PreparedStatement executeBatch 插入数据未必高效
前言
对于大数量插入我们经常会想到使用JDBC批量插入,同时还有一种方法采用拼接方式[insert table values(?,?,?),(?,?,?),(?,?,?)]插入效率更高。以下是我做的一个实验,分别采用两种方式插入35W条数数据所消耗时间。欢迎拍砖.
1.1改写前(JDBC批量插入案例)
//STEP 3: 转存数据
try {
Connection conn = getConnection(TO_DRIVER,TO_URL,TO_USERNAME,TO_PASSWORD);
conn.setAutoCommit(false);
String sql = "insert into mc_stat_trends(clock,itemid,itemname,ip,num,value_min, value_avg, value_max) values(?,?,?,?,?,?,?,?)";
PreparedStatement prst = conn.prepareStatement(sql);
for (int i = 0; i < list.size(); i++) {
Map<String, Object> bean = list.get(i);
//System.out.println(bean.toString());
prst.setLong(1, Long.valueOf(bean.get("clock").toString()));
prst.setLong(2, Long.valueOf(bean.get("itemId").toString()));
prst.setString(3, String.valueOf(bean.get("itemName")));
prst.setString(4, String.valueOf(bean.get("ip")));
prst.setLong(5, Long.valueOf(bean.get("num").toString()));
prst.setFloat(6, Float.valueOf(bean.get("value_min").toString()));
prst.setFloat(7, Float.valueOf(bean.get("value_avg").toString()));
prst.setFloat(8, Float.valueOf(bean.get("value_max").toString()));
prst.addBatch();
if(i >0 &&i%1000 == 0){
long startT = System.currentTimeMillis();
prst.executeBatch();
long endT = System.currentTimeMillis();
System.out.println("批量转存数据第["+i+"]条耗时"+(endT-startT)/1000+"S");
}
}
prst.executeBatch();
conn.commit();
conn.close();
prst.close();
} catch (SQLException e) {
e.printStackTrace();
}
1.2 结果输出
1.2.1 计算环境

1.2.3 计算结果
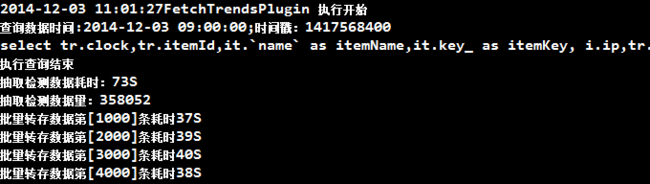
从控制台可以看出:平均每插入1000条消耗时间是:38S左右,如果照此计算:358*38=13604S
2.1改写后(拼接方式插入[insert table values(?,?,?),(?,?,?),(?,?,?)]案例)
//STEP 3: 转存数据
try {
Connection conn = getConnection(TO_DRIVER,TO_URL,TO_USERNAME,TO_PASSWORD);
conn.setAutoCommit(false);
String insertSql = "insert into mc_stat_trends(clock,itemid,itemname,ip,num,value_min,value_avg,value_max) values ";
StringBuffer valBuffer = new StringBuffer();
for (int i = 0; i < list.size(); i++) {
Map<String, String> bean = list.get(i);
valBuffer.append("(");
valBuffer.append(Long.valueOf(bean.get("clock"))+",");
valBuffer.append(Long.valueOf(bean.get("itemId"))+",");
valBuffer.append("'"+String.valueOf(bean.get("itemName"))+"',");
valBuffer.append("'"+String.valueOf(bean.get("ip"))+"',");
valBuffer.append(Long.valueOf(bean.get("num"))+",");
valBuffer.append(bean.get("value_min")+",");
valBuffer.append(bean.get("value_avg")+",");
valBuffer.append(bean.get("value_max"));
valBuffer.append(")");
if((i >0 &&i%200 == 0) || i==list.size()-1){//
//long startT = System.currentTimeMillis();
String sql = valBuffer.insert(0, insertSql).toString();
valBuffer.setLength(0);
//System.out.println(sql);
Statement stat = conn.createStatement();
stat.execute(sql);
//long endT = System.currentTimeMillis();
//System.out.println("批量转存数据第["+i+"]条耗时"+(endT-startT)/1000+"S");
}else{
valBuffer.append(",");
}
}
2.2 结果输出
2.2.1 计算环境
2.2.3 计算结果
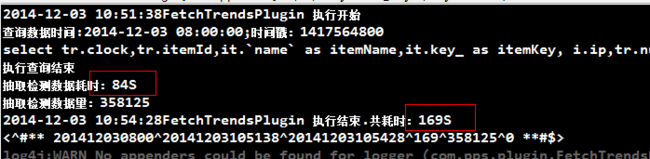
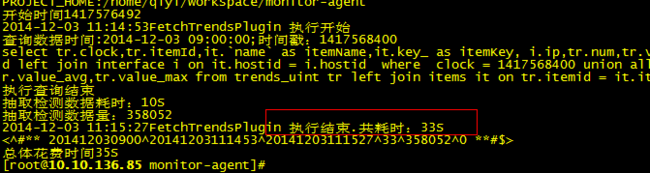
这个计算环境是本地机器()计算出的效果:从控制台可以看出:35W输入插入:需要:85S时间.在生产环境配置下插入效率更高效 如图:消耗时间只有:33-10=13S.
结论
越是封装的代码,它的使用会容易,但效率会降低。