lucene学习笔记二(基于数组的lucene检索,索引删除)
构建数组:
private String[] ids = { "1", "2", "3", "4", "5", "6" };
private String[] emails = { "[email protected]", "[email protected]", "[email protected]", "[email protected]", "[email protected]",
"[email protected] " };
private String[] contents = { "welcome to visited the space,i like eat", "hello,my name is scc,i like foot",
"the day is first,i like sing,i like foot", "tommorw,i like dance", "hello world,i like game",
"i like football" };
private Date[] dates = null;
private Map<String, Float> scores = new HashMap<>();// 加权
private int[] attachs = { 2, 3, 1, 4, 5, 6 };
private String[] names = { "张三", "李四", "marry", "jetty", "mick", "divid" };
public void setDates() throws ParseException {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
dates = new Date[] { sdf.parse("2015-04-01"), sdf.parse("2016-04-01"), sdf.parse("2017-04-01"),
sdf.parse("2015-03-01"), sdf.parse("2015-10-01"), sdf.parse("2015-12-01") };
}
创建Directory:
private Directory directory;
public IndexUtil(){
try {
//创建Directory
directory = FSDirectory.open(new File("D:/workspace/lucene/index02").toPath());
scores.put("kkrgwbj.com", 2.0f);
scores.put("bingyang.com", 1.5f);
setDates();
} catch (IOException e) {
e.printStackTrace();
}
}
创建文档,文档添加域:
public void index(){
IndexWriter indexWriter = null;
try {
indexWriter = new IndexWriter(directory, new IndexWriterConfig(new StandardAnalyzer()));
Document doc = null;
for (int i = 0; i < ids.length; i++) {
//创建文档(文档相当于数据库表中的每一条记录)
doc = new Document();
//为文档添加域(域相当于表中的每一个字段)
doc.add(new TextField("id",ids[i],Field.Store.YES));
doc.add(new TextField("email", emails[i],Field.Store.YES));
TextField content = new TextField("content",contents[i],Field.Store.YES);
content.tokenStream(new StandardAnalyzer(),null);
doc.add(content);
doc.add(new TextField("name", names[i],Field.Store.YES));
//存储整形
doc.add(new IntField("attach", attachs[i], Field.Store.YES));
//存储日期
doc.add(new LongField("date", dates[i].getTime(), Field.Store.YES));
//将文档写到索引中
indexWriter.addDocument(doc);
}
} catch (IOException e) {
e.printStackTrace();
}finally{
if(indexWriter!=null){
try {
indexWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
查询索引:
/**
* 查询索引
*/
public void query(){
IndexReader indexReader = null;
try {
indexReader = DirectoryReader.open(directory);
//通过reader可以获取文档的数量
System.out.println("numDosc:"+indexReader.numDocs());
System.out.println("maxDocs:"+indexReader.maxDoc());
} catch (IOException e) {
e.printStackTrace();
}finally{
if(indexReader!=null)
try {
indexReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
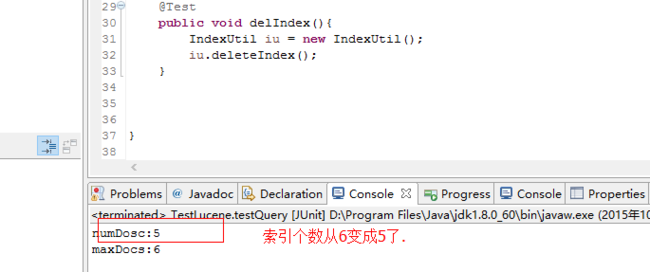
junit测试运行:

索引的删除:
/**
* 删除索引
*/
public void deleteIndex(){
IndexWriter indexWriter = null;
try {
indexWriter = new IndexWriter(directory, new IndexWriterConfig(new StandardAnalyzer()));
//参数是一个选项,可以是一个Query,也可以是一个Term,Term是一个精确查找的值
indexWriter.deleteDocuments(new Term("id","1"));
//强制删除
//indexWriter.forceMergeDeletes();
}catch(Exception e){
e.printStackTrace();
}finally{
if(indexWriter!=null)
try {
indexWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
junit测试:
当执行deleteIndex方法时,再执行查询索引