Hadoop CDH4.5 MapReduce MRv1 HA方案实战
上篇实战了HDFS的HA方案,这篇来实战一下MRv1的HA方案,还是基于上篇的环境来实战,原有的HDFS HA环境不做拆除。因为Jobtracker的HA和non-HA架构不能同时存在于一个集群中,所以如果要实施Jobtracker HA,则需要卸载non-HA的Jobtracker的配置。
CDH4.5 Hadoop集群信息如下
192.168.1.10 U-1 Active-NameNode zkfc JobtrackerHA mapreduce-zkfc 192.168.1.20 U-2 DataNode zookeeper journalnode 192.168.1.30 U-3 DataNode zookeeper journalnode 192.168.1.40 U-4 DataNode zookeeper journalnode 192.168.1.50 U-5 DataNode 192.168.1.70 U-7 Standby-NameNode zkfc JobtrackerHA mapreduce-zkfc1 卸载U-1上的non-HA Jobtracker安装包
service hadoop-0.20-mapreduce-tasktracker stop service hadoop-0.20-mapreduce-jobtracker stop apt-get --purge remove hadoop-0.20-mapreduce-jobtracker2 在U-1/7上安装JobtrackerHA包
apt-get install hadoop-0.20-mapreduce-jobtrackerha
3 因为我们要利用zookeeper做自动故障转移,所以需要在U-1/7上安装Jobtracker的zkfc包
apt-get install hadoop-0.20-mapreduce-zkfc
4 配置Jobtracker的HA配置文件(mapred-site.xml)
在集群中的每个JobTracker都有不同的JobTracker ID,用来支持一个配置文件适合所有的JobTracker,所以我们照样选择myjob作为我们的ID。
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>myjob</value>
</property>
<property>
<name>mapred.jobtrackers.myjob</name>
<value>U-1,U-7</value>
</property>
<property>
<name>mapred.jobtracker.rpc-address.myjob.U-1</name>
<value>U-1:8021</value>
</property>
<property>
<name>mapred.jobtracker.rpc-address.myjob.U-7</name>
<value>U-7:8022</value>
</property>
<property>
<name>mapred.job.tracker.http.address.myjob.U-1</name>
<value>U-1:50030</value>
</property>
<property>
<name>mapred.job.tracker.http.address.myjob.U-7</name>
<value>U-7:50031</value>
</property>
<property>
<name>mapred.ha.jobtracker.rpc-address.myjob.U-1</name>
<value>U-1:8023</value>
</property>
<property>
<name>mapred.ha.jobtracker.rpc-address.myjob.U-7</name>
<value>U-7:8024</value>
</property>
<property>
<name>mapred.ha.jobtracker.http-redirect-address.myjob.U-1</name>
<value>U-1:50032</value>
</property>
<property>
<name>mapred.ha.jobtracker.http-redirect-address.myjob.U-7</name>
<value>U-7:50033</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/mapred</value>
</property>
<property>
<name>mapreduce.jobtracker.restart.recover</name>
<value>true</value>
</property>
<property>
<name>mapred.job.tracker.persist.jobstatus.active</name>
<value>true</value>
</property>
<property>
<name>mapred.job.tracker.persist.jobstatus.hours</name>
<value>1</value>
</property>
<property>
<name>mapred.job.tracker.persist.jobstatus.dir</name>
<value>/jobtracker</value>
</property>
<property>
<name>mapred.client.failover.proxy.provider.logicaljt</name>
<value>org.apache.hadoop.mapred.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>mapred.client.failover.max.attempts</name>
<value>15</value>
</property>
<property>
<name>mapred.client.failover.sleep.base.millis</name>
<value>500</value>
</property>
<property>
<name>mapred.client.failover.sleep.max.millis</name>
<value>1500</value>
</property>
<property>
<name>mapred.client.failover.connection.retries</name>
<value>0</value>
</property>
<property>
<name>mapred.client.failover.connection.retries.on.timeouts</name>
<value>0</value>
</property>
<property>
<name>mapred.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/usr/lib/hadoop-0.20-mapreduce/.ssh/id_rsa</value>
</property>
<property>
<name>mapred.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>mapred.ha.zkfc.port</name>
<value>8018</value>
</property>
</configuration>
5 把mapred-site.xml文件拷贝到U-2/3/4/5/7上相同的目录下,不过在CDH4.5中有个坑啊,官方文档中明确的说明mapred.job.tracker的值在HA模式下是一个不能带端口的字符串ID。
In an HA setup, the logical name of the JobTracker active-standby pair. In a non-HA setup mapred.job.tracker is a host:port string specifying the JobTracker's RPC address, but in an HA configuration the logical name must not include a port number.拷贝到U-2/3/4/5之后,TaskTracker直接起不来,日志报如下
2014-05-22 18:56:10,119 ERROR org.apache.hadoop.mapred.TaskTracker: Can not start task tracker because java.lang.IllegalArgumentException: Does not contain a valid host:port authority: myjob
at org.apache.hadoop.net.NetUtils.createSocketAddr(NetUtils.java:210)
at org.apache.hadoop.net.NetUtils.createSocketAddr(NetUtils.java:162)
at org.apache.hadoop.net.NetUtils.createSocketAddr(NetUtils.java:151)
at org.apache.hadoop.mapred.JobTrackerProxies.createProxy(JobTrackerProxies.java:76)
at org.apache.hadoop.mapred.TaskTracker.initialize(TaskTracker.java:1065)
at org.apache.hadoop.mapred.TaskTracker.<init>(TaskTracker.java:1780)
at org.apache.hadoop.mapred.TaskTracker.main(TaskTracker.java:4123)
然后把U-2/3/4/5的配置改成如下
<property> <name>mapred.job.tracker</name> <value>myjob:8021</value> </property>然后TaskTracker是可以启动了,可是到日志里面一看
2014-05-22 18:55:04,114 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: myjob/180.168.41.175:8021. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS) 2014-05-22 18:55:04,119 ERROR org.apache.hadoop.mapred.TaskTracker: Caught exception: java.net.ConnectException: Call From U-4/192.168.1.40 to myjob:8021 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused at sun.reflect.GeneratedConstructorAccessor5.newInstance(Unknown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:782) at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:729) at org.apache.hadoop.ipc.Client.call(Client.java:1242) at org.apache.hadoop.ipc.WritableRpcEngine$Invoker.invoke(WritableRpcEngine.java:225) at org.apache.hadoop.mapred.$Proxy9.getBuildVersion(Unknown Source) at org.apache.hadoop.mapred.TaskTracker.offerService(TaskTracker.java:1958) at org.apache.hadoop.mapred.TaskTracker.run(TaskTracker.java:2875) at org.apache.hadoop.mapred.TaskTracker.main(TaskTracker.java:4125) Caused by: java.net.ConnectException: Connection refused
这各真是坑爹.....
6 重启zookeeper服务(U-2/3/4)
service zookeeper-server restart7 初始化mapreduce-zkfc(U-1)
service hadoop-0.20-mapreduce-zkfc init8 启动mapreduce-zkfc服务(U-1/7)
service hadoop-0.20-mapreduce-zkfc start9 启动mapreduce-jobtrackerha服务
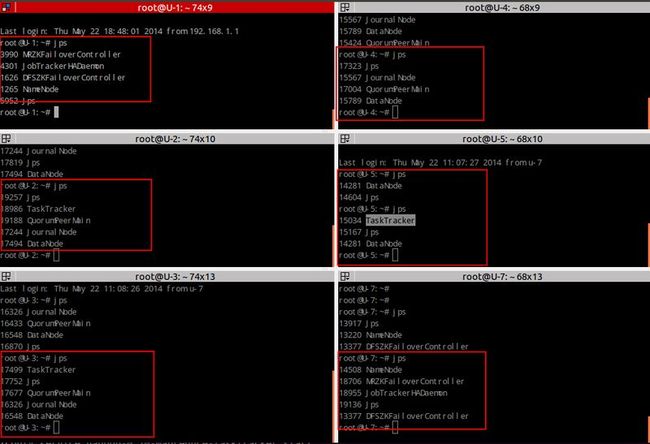
service hadoop-0.20-mapreduce-jobtrackerha start10 我们看看U-1/3/5/7上面跑了哪些相关进程
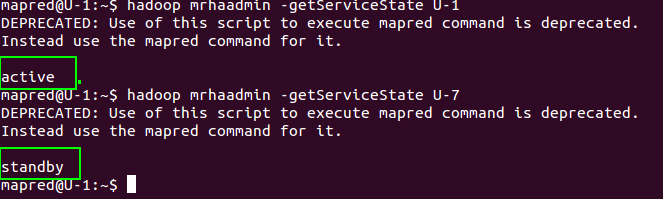
11 查看U-1/7上的JobTracker各处于什么状态
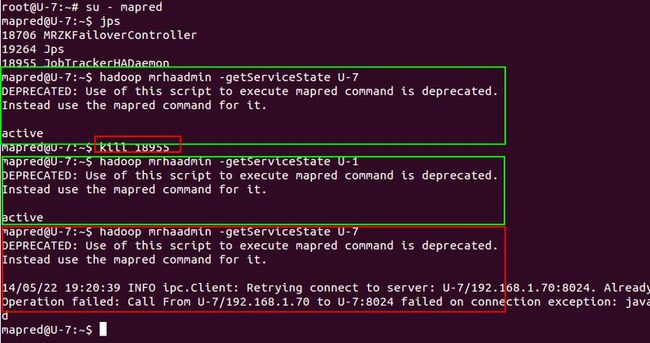
12 我们模拟一次故障转换

13 kill掉U-7上面的JobTrackerHADaemon