操作XML(RSS)
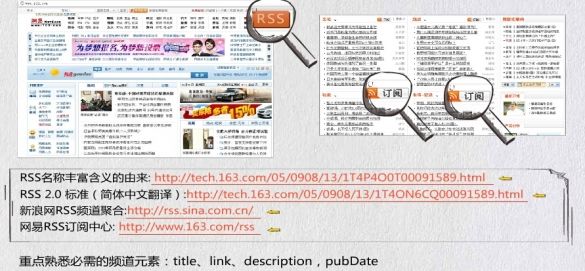
1、RSS相关内容
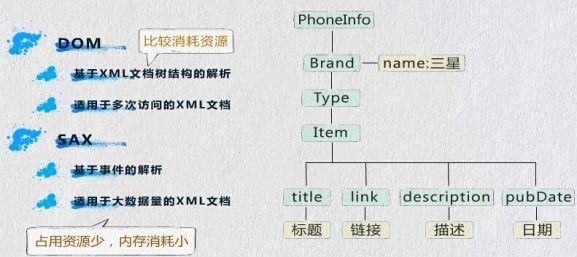
2、解析XML技术
3、读取XML的步骤

4、Document接口
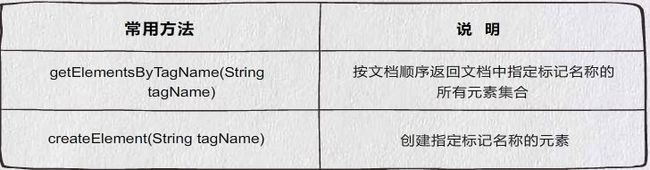
5、Node&Element

6、查询事例
<?xml version="1.0" encoding="UTF-8"?> <PhoneInfo> <Brand name="华为"> <Type name="U8650"/> </Brand> <Brand name="苹果"> <Type name="iphone4"/> <Type name="iphone5"/> </Brand> </PhoneInfo>
package com.ljb.app.xml;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/**
* 用DOM解析XML(查询、增加、删除、修改)
* @author LJB
* @version 2015年3月23日
*/
public class DomParseXml {
/**
* @param args
*/
public static void main(String[] args) {
find();
}
/**
* 查询方法
*/
public static void find () {
try{
// 创建解析器工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// 从DOM工厂获得解析器
DocumentBuilder db = dbf.newDocumentBuilder();
// 获取DOM树
Document doc = db.parse("src/main/java/phone.xml");
// 得到<Brand>节点信息
NodeList brandList = doc.getElementsByTagName("Brand");
// 循环Brand信息
for (int i = 0 ; i < brandList.getLength() ; i++) {
Node brandNode = brandList.item(i);
Element brandElement = (Element)brandNode;
String brandName = brandElement.getAttribute("name");
NodeList typeList = brandElement.getElementsByTagName("Type");
for (int j = 0 ; j < typeList.getLength() ; j++) {
Node typeNode = typeList.item(j);
Element typeElement = (Element)typeNode;
String typeName = typeElement.getAttribute("name");
System.out.println("手机: " + brandName + typeName);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
执行结果:
手机: 华为U8650
手机: 苹果iphone4
手机: 苹果iphone5
7、获取文本节点
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE book SYSTEM "test.dtd"> <!-- country 中国 count 印度 rights 版权所有 pricenotation $ type 支票或现金 默认为现金 --> <book> <details> <name>xml 使用详解</name> <author>成龙来自&country;</author> <publication>Mac &rights;</publication> <price type="支票">&pricenotation;50</price> </details> <details> <name>xml 揭秘</name> <author>Raghu 来自&count;</author> <publication>Mac &rights;</publication> <price>&pricenotation;45</price> </details> </book>
<!ELEMENT book (details+)> <!ELEMENT details (name,author,publication,price)> <!ELEMENT name (#PCDATA)> <!ELEMENT author (#PCDATA)> <!ELEMENT publication (#PCDATA)> <!ELEMENT price (#PCDATA)> <!ATTLIST price type (支票|现金) "现金" > <!ENTITY country "中国"> <!ENTITY count "印度"> <!ENTITY rights "版权所有"> <!ENTITY pricenotation "$">
package com.ljb.app.xml;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/**
* 用DOM解析XML(查询、增加、删除、修改)
* @author LJB
* @version 2015年3月23日
*/
public class DomParseXml {
/**
* @param args
*/
public static void main(String[] args) {
getTextNode();
}
/**
* 获取DOM树
*/
public static Document getDom () {
try {
// 创建解析器工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// 从DOM工厂获得解析器
DocumentBuilder db = dbf.newDocumentBuilder();
// 获取DOM树
Document doc = db.parse("src/main/java/third.xml");
return doc;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 获取文本节点
*/
public static void getTextNode () {
Node priceNode = getDom().getElementsByTagName("price").item(0);
Element priceElement = (Element)priceNode;
String price = priceElement.getFirstChild().getNodeValue();
System.out.println("价格:" + price);
}
}
执行结果:
价格:$50
8、根据序号查询
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE book SYSTEM "test.dtd"> <!-- country 中国 count 印度 rights 版权所有 pricenotation $ type 支票或现金 默认为现金 --> <books> <book> <name>xml 使用详解</name> <author>成龙来自&country;</author> <publication>Mac &rights;</publication> <price type="支票">&pricenotation;50</price> </book> <book> <name>xml 揭秘</name> <author>Raghu 来自&count;</author> <publication>Mac &rights;</publication> <price>&pricenotation;45</price> </book> </books>
<!ELEMENT books (book+)> <!ELEMENT book (name,author,publication,price)> <!ELEMENT name (#PCDATA)> <!ELEMENT author (#PCDATA)> <!ELEMENT publication (#PCDATA)> <!ELEMENT price (#PCDATA)> <!ATTLIST price type (支票|现金) "现金" > <!ENTITY country "中国"> <!ENTITY count "印度"> <!ENTITY rights "版权所有"> <!ENTITY pricenotation "$">
package com.ljb.app.xml;
import java.util.ArrayList;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/**
* 用DOM解析XML(查询、增加、删除、修改)
* @author LJB
* @version 2015年3月23日
*/
public class DomParseXml {
/**
* @param args
*/
public static void main(String[] args) {
getBookByNum(2);
}
/**
* 获取DOM树
*/
public static Document getDom () {
try {
// 创建解析器工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// 从DOM工厂获得解析器
DocumentBuilder db = dbf.newDocumentBuilder();
// 获取DOM树
Document doc = db.parse("src/main/java/third.xml");
return doc;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 获取list列表
* @return
*/
public static ArrayList<Book> getBookList () {
NodeList bookNodeList = getDom().getElementsByTagName("book");
ArrayList<Book> bookList = new ArrayList<Book>();
for (int i = 0 ; i < bookNodeList.getLength() ; i++) {
Book book = new Book();
Node bookNode = bookNodeList.item(i);
Element bookElement = (Element)bookNode;
String name = bookElement.getElementsByTagName("name").item(0).getFirstChild().getNodeValue();
String author = bookElement.getElementsByTagName("author").item(0).getFirstChild().getNodeValue();
String publication = bookElement.getElementsByTagName("publication").item(0).getFirstChild().getNodeValue();
String price = bookElement.getElementsByTagName("price").item(0).getFirstChild().getNodeValue();
book.setName(name);
book.setAuthor(author);
book.setPublication(publication);
book.setPrice(price);
bookList.add(book);
}
return bookList;
}
/**
* 根据序号查询书籍
* @param num
*/
public static void getBookByNum (int num) {
ArrayList<Book> bookList = getBookList();
Book book = bookList.get(num-1);
System.out.println(num + "\t" + book.getName() + "\t"
+ book.getAuthor() + "\t" + book.getPublication()
+ "\t" + book.getPrice());
}
}
package com.ljb.app.xml;
/**
* 创建book对象
* @author LJB
* @version 2015年3月23日
*/
public class Book {
private String name;
private String author;
private String publication;
private String price;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getPublication() {
return publication;
}
public void setPublication(String publication) {
this.publication = publication;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
}
执行结果:
2 xml 揭秘 Raghu 来自印度 Mac 版权所有 $45
9、添加节点
package com.ljb.app.xml;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.util.ArrayList;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.CDATASection;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/**
* 用DOM解析XML(查询、增加、删除、修改)
* @author LJB
* @version 2015年3月23日
*/
public class DomParseXml {
/**
* @param args
*/
public static void main(String[] args) {
// find();
// getTextNode();
// getBookByNum(9);
try {
saveNode();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 获取DOM树
*/
public static Document getDom () {
try {
// 创建解析器工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// 从DOM工厂获得解析器
DocumentBuilder db = dbf.newDocumentBuilder();
// 获取DOM树
Document doc = db.parse("src/main/java/third.xml");
return doc;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 添加节点
* @throws FileNotFoundException
* @throws TransformerException
*/
public static void saveNode () throws FileNotFoundException, TransformerException {
Document doc = getDom();
// 创建book元素
Element bookElement = doc.createElement("book");
// 创建name元素
Element nameElement = doc.createElement("name");
Node nameNode = doc.createTextNode("java");
nameElement.appendChild(nameNode);
// 创建author元素
Element authorElement = doc.createElement("author");
Node authorNode = doc.createTextNode("author来自中国");
authorElement.appendChild(authorNode);
// 创建publication元素
Element publicationElement = doc.createElement("publication");
Node publicationNode = doc.createTextNode("java版权所有");
publicationElement.appendChild(publicationNode);
// 创建price元素
Element priceElement = doc.createElement("price");
// CDATASection cdata = doc.createCDATASection("$90");
Node priceNode = doc.createTextNode("$90");
priceElement.appendChild(priceNode);
// 添加父子关系
bookElement.appendChild(nameElement);
bookElement.appendChild(authorElement);
bookElement.appendChild(publicationElement);
bookElement.appendChild(priceElement);
Element root = (Element)doc.getElementsByTagName("books").item(0);
root.appendChild(bookElement);
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
// 缩进
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
transformer.setOutputProperty("{http://xml.apache.org/xslt}indent-amount", "2");
DOMSource domSource = new DOMSource(doc);
StreamResult result = new StreamResult(new FileOutputStream("src/main/java/third.xml"));
transformer.transform(domSource, result);
}
}
运行结果:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <!-- country 中国 count 印度 rights 版权所有 pricenotation $ type 支票或现金 默认为现金 --> <books> <book> <name>xml 使用详解</name> <author>成龙来自中国</author> <publication>Mac 版权所有</publication> <price type="支票">$50</price> </book> <book> <name>xml 揭秘</name> <author>Raghu 来自印度</author> <publication>Mac 版权所有</publication> <price type="现金">$45</price> </book> <book> <name>java</name> <author>author来自中国</author> <publication>java版权所有</publication> <price>$90</price> </book> </books>
10、修改dom(根据序号修改书名)
package com.ljb.app.xml;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.util.ArrayList;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.CDATASection;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/**
* 用DOM解析XML(查询、增加、删除、修改)
* @author LJB
* @version 2015年3月23日
*/
public class DomParseXml {
/**
* @param args
*/
public static void main(String[] args) {
try {
modify(2);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 获取DOM树
*/
public static Document getDom () {
try {
// 创建解析器工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// 从DOM工厂获得解析器
DocumentBuilder db = dbf.newDocumentBuilder();
// 获取DOM树
Document doc = db.parse("src/main/java/third.xml");
return doc;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 根据序号修改书名
* @throws FileNotFoundException
* @throws TransformerException
*/
public static void modify (int num) throws FileNotFoundException, TransformerException {
Document doc = getDom();
NodeList nameNodeList = doc.getElementsByTagName("name");
Node nameNode = nameNodeList.item(num-1);
Element nameElement = (Element)nameNode;
nameElement.getFirstChild().setNodeValue("修改后的书名");
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
DOMSource domSource = new DOMSource(doc);
StreamResult result = new StreamResult(new FileOutputStream("src/main/java/third.xml"));
transformer.transform(domSource, result);
}
}
执行结果;
<?xml version="1.0" encoding="UTF-8" standalone="no"?><!-- country 中国 count 印度 rights 版权所有 pricenotation $ type 支票或现金 默认为现金 --><books> <book> <name>xml 使用详解</name> <author>成龙来自中国</author> <publication>Mac 版权所有</publication> <price type="支票">$50</price> </book> <book> <name>修改后的书名</name> <author>Raghu 来自印度</author> <publication>Mac 版权所有</publication> <price type="现金">$45</price> </book> <book> <name>java</name> <author>author来自中国</author> <publication>java版权所有</publication> <price>$90</price> </book> </books>
11、删除节点(根据序号删除书节点)
package com.ljb.app.xml;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.util.ArrayList;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.CDATASection;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/**
* 用DOM解析XML(查询、增加、删除、修改)
* @author LJB
* @version 2015年3月23日
*/
public class DomParseXml {
/**
* @param args
*/
public static void main(String[] args) {
try {
delete(3);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 获取DOM树
*/
public static Document getDom () {
try {
// 创建解析器工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// 从DOM工厂获得解析器
DocumentBuilder db = dbf.newDocumentBuilder();
// 获取DOM树
Document doc = db.parse("src/main/java/third.xml");
return doc;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 删除节点
* @param num
* @throws FileNotFoundException
* @throws TransformerException
*/
public static void delete (int num) throws FileNotFoundException, TransformerException {
Document doc = getDom();
NodeList bookNodeList = doc.getElementsByTagName("book");
Node bookNode = bookNodeList.item(num-1);
Element bookElement = (Element)bookNode;
bookElement.getParentNode().removeChild(bookElement);
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
DOMSource domSource = new DOMSource(doc);
StreamResult result = new StreamResult(new FileOutputStream("src/main/java/third.xml"));
transformer.transform(domSource, result);
}
}