自旋锁学习系列(4):基于数组的队列锁
BackoffLock的缺点
上篇我们用指数后退技术实现了BackoffLock,但是还是不太理想。除了移植性不太好外问题还体现在两个方面:
1、 cache 一致性流量: 不要被这个名词吓到了。其实很好理解,因为我们之前定义的所有锁都共用一个状态变量state,所有的线程都是通过判读和操作同一个变量达到加锁和解锁目的。每当一个线程成功获取锁/释放锁,都会改变状态位的值,同时会使所有其他线程的缓存失效。虽然我们采用指数后退技术,但是还是会产生这种问题,因为总会有多个线程同时去争锁。缓存失效,线程就会去内存中获取值,从而占用总线流量资源。
2、临界区利用率低:什么是临界区?就是被锁保护的地方,也就是同时只允许唯一一个线程进来的地方。因为我们采取指数后退技术时,线程获取不到锁后会睡眠一定时间。很可能就在线程睡眠过程中,获取锁的线程刚好释放锁。导致白白浪费了一些时间。
针对上面这两个问题,队列锁就应用而生了。
首先看一下如何去解决cache一致性问题。产生该问题的原因我们上面说过:所有的线程同时操作同一个状态变量,也就是大家都在同一块存储单元上自旋。那么如果我们让线程在不同的存储单元旋转呢?这样的话,线程操作自己的状态变量时,其他线程的状态变量也不会被置成无效状态了。一致性问题也就不复存在了。解决临界区利用率问题只要保证线程不在所空闲时睡眠就行啦。
队列锁的思想:
将线程组成一个队列。在队列中每个线程检测其前驱线程是否完成(指成功获得锁后并解锁)来判断是不是轮到自己。因为每个线程都是在检测其自己的前驱,这样就把线程旋转的存储单元给分开了。当一个获取锁的线程解锁后直接通知它自己的后继线程(如果有的话),这样也就避免了临界区利用率低的问题了。
基于数组的锁
基于数组的锁是队列锁中最好理解的一种,先看代码:
/**
*
* 基于数组的队列锁
*
*/
public class ALock {
// 线程本地变量,保存当前线程在队列中的索引值
ThreadLocal<Integer> mySlotIndex = new ThreadLocal<Integer>() {
@Override
protected Integer initialValue() {
return 0;
}
};
// 队列尾部
AtomicInteger tail;
// 保存着所有线程的状态
boolean[] flag;
// 队列长度,也是容纳线程的最大数量
int size;
public ALock(int capicity) {
size = capicity;
tail = new AtomicInteger(0);
flag = new boolean[size];
flag[0] = true;
}
/**
* 加锁操作
*/
public void lock() {
// 获取当前队列的尾部索引值,tail加一
int slot = tail.getAndIncrement() % size;
// 将当前线程本地变量设置为尾部索引值。也就是将当前线程入队列
mySlotIndex.set(slot);
// 判断自己的状态值,如果状态值为true,成功获取锁。否则自旋
while (!flag[slot]) {
}
}
/**
* 解锁操作
*/
public void unlock() {
// 获取当前线程的索引值
int slot = mySlotIndex.get();
// 设置该索引处状态为false
flag[slot] = false;
// 通知后继线程
flag[(slot + 1) % size] = true;
}
}
这里比较关键的地方有两个,本地线程变量mySlotIndex和数组flag。本地线程变量对于每一个线程来说都有自己的一份拷贝,各个线程之间互不影响,mySlotIndex保存的是线程在当前加锁过程中在队列中的索引。注意,线程第一次完成加锁(获得锁并释放)和第二次去获得锁在队列中的位置不一定是一样的,队列此时的尾部位置就是请求线程将要在队列中的位置。第二个需要注意的是,我们这个队列是一个环状队列。就是说队列大小达到数组最大值后,队列尾部又会重新指向数组的第一个元素。因为这个原因,线程的总数量决不能超过数组的大小,这也是基于数组的队列锁一个限制的地方。
我们举个例子配上图片,一看就明白了。加入我们建立一个容量为3的一个队列锁。
//容量为4 Alock lock = new Alock(4);初始状态如图所示:此时没有线程去尝试获取锁。

线程1尝试去加锁:
//thread-1中执行 lock.lock();因为只有一个线程加锁,所以肯定成功获取:
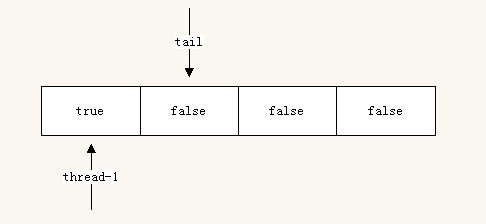
现在另一个线程thread-2尝试获取锁,此时thread -1没有释放锁:
//thread-2中执行 lock.lock();
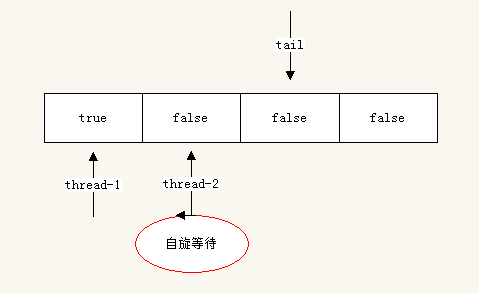
因为thread-1没有是放锁,所以thread-2在flag[1]处自旋等待。
线程thread-3开始请求锁,此时thread-1依然没有是放锁:
//thread-3中执行 lock.lock();
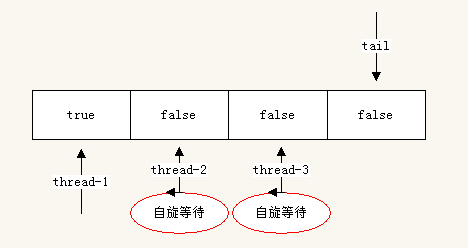
线程thread-4开始请求锁,thread-1没有释放锁:
//thread-4中执行 lock.lock();

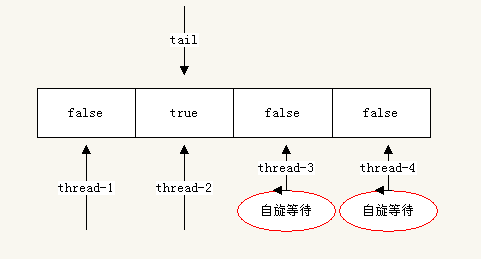
现在有同时3个线程thread-2 ,thread-3,thread-4在同时自旋等待锁。它们三个分别在不同的存储空间内自旋。此时tail已经回到了数组的0索引处。此时无法继续加入线程请求锁了。否则会覆盖第一个线程的状态。所以,对于ALock来说,数组的长度决定了支持请求锁的线程数量。
此时thread-1执行解锁
//thread-1中执行 lock.unlock();
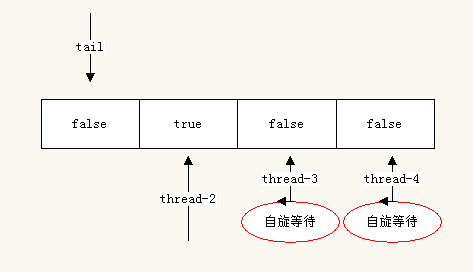
解锁的时候会发生下面几个事情,首先thread-1会设置flag[0]为false,会设置后继节点flag[1](thread-2指向的flag索引)为true。此时thread-2之前缓存保存的flag被置为了无效,thread-2将会从内存中重新读取flag为true,然后thread-2成功的获取了锁。注意:此时flag[1]的重新设置对thread-3和thread-4没有任何影响,因为它们实在flag[2]和flag[3]上自旋等待。这也就解决了缓存一致性流量问题。
加入此时thread-1再来请求加锁呢?
//thread-1中执行 lock.lock();
so easy ! 对照图再去看ALock的实现应该没有什么难理解的地方了。