入门hadoop安装方法3--hadoop集群
安装-Hadoop2.2集群搭建完全版(基于最终版修改)
目录 [隐藏]
- 一、Centos安装之后基本配置
- 1、给hadoop用户增加sudo权限
- 2、同步时间
- 3、永久关闭防火墙(非常重要,一定要确认)
- 4、关闭SELINUX,设置SELINUX=disabled
- 5、检查机器名
- 6、修改机器名
- 7、修改/etc/hosts
- 二、安装和配置JDK
- 1、下载解压JDK
- 2、Java环境变量配置
- 三、ssh免密码登录
- 1、生成rsa密钥对
- 2、生成authorized_keys
- 3、将authorized_keys复制到datanode
- 4、使用ssh命令测试是否成功
- 四、规划系统目录
- 1、开始建立目录
- 2、修改拥有着
- 五、Hadoop集群配置
- 1、配置/etc/profile
- 2、配置 hadoop-env.sh、mapred-env.sh、yarn-env.sh
- 3、core-site.xml
- 4、hdfs-site.xml
- 5、mapred-site.xml
- 6、yarn-site.xml
- 7、配置slaves文件
- 六、集群网络环境介绍及快速部署
- 1、拷贝虚拟机文件夹
- 2、设置虚拟机名称
- 3、修改hostname
- 4、Centos克隆后网卡问题
- 5、拷贝hadoop配置文件
- 七、Hadoop集群启动
- 1、格式化
- 2、启动hadoop
- 3、查看集群状态
一、Centos安装之后基本配置
1、给hadoop用户增加sudo权限
切换到root用户
$ su – 输入密码
给sudoers增加写权限:
$ chmod u+w /etc/sudoers
编译sudoers文件
$ vi /etc/sudoers
在root ALL=(ALL) ALL下方增加入
hadoop ALL=(ALL)NOPASSWD:ALL
去掉sudoers文件的写权限
$ chmod u-w /etc/sudoers
2、同步时间
root登陆
$ su -
$ ntpdate cn.pool.ntp.org
3、永久关闭防火墙(非常重要,一定要确认)
$ chkconfig iptables off (永久生效)
$ service iptables stop (临时有效)

4、关闭SELINUX,设置SELINUX=disabled
$vim /etc/selinux/config

5、检查机器名
$ hostname
![]()
6、修改机器名
root用户登陆,修改命令如下
$ vim /etc/sysconfig/network
![]()
7、修改/etc/hosts
$ vim /etc/hosts

二、安装和配置JDK
1、下载解压JDK
在windows端下载jdk1.7,然后使用scp或者ftp软件传到Centos系统中/usr/local/下
下载到的文件是:jdk-7u65-linux-x64.tar.gz
切换到usr/local目录下,解压jdk-7u65-linux-x64.tar.gz
$ cd /usr/local/
$ tar -zxvf jdk-7u65-linux-x64.tar.gz
重命名jdk1.7.0_65为jdk
$ mv jdk1.7.0_65/ jdk
2、Java环境变量配置
root用户登陆,命令行中执行命令"vim /etc/profile",并加入以下内容,配置环境变量(注意/etc/profile这个文件很重要,后面Hadoop的配置还会用到)。
#set java environment
export JAVA_HOME=/usr/local/jdk
export JRE_HOME=/usr/local/jdk/jre
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

保存并退出,执行以下命令使配置生效
$ chmod +x /etc/profile
$ source /etc/profile
配置完毕,在命令行中使用命令"java -version"可以判断是否成功。在hadoop用户下测试java -version,一样成功。

三、ssh免密码登录
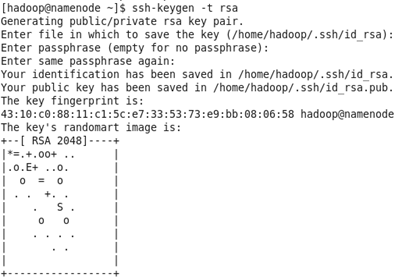
1、生成rsa密钥对
所有节点用hadoop用户登陆,并执行以下命令:
$ ssh-keygen -t rsa
这将在/home/hadoop/.ssh/目录下生成一个私钥id_rsa和一个公钥id_rsa.pub。
$ su hadoop
$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/ hadoop /.ssh/id_rsa): 默认路径
Enter passphrase (empty for no passphrase): 回车,空密码
Enter same passphrase again:
Your identification has been saved in /home/ hadoop /.ssh/id_rsa.
Your public key has been saved in /home/ hadoop /.ssh/id_rsa.pub.
这将在/home/hd_space/.ssh/目录下生成一个私钥id_rsa和一个公钥id_rsa.pub。
2、生成authorized_keys
$ cd /home/hadoop/.ssh/
$ cat id_rsa.pub >> authorized_keys
$ chmod 644 authorized_keys
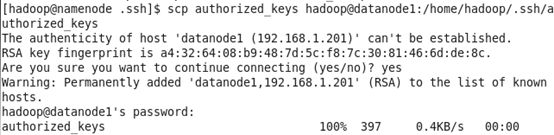
3、将authorized_keys复制到datanode
使用SSH协议将namenode的公钥信息authorized_keys复制到所有DataNode的.ssh目录下。
$ scp authorized_keys data节点ip地址:/home/hd_space/.ssh
$ scp authorized_keys hadoop@datanode1:/home/hadoop/.ssh/authorized_keys
$ scp authorized_keys hadoop@datanode2:/home/hadoop/.ssh/authorized_keys
4、使用ssh命令测试是否成功
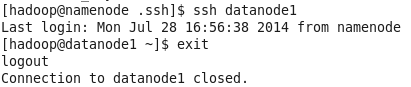
配置完毕,在namenode上执行"ssh NameNode,所有数据节点"命令,因为ssh执行一次之后将不会再询问。在各个DataNode上也进行"ssh NameNode,所有数据节点"命令。
四、规划系统目录
安装目录和数据目录分开,且数据目录和hadoop的用户目录分开,如果需要重新格式化,则可以直接删除所有的数据目录,然后重建数据目录。
如果数据目录和安装目录或者用户目录放置在一起,则对数据目录操作时,存在误删除程序或者用户文件的风险。
| 完整路径 |
说明 |
| /usr/local/hadoop |
hadoop的程序安装主目录 |
| /data/hadoop/storage/tmp |
临时目录 |
| /data/hadoop/storage/hdfs/name |
namenode上存储hdfs名字空间元数据 |
| /data/hadoop/storage/hdfs/data |
datanode上数据块的物理存储位置 |
| /data/hadoop/storage/mapred/local |
tasktracker上执行mapreduce程序时的本地目录 |
| /data/hadoop/storage/mapred/system |
这个是hdfs中的目录,存储执行mr程序时的共享文件 |
1、开始建立目录
在NameNode下,root用户
$ mkdir -p /data/hadoop/{pids,storage}
$ mkdir -p /data/hadoop/storage/{hdfs,tmp,mapred}
$ mkdir -p /data/hadoop/storage/hdfs/{name,data}
$ mkdir -p /data/hadoop/storage/mapred/{local,system}
$ chown -R hadoop:hadoop /data

2、修改拥有着
修改目录/home/hadoop的拥有者(因为该目录用于安装hadoop,用户对其必须有rwx权限。)
$ chown -R hadoop:hadoop /home/hadoop
五、Hadoop集群配置
Hadoop用户登录。
下载hadoop-2.2.0(已编译好的64位的hadoop 2.2,可以加QQ群: 261039241,从群共享里下载),将其解压到/usr/local目录下.
1、配置/etc/profile
$ vim /etc/profile
#set hadoop
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_PID_DIR=/data/hadoop/pids
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
$ source /etc/profile
2、配置 hadoop-env.sh、mapred-env.sh、yarn-env.sh
分别修改:
$vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
$vim /usr/local/hadoop/etc/hadoop/mapred-env.sh
$vim /usr/local/hadoop/etc/hadoop/yarn-env.sh
添加内容:
export JAVA_HOME=/usr/local/jdk
export CLASS_PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_PID_DIR=/data/hadoop/pids
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3、core-site.xml
$ vim $HADOOP_CONF_DIR/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/data/hadoop/storage/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.native.lib</name>
<value>true</value>
</property>
</configuration>
4、hdfs-site.xml
$ vim $HADOOP_CONF_DIR/hdfs-site.xml
<configuration>
<property>
<name> dfs.namenode.name.dir </name>
<value>/data/hadoop/storage/hdfs/name</value>
</property>
<property>
<name> dfs.datanode.data.dir </name>
<value>/data/hadoop/storage/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>namenode:9001</value>
</property>
</configuration>
5、mapred-site.xml
$ vim $HADOOP_CONF_DIR/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.cluster.local.dir</name>
<value>/data/hadoop/storage/mapred/local</value>
</property>
<property>
<name>mapreduce.cluster.system.dir</name>
<value>/data/hadoop/storage/mapred/system</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>namenode:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value> namenode:19888</value>
</property>
</configuration>
6、yarn-site.xml
$ vim $HADOOP_CONF_DIR/yarn-site.xml
<configuration>
<!– Site specific YARN configuration properties –>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>namenode:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>namenode:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>namenode:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>namenode:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>namenode:8088</value>
</property>
</configuration>
7、配置slaves文件
$ vim $HADOOP_CONF_DIR/slaves
删除localhost,加入所有datanode的主机名
| datanode1 datanode2 |
| |
六、集群网络环境介绍及快速部署
集群包含三个节点:1个namenode,2个datanode,节点之间局域网连接,可以相互ping通。
1、拷贝虚拟机文件夹
关闭NameNode虚拟机,把NameNode文件夹,拷贝2份,并命名为DataNode1,,DataNode2。

2、设置虚拟机名称
用VMware打开每个DateNode,设置其虚拟机的名字
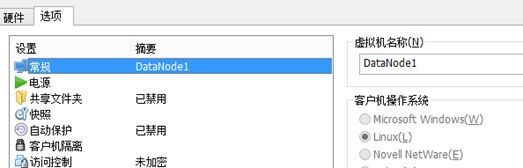
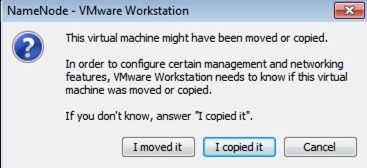
打开操作系统,当弹出对话框时,选择"I copy it"
3、修改hostname
$ vim /etc/sysconfig/network
分别修改为datanode1、datanode2
4、Centos克隆后网卡问题
由于克隆原因,克隆出来的虚拟机默认连接eth1网卡,所以需要动手改为eth0
1)修改/etc/udev/rules.d/70-persistent-net.rules
拷贝eth1的硬件地址到eth0
删除eth1信息
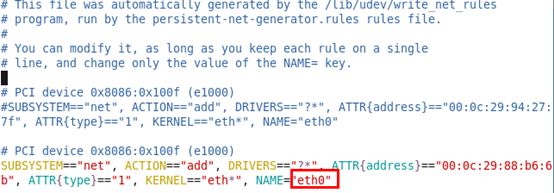
2)配置/etc/sysconfig/network-scripts/ifcfg-eth0
将/etc/udev/rules.d/70-persistent-net.rules 中的ATTR地址拷贝到本文件的HWADDR中
DEVICE="eth0"
BOOTPROTO="static"
HWADDR="00:0C:29:91:42:2C"
MTU="1500"
NM_CONTROLLED="yes"
ONBOOT="yes"
IPADDR=192.168.152.101
NETMASK=255.255.255.0
GATEWAY=192.168.152.2
3)reboot
5、拷贝hadoop配置文件
如果配置文件书写错误,可以在namenode上改好之后使用以下命令拷贝到datanode1、datanode2节点上。
for target in datanode1 datanode2
do
scp -r /usr/local/hadoop/etc/hadoop $target:/usr/local/hadoop/etc
done
七、Hadoop集群启动
1、格式化
$ hadoop namenode -format
—–因为配置了环境变量,此处不需要输入hadoop命令的全路径/hadoop/bin/hadoop
执行后的结果中会提示"dfs/namehas been successfully formatted"。否则格式化失败。
2、启动hadoop
$ start-dfs.sh
$ start-yarn.sh
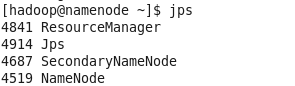
启动成功后,分别在namenode和datanode所在机器上使用jps 命令查看,会在namenode所在机器上看到namenode,secondaryNamenode, ResourceManager
[hadoop@namenode hadoop]$ jps
4841 Jps
4914 SecondaryNameNode
4687 ResourceManager
4519 NameNode
会在datanode1所在机器上看到datanode,tasktracker.否则启动失败,检查配置是否有问题。
[root@datanode1 .ssh]# jps
4074 Jps
4262 DataNode
4170 NodeManager
datanode1所在机器上看到datanode,NodeManager.
3、查看集群状态
$ hdfs dfsadmin -report
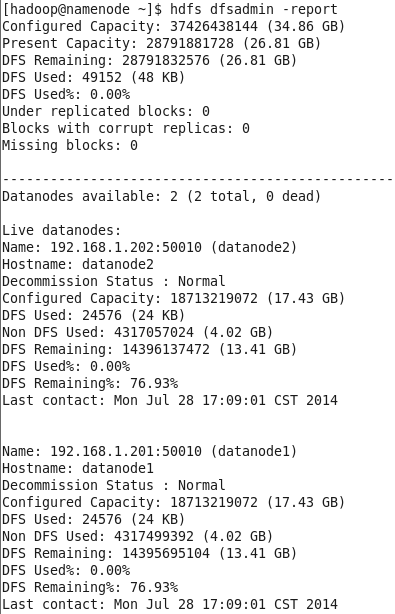
停止hadoop
$ ./sbin/stop-dfs.sh
$ ./sbin/stop-yarn.sh
查看HDFS
http://192.168.1.150:50070/dfshealth.jsp
