPointer(kCCVertexAttrib_Position, 2, GL_FLOAT, GL_FALSE, 0, m_pSquareVertices);
// color
glVertexAttribPointer(kCCVertexAttrib_Color, 4, GL_FLOAT, GL_FALSE, 0, m_pSquareColors);
ccGLBlendFunc( m_tBlendFunc.src, m_tBlendFunc.dst );
glDrawArrays(GL_TRIANGLE_STRIP, 0, 4);
CC_INCREMENT_GL_DRAWS(1);
}
绘制的步骤与CCSprite类似。只是顶点没有开启纹理坐标,CCLayerColor只是显示设置的颜色,并不支持纹理贴图。因此,glVertexAttribPointer设置顶点数据的时候,没有绑定和设置纹理坐标。
CCLayerColor::initWithColor里面设置了CCLayerColor混合方式和着色器。混合使用的源因子是GL_SRC_ALPHA,目标因子是GL_ONE_MINUS_SRC_ALPHA。这个混合组合是比较常见的组合。表示源颜色乘以自身的alpha值,目标颜色乘以1.0减去源颜色的alpha值。这样一来,源颜色的alpha值越大,则产生的新颜色中源颜色所占比例就越大,而目标颜色所占比例则减小。CCLayerColor使用的着色器是kCCShader_PositionColor。
现在已经看完了怎么渲染出CCSprite和CCLayerColor。自己派生的CCSprite渲染也是一样的方式。游戏退出的时候需要做OpenGL的清理工作。清理工作放在CCEGLView::destroyGL()里面。Windows上面依次调用:
wglMakeCurrent(m_hDC, NULL); wglDeleteContext(m_hRC);
设置设备描述符表使用的图形描述符为空,然后删除图形描述符。
注1:模式视图矩阵和投影矩阵http://www.songho.ca/opengl/gl_transform.html。该网站上还有模拟矩阵变换的小程序,非常直观。
注2:GL_TRIANGLES是以每三个顶点绘制一个三角形。第一个三角形使用顶点v0,v1,v2,第二个使用v3,v4,v5,以此类推。如果顶点的个数n不是3的倍数,那么最后的1个或者2个顶点会被忽略。GL_TRIANGLE_STRIP则稍微有点复杂,其规律是:
构建当前三角形的顶点的连接顺序依赖于要和前面已经出现过的2个顶点组成三角形的当前顶点的序号的奇偶性(如果从0开始):
如果当前顶点是奇数:组成三角形的顶点排列顺序:T = [n-1 n-2 n]。
如果当前顶点是偶数:组成三角形的顶点排列顺序:T = [n-2 n-21 n]。
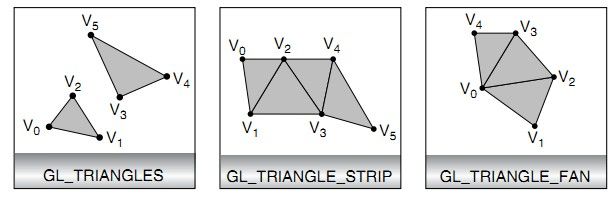
以上图为例,第一个三角形,顶点v2序号是2,是偶数,则顶点排列顺序是v0,v1,v2。第二个三角形,顶点v3序号是3,是奇数,则顶点排列顺序是v2,v1,v3,第三个三角形,顶点v4序号是4,是偶数,则顶点排列顺序是v2,v3,v4,以此类推。这个顺序是为了保证所有的三角形都是按照相同的方向绘制的,使这个三角形串能够正确形成表面的一部分。对于某些操作,维持方向是很重要的,比如剔除。注意:顶点个数n至少要大于3,否则不能绘制任何三角形。GL_TRIANGLE_FAN与GL_TRIANGLE_STRIP类似,不过它的三角形的顶点排列顺序是T = [n-1 n-2 n]。各三角形形成一个扇形序列。
注3:EMSCRIPTEN:Emscripten 是 Mozilla 的 Alon Zakai 开发的一个独特 LLVM 后端,可以将任意 LLVM 中间码编译成 JavaScript,大大简化了现有代码在 Web 时代的重用。Emscripten 并非通常的 LLVM 后端,本身使用 JavaScript 写成。它可以将任何通过 LLVM 前端(比如 C/C++ Clang )生成的 LLVMIR 中间码编译成 JavaScript,从而显著降低移植现有代码库到 Web 环境的损耗。
注4:uniform变量是外部application程序传递给(vertex和fragment)shader的变量。因此它是application通过函数glUniform**()函数赋值的。在(vertex和fragment)shader程序内部,uniform变量就像是C语言里面的常量(const ),它不能被shader程序修改。(shader只能用,不能改)。如果uniform变量在vertex和fragment两者之间声明方式完全一样,则它可以在vertex和fragment共享使用。(相当于一个被vertex和fragment shader共享的全局变量)。uniform变量一般用来表示:变换矩阵,材质,光照参数和颜色等信息。
注5:OpenGL可以设置混合运算方式,包括加、减、取两者中较大的、取两者中较小的、逻辑运算等。下面用数学公式来表达一下这个运算方式。假设源颜色的四个分量(指红色,绿色,蓝色,alpha值)是(Rs, Gs, Bs, As),目标颜色的四个分量是(Rd, Gd, Bd, Ad),又设源因子为(Sr, Sg, Sb, Sa),目标因子为(Dr, Dg, Db, Da)。则混合产生的新颜色可以表示为:(Rs*Sr+Rd*Dr, Gs*Sg+Gd*Dg, Bs*Sb+Bd*Db, As*Sa+Ad*Da)。源因子和目标因子是可以通过glBlendFunc函数来进行设置的。glBlendFunc有两个参数,前者表示源因子,后者表示目标因子。这两个参数可以是多种值,下面介绍比较常用的几种。
GL_ZERO: 表示使用0.0作为因子,实际上相当于不使用这种颜色参与混合运算。
GL_ONE: 表示使用1.0作为因子,实际上相当于完全的使用了这种颜色参与混合运算。
GL_SRC_ALPHA:表示使用源颜色的alpha值来作为因子。
GL_DST_ALPHA:表示使用目标颜色的alpha值来作为因子。
GL_ONE_MINUS_SRC_ALPHA:表示用1.0减去源颜色的alpha值来作为因子。
GL_ONE_MINUS_DST_ALPHA:表示用1.0减去目标颜色的alpha值来作为因子。