MySQL Tips【Updating】
1、MySQL中varchar最大长度问题

问题:为啥大字段可以建,小字段却失败?
单个varchar(20000)用utf8没有超过64K,不会转成text类型,2个呢又超了64K最大单行长度。varchar(30000)用utf8超64K,被转成text类型,所以没事。其实第一个建表语句被 "2 warnings"果断出卖了 ![]()
具体的可以参考这篇:
MySQL中varchar最大长度是多少?
http://dinglin.iteye.com/blog/914276
2、mysql时间相减的问题(bug)
--创建表
mysql> CREATE TABLE mytest (
t1 datetime,
t2 datetime
);
Query OK, 0 rows affected
--插入测试记录
mysql> insert into mytest(t1,t2) values('2013-04-21 16:59:33','2013-04-21 16:59:43');
Query OK, 1 row affected
mysql> insert into mytest(t1,t2) values('2013-04-21 16:59:33','2013-04-21 17:00:33');
Query OK, 1 row affected
mysql> insert into mytest(t1,t2) values('2013-04-21 16:59:33','2013-04-21 17:59:35');
Query OK, 1 row affected
--验证结果
mysql> select t1,t2,t2-t1 from mytest;
+---------------------+---------------------+-------+
| t1 | t2 | t2-t1 |
+---------------------+---------------------+-------+
| 2013-04-21 16:59:33 | 2013-04-21 16:59:43 | 10 |
| 2013-04-21 16:59:33 | 2013-04-21 17:00:33 | 4100 |
| 2013-04-21 16:59:33 | 2013-04-21 17:59:35 | 10002 |
+---------------------+---------------------+-------+
3 rows in set
这个问题2003年就有人在mysql4.0的版本时反馈,但mysql官方并不认为是bug,因为他们认为mysql并不支持时间直接相减操作,应该用专用函数处理,所以一直没有修正。但我认为这个很容易导致使用错误,要么就直接报错,要么显示正确的结果。
要得到正确的时间相减秒值,有以下3种方法:
1、time_to_sec(timediff(t2, t1)),
2、timestampdiff(second, t1, t2),
3、unix_timestamp(t2) -unix_timestamp(t1)
--测试脚本 mysql> select t1, t2, t2-t1, time_to_sec(timediff(t2, t1)) diff1, timestampdiff(second, t1, t2) diff2, unix_timestamp(t2) -unix_timestamp(t1) diff3 from mytest; +---------------------+---------------------+-------+-------+-------+-------+ | t1 | t2 | t2-t1 | diff1 | diff2 | diff3 | +---------------------+---------------------+-------+-------+-------+-------+ | 2013-04-21 16:59:33 | 2013-04-21 16:59:43 | 10 | 10 | 10 | 10 | | 2013-04-21 16:59:33 | 2013-04-21 17:00:33 | 4100 | 60 | 60 | 60 | | 2013-04-21 16:59:33 | 2013-04-21 17:59:35 | 10002 | 3602 | 3602 | 3602 | +---------------------+---------------------+-------+-------+-------+-------+ 3 rows in set
from:http://blog.csdn.net/yzsind/article/details/8831429
3、where查询between和用>=and <=返回值不一致,貌似无论哪个版本都是这样:

原因:
between and 的时候按照bigint去算了,导致后面那个值变成了负数
4、MySQL的varchar定义长度到底是字节还是字符
UTF8字符集下:
SQL>create table test(id int auto_increment,name varchar(10),primary key(id));
SQL>insert into test values(null,'1234567890');
Query OK, 1 row affected (0.00 sec)
SQL>insert into test values(null,'一二三四五六七八九十');
Query OK, 1 row affected (0.00 sec)
SQL>insert into test values(null,'abcdefghig');
Query OK, 1 row affected (0.01 sec)
SQL>insert into test values(null,12345678901);
ERROR 1406 (22001): Data too long for column 'name' at row 1
SQL>insert into test values(null,'一二三四五六七八九十1');
ERROR 1406 (22001): Data too long for column 'name' at row 1
SQL>insert into test values(null,'一二三四五六七八九十一');
ERROR 1406 (22001): Data too long for column 'name' at row 1
SQL>select id,name,length(name),char_length(name) from test;
+----+--------------------------------+--------------+-------------------+
| id | name | length(name) | char_length(name) |
+----+--------------------------------+--------------+-------------------+
| 1 | 1234567890 | 10 | 10 |
| 2 | 一二三四五六七八九十 | 30 | 10 |
| 3 | abcdefghig | 10 | 10 |
+----+--------------------------------+--------------+-------------------+
3 rows in set (0.00 sec)
有此可见,varchar(10) 定义的是字符长度,而length(name) 算的是字节长度,
char_length(name)则计算的是字符长度。
那么varchar能够定义的最大长度是多少呢?这个和你当前所使用的字符集有关。抛开字符,其最大长度为65535字节(这是最大行大小,由所有列共享),而放在不同的字符集下,能够定义的最大长度就会有所不同,如UTF8下是21845。据说MySQL5中varchar的长度也为字符,而MySQL4中的则为字节,未经证实,感兴趣的有环境可以自己测下。
顺便补充一下,char数据类型定义的长度也为字符,其最大长度为255。
http://ourmysql.com/archives/1286?f=wb
5、如何优化MySQL insert性能
合并数据 + 事务插入,可以有效减少 SQL 解析时间和网络IO、事务的频繁创建。
注意事项:
1. SQL语句是有长度限制,在进行数据合并在同一SQL中务必不能超过SQL长度限制,通过max_allowed_packet配置可以修改,默认是1M。
2. 事务需要控制大小,事务太大可能会影响执行的效率。MySQL有innodb_log_buffer_size配置项,超过这个值会日志会使用磁盘数据,这时,效率会有所下降。所以比较好的做法是,在事务大小达到配置项数据级前进行事务提交。
http://blog.jobbole.com/29432/#jtss-tsina
6、关于MySQL count(distinct) 逻辑的一个bug
客户报告了一个count(distinct)语句返回结果错误,实际结果存在值,但是用count(distinct)统计后返回的是0。
原因:设置了 set tmp_table_size=xxx,但 xxx 去重、归并排序内存不够导致排序值被丢弃,进而得不到结果。
解决:set sql_big_tables=on,或者调高上述 size,或者打补丁临时申请内存再释放。
完整案例,请见:http://dinglin.iteye.com/blog/1976026
关于MySQL count(distinct) 逻辑的另一个bug http://dinglin.iteye.com/blog/1982176
7、MySQL关于timestamp和mysqldump的一个“bug”
说说关于timestamp这个字段类型。
首先,从大小上你可以看出来,它不是个字符串,实际上是一个整型。所以当我们执行 where c=” 2012-12-14 00:42:45”的时候,需要将其转换为整型。这就涉及到转换规则。也就是说,对于相同的时间戳,在不同的时区显示的结果是不一样的。反过来也一样,相同的字符串,在不同的时区解释下,会得到不同的时间戳。
我们来看一下整个mysqldump的结果。在文件头部,可以看到
/*!40103 SET TIME_ZONE='+00:00' */; 字样,说明mysqldump在默认情况下,是按’+00:00’(中时区).
而mysql客户端的默认值呢:
mysql> select @@time_zone;
+-------------+
| @@time_zone |
+-------------+
| SYSTEM |
+-------------+
这个SYSTEM表示MySQL取操作系统的默认时区,因此是东8区。
因此会造成:
mysql> select * from tb; +---------------------+ | c | +---------------------+ | 2012-12-14 00:42:45 | +---------------------+ 1 row in set (0.00 sec) 2、dump“出错” mysqldump -Srun/mysql.sock -uroot test tb --where='c="2012-12-14 00:42:45"' | grep INSERT 返回为空,也就是说导不到数据。
解决方案:
(1) mysqldump --tz-utc=0 -Srun/mysql.sock -uroot test tb --where='c="2012-12-14 00:42:45"' |grep INSERT
--tz-utc=0 参数去掉前面的设置时区的动作。
(2) --where='c= from_unixtime(1355416965)' 注意顺序,关系到是否能走索引。
完整案例请见这里:http://dinglin.iteye.com/blog/1747685
8、mysql left( right ) join 使用 on 与 where 筛选的差异
drop table if EXISTS A; CREATE TABLE A ( ID int(1) NOT NULL, PRIMARY KEY (ID) ) ENGINE=MyISAM DEFAULT CHARSET=latin1; drop table if EXISTS B; CREATE TABLE B ( ID int(1) NOT NULL, PRIMARY KEY (ID) ) ENGINE=MyISAM DEFAULT CHARSET=latin1; insert into A values ( 1 ); insert into A values ( 2 ); insert into A values ( 3 ); insert into A values ( 4 ); insert into A values ( 5 ); insert into A values ( 6 ); insert into B values ( 1 ); insert into B values ( 2 ); insert into B values ( 3 ); -- 语句1 select A.ID as AID, B.ID as BID from A left join B on A.ID = B.ID where B.ID<3 -- 语句2 select A.ID as AID, B.ID as BID from A left join B on A.ID = B.ID and B.ID<3
语句 1 的查询结果:
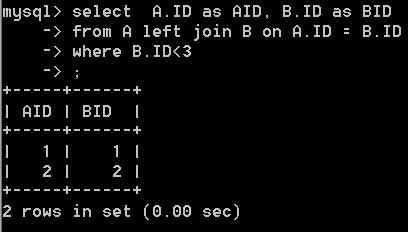
语句 2 的查询结果为:
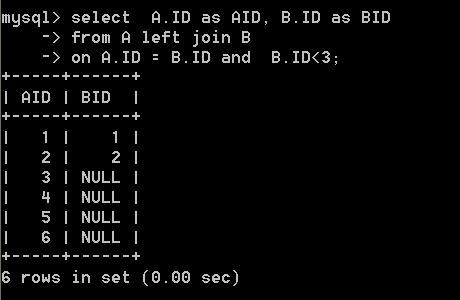
原因:上述两个语句结果不一样的原因是SQL语法顺序和其执行顺序没啥关系,其执行顺序为:
FROM→ON→JOIN→WHERE→GROUP BY→HAVING→SELECT→DISTINCT→ORDER BY→LIMIT
(可以理解为 select 需要在所有的非幂等操作执行完了之后才执行,否则 select 出来的结果就会有问题)
因此ON与where的使用一定要注意场所:
(1):ON后面的筛选条件主要是针对的是关联表【而对于主表刷选条件不适用】。
即主表条件在on后面时附表只取满足主表帅选条件的值、而主表还是取整表。
(2):对于主表的筛选条件应放在where后面,不应该放在ON后面
(3):对于关联表我们要区分对待。如果是要条件查询后才连接应该把查询件放置于ON后。
如果是想再连接完毕后才筛选就应把条件放置于where后面
(4): 对于关联表我们其实可以先做子查询再做join,所以第二个sql等价于:
select A.ID as AID, B1.ID as BID from A left join ( select B.ID from B where B.ID <3 )B1 on A.ID = B1.ID
以上全在mysql5.1上测试过
完整案例请见这里:http://xianglp.iteye.com/blog/868957