使用tika解析word,xml,html,pdf生成lucene索引
TIKA是什么?
Apache Tika 利用现有的解析类库,从不同格式的文档中(例如HTML, PDF, Doc),侦测和提取出 元数据和结构化内容。
功能包括:
侦测文档的类型, 字符编码,语言,等其他现有文档的属性。
提取结构化的文字内容。
该项目的目标使用群体主要为搜索引擎以及其他内容索引和分析工具。
上面的这段话,摘自百科,说白了,就是帮助你从文档中解析出来里面的内容而不包括其他属性标签,如从,doc,pdf,html,xml中解析出纯文本内容,而忽略掉html的标签等。
下面我在我的项目中引入tika的jar包。
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>1.11</version>
</dependency>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers</artifactId>
<version>1.11</version>
</dependency>
tika的初体验:
让我们用tika解析doc中的内容:
新建一个IndexUtil工具类,添加一个方法fileToTxt如下:
public String fileToTxt(File file) {
org.apache.tika.parser.Parser parser = new AutoDetectParser();
try {
InputStream inputStream = new FileInputStream(file);
DefaultHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
ParseContext parseContext = new ParseContext();
parseContext.set(Parser.class, parser);
parser.parse(inputStream,handler,metadata,parseContext);
for (String string : metadata.names()) {
System.out.println(string+":"+metadata.get(string));
}
inputStream.close();
return handler.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
@Test
public void test5() {
IndexUtil indexUtil = new IndexUtil();
System.out.println(indexUtil.fileToTxt(new File("E:/lucene/【5】附件五:应聘人员信息登记表(社会).doc")));
}
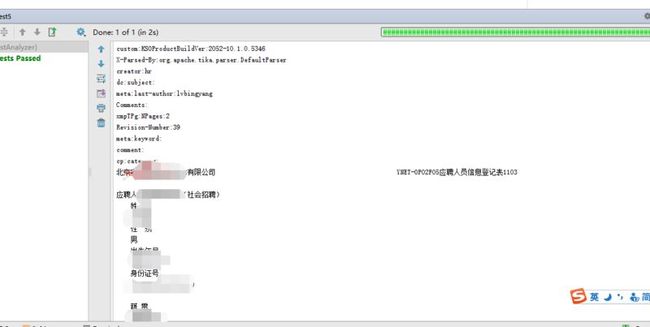
可以看到tika很方便的帮我们将doc文档解析了。tika还提供了一种极其方便的解析方法,下面来看方法二:
我们新建一个方法tickTool,如下所示:
/**
* tika
* @param file
* @return
*/
public String tickTool(File file) {
Tika tika = new Tika();
try {
tika.parse(file);
} catch (IOException e) {
e.printStackTrace();
}
return tika.toString();
}
<dependency>
<groupId>com.chenlb.mmseg4j</groupId>
<artifactId>mmseg4j-core</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>com.chenlb.mmseg4j</groupId>
<artifactId>mmseg4j-analysis</artifactId>
<version>1.9.1</version>
</dependency>
public void index(File file) {
try {
//构建directory,这里将生成的索引存入在E盘lucene_index目录下面
FSDirectory fsDirectory = FSDirectory.open(new File("E:/lucene_index"));
//构建indexwriter
IndexWriter writer = new IndexWriter(fsDirectory, new IndexWriterConfig(Version.LUCENE_45, new MMSegAnalyzer()));
//先删除所有的索引
writer.deleteAll();
//构建doc
org.apache.lucene.document.Document document = new Document();
//doc添加字段
document.add(new TextField("content", (new Tika().parse(file))));
//写入索引
writer.addDocument(document);
//关闭
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
接着写个测试方法进行索引测试:
@Test
public void test4() {
IndexUtil indexUtil = new IndexUtil();
indexUtil.index(new File("E:\\lucene\\index.html"));
}
运行成功后,我们用luke的索引查看工具,查看生成的索引:
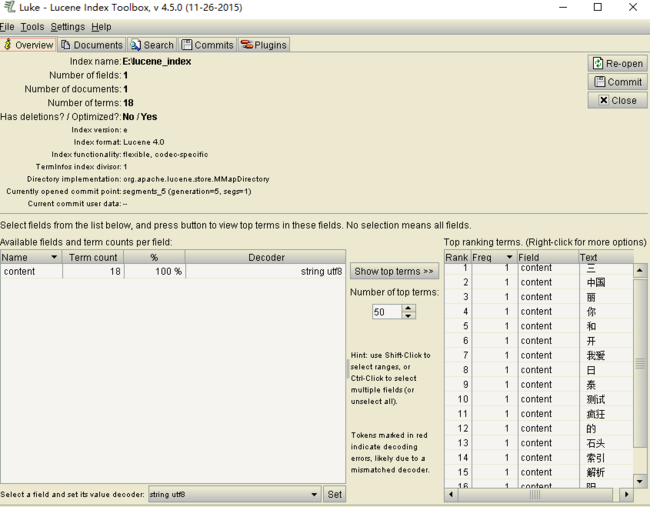
可以看到,我们这里采用tika解析的html生成的索引只包含了html内容而没有标签信息。