web编程隐藏的工作
web编程范围很广,包括后台服务端编程,比如使用jsp,php或asp编写动态网页,主要功能:
- 读取数据库获得数据集并按一定形式渲染成可见性页面
- 保存用户状态的功能(php的session)
- 通过服务端语言的计算结果返回结果(python处理游戏数据)
还有前台编程,对象是用户的客户端(浏览器)编程,主要应用:静态html,动态效果,获取数据和Ajax
原先学习php只是简单地使用语句,变量和数据库操作便可以构建一个简单或复杂的网站系统。如今有了linux及服务器的相关知识,我对web编程的底层工作有了一点理解。
首先说说服务器,一般开发常用的软件是apache。程序员搞开发侧重于php,对apache的配置一般熟悉。但是要成为高手必须要深入了解原理。那时的困惑是:
- 服务器是如何处理请求并生成网页?
- 为什么php有两个cli和cgi的接口
- 了解apache的配置指令的作用
需要的知识:TCP/IP,HTTP协议,socket和cgi相关知识
我先按我的理解来描述服务器处理请求的过程及服务器对动态脚本的响应的过程(应用流程层次)
用户的浏览器相当于一个Socket Client(客户端),用户只需在上面输入网址,就可以获取网页。但是对于浏览器方面做了很多工作,工作大概如下:首先发送DNS请求到DNS服务器查询获取网址(URL)相对应的IP,在庞大的互联网网络中通过ARP协议(网关,子网掩码,MAC等)找到处于子网络中的电脑或者服务器,将经过IP和TCP封装过的数据包(分成几段发送报文)发送到MAC对应的所在服务器,与服务器上的监听其连接的软件(Server)通过三次握手(tree-way handshake)把请求头(Request Header)发送到服务端并且得到服务器的响应(Response)。来自客户端的Request Header格式如下:
GET /index.php?act=get HTTP/1.1 //请求状态行,包括请求方法,url和HTTP协议版本
Host: localhost //请求数据,一般存放来自客户端 的数据和属性,比如浏览器的类型,请求时间戳,请求内容的字符集等,请求目标的HOST等等
Accept-Encoding:xxx
User-agent:xxxxxxxxxxx
//空一行,表示与正文内容的区别
data=%ad%12%20%da&xxxx //POST方法传送的数据存放在这里。用urlencode转换,安全性较弱,建议单向加密。理论上可发送无限长度的数据
服务器上已连接上的socket链接接受到一次发送或多次分段发送的请求头(Request Header)后,把这些连接中传送的字符流缓存到服务器的某个缓存块里,供服务端解析。服务器经过一定工作后返回一定长度的响应头(Response Header)或空发送到客户端。服务端的Response Header格式如下:
HTTP/1.1 200 OK //响应状态行,HTTP协议版本,状态码,和状态码的说明,彼此由空格分隔(200 表示已经完成)
XXXX:XXXXXXXXXXXX //响应头数据,通常返回一些服务端的数据(软件版本和名称),正文本身的属性(比如内容长度,MINE类型和缓存时间(Last-Modified))
Content-Type:text/html;charset=utf-8
Date:Sat, 11 Jan 2003 02:44:04 GMT
//空一行
dataxxxxxxxxxxxxxxxxxxxxx //以\0结尾,表示字符的结束。不带\r\n
附图:(以访问www.jike.com为例)
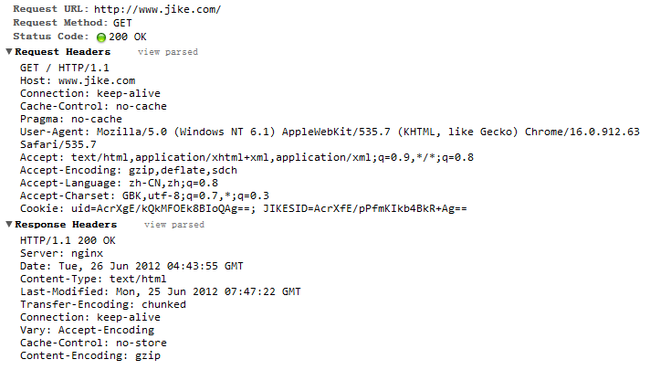
附POST方法请求 图:(本地)
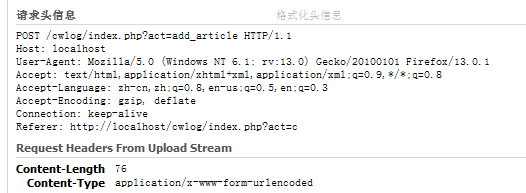

服务端发送这样的response到客户端后,经过四次握手后主动结束了socket连接。服务器断开socket连接后,释放系统资源(子进程,文件描述符)。服务端(server)继续监听其他接口。
服务器动态处理脚本
在服务端的web server软件起着非常重要的作用。我会以apache为例子讲解具体作用。apache启动后在系统生成一个socket并绑定一个端口(web server默认是80,ftp是21),软件随时监听这个端口的动态。来自外部的一个请求通过80端口到达服务器,负责此端口的server开始accept这个请求,生成一个子进程来处理此请求。这个socket算是已经连接了。服务器接受到这个请求随后发来的数据后并缓存到一个内存页中。接下来的server是要解析request header。
请求头的第一行是非常重要的,分为三个部分,第一个是请求方法,一共八种方法。浏览器请求网页的常有GET和POST,访问FTP的主要是PUT和DELETE。第二个是URI。uri是一个请求方法后的数据块,默认是'/',表示web根目录的层次。上面例子相对应的是"/index.html?act=get ",他的作用是请求服务器的哪个资源和通过url传递的数据(php中的全局$_GET的来源)。有了uri就可以决定server读取哪个文件内容返回,假设存放服务端脚本所在的文件夹为www根目录(Document ROOT),默认网页是index.html或default.html。如果uri为空,我就发送index.html(default.html)的内容作为response header的正文。(apache的大部分配置可以配置,灵活性较大)
apache默认存在一个核心模块,即文件映射模块,既uri表现的文件层次可以映射到www根目录的文件层次结构。说到这个不得不吐个槽,php的MVC框架有个路由分派的模块,解析入口文件的pathinfo,这需要在服务器文件搞个htaccess,启动rewrite module,教apache如何正确认识url,说白了就是忽略掉入口文件。很拙劣的模仿哎~~python和ruby自带的server就没有,我更喜欢干净的pathinfo。
如果uri请求的资源文件的后缀名是.php(参考apache的AddType指令),就会调用相对应的语言解释器(参考apache的LoadModule指令)的so文件或dll文件来处理输入(脚本文件里的源代码),并返回输出结果。web server工作过程中,服务端的各种语言解释器(php,python和ruby等)要提供一个cgi来方便web sever的调用,这些相关模块通常在httpd启动后就常驻在内存中,以内存共享形式加载在内存中。如果后缀名是.py,web server则调用python的wsgi来处理文件。
浏览器如何工作?
浏览器收到来自服务器的响应后,由浏览器内部最重要的部分--图形渲染引擎。不同的浏览器用的是不同的引擎,也不难理解为什么浏览器厂商对html标签的解读不同。(http协议标准的实现早期并没有标准化,以造成存在一些浏览器的兼容性)。浏览器根据一行正文字符串(其中包括换行符)通过高效的算法来构建DOM树。DOM总体是一个很大的对象树,每个元素是一个对象,一个标签的属性即转换成相对应的对象属性或方法(方便css和js查找,选择,新增或删除)。浏览器内核采用顺序读取并执行字符串的指令,也就是可以解释为什么js在代码的顺序上的严格性。

下图是ff下firebug的截图,这图反映了dom树对象的all (包括js注册的对象和elements实体)

浏览器在接受服务器的数据后可能解析到css和js,img这一标签块,内核会获取css,img的href属性或js的src属性,再次发送静态资源的请求,请求内容的不同反映在uri上的后缀名上。这也要要求web server具有判断和读取静态资源的功能。对于不同的资源类型,响应头在Content-Type这一节也不同,比如图片的mine是image/png等,而js是text/javascript,css则是text/css。这告诉了浏览器如何去处理静态资源的二进制流,并还原视觉上原来的形式(本质的数据是不变的)。见图
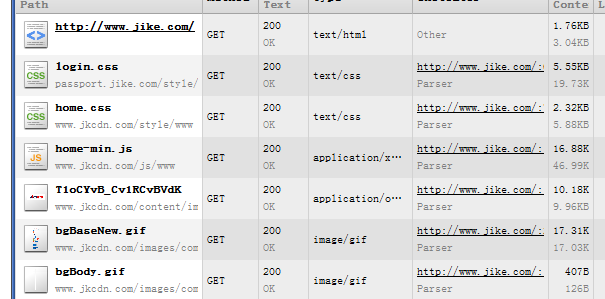
web编程中最重要的软件是浏览器和web 服务软件。由于我们重心放在语言层次上,很少关注平常的工具是如何运作的。这篇文章主要讲了在一般web编程中常用的服务器和浏览器的底层工作相关知识(比较隐蔽),给从事web编程的人扫扫盲。如果你真的能了解这些机理,那么你也许会想到从哪个方面如何去优化这些工作,提高工作效率。你不是低级程序员了~~
个人自吐,如果文中哪些错误被高手所指出,欢迎留言。(ps,感谢ff和chrome两个好基友的倾情表演~~)