搜索引擎之有限状态机
中文分词中用规则识别的词
数字:123,456.781 90.7% 3/8 11/20/2000
日期:1998年 2009年12月24日10:30
缩略(包含不同的情况):
字母-点号-字母-点号组成的序列,比如:U.S. i.e. 等等;
字母开头,最后以点号结束,比如:A. b. Mr. eds. prof. ;
包含非字母字符,比如:AT&T Micro$oft
带杠的词串,比如:three-years-old,one-third,so-called
带瞥号的词串,比如:I'm can't dog's let's
有限状态机
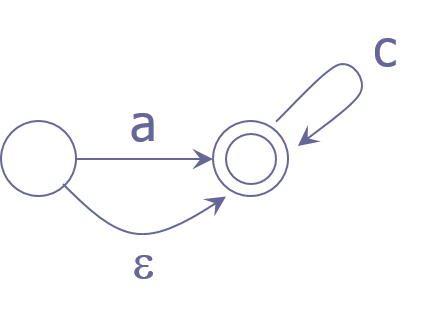
1.霓虹灯闪烁是因为LED灯的状态转换。
2.日期和数字的识别要用到有限状态机
3.正则表达式可以转换成有限状态自动机实现http://osteele.com/tools/reanimator/
正则表达式转换成有限状态自动机
正则表达式:a*b|b*a
基本概念
有限状态机(Finite State Machine简称FSM)或有限自动机是由状态(State)、变换(Transition)和行动(Action)组成的行为模型。
有限状态机首先在初始状态(Start State),接收输入事件(Input Event)后转移到下一个状态。有限状态机通过条件(Guard)判断是否符合转移条件。可以把一个有限状态机看成一个特殊的有向图。
状态
public class State {
private static int nextId = 0;
public int id = nextId++;//状态编号
private String label = “”;//名称
//向下一个状态的变换
private Collection<Transition> transitions = new LinkedList<Transition>();
private boolean finalState = false;//是否结束状态
}
变换
public class Transition {
private Guard guard;//条件
private State nextState; //下一个状态
private State state;//当前状态
public Transition() {//构造方法
}
}
输入事件
public class InputEvent {
public static InputEvent yearNum = new InputEvent(“Y”);//年数字
public static InputEvent digital2 = new InputEvent(“D2”);//2位的日数字
public static InputEvent digital1 = new InputEvent("D1"); //1位的日数字
public String word;
public InputEvent(String w){
this.word = w;
}
public boolean equals(Object obj) {//重写相等判断
if (obj == null || !(obj instanceof InputEvent)) {
return false;
}
InputEvent other = (InputEvent) obj;
if(this.word!=null) {
if(!this.word.equals(other.word)){
return false;
}
return true;
}
return true;
}
}
状态图
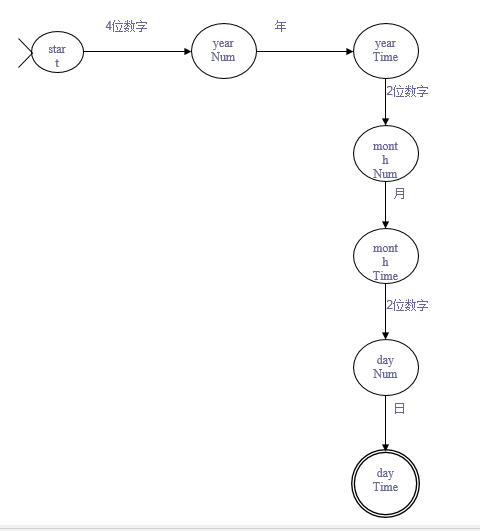
实现有限状态机——FSM类
Guard numGuard = createGuard();
numGuard.setEvent(InputEvent.yearNum);
State yearNumState = createState();
yearNumState.setLabel("yearNum");
createTransition(startState, yearNumState, numGuard);
State yearTimeState = createState();
yearTimeState.setLabel("yearTime");
Guard yearGuard = createGuard();
yearGuard.setEvent(InputEvent.yearUnitEvent);
createTransition(yearNumState, yearTimeState, yearGuard);
…
State daySplitNumState = createState();
daySplitNumState.setLabel("daySplitNum");
daySplitNumState.setFinal(true);
createTransition(daySplitState, daySplitNumState, num2Guard);
createTransition(daySplitState, daySplitNumState, num1Guard);
应用有限状态机
判断字符串是否合法的日期
String s = "2007-10-30 20:44";
System.out.println(isDate(s));
提取日期
林树森在坝陵河大桥通车仪式上的致辞 2009年12月24日10:30 尊敬的石宗源书记、冯正霖副部长,各位来宾、同志们:
System.out.println(getDate(news));
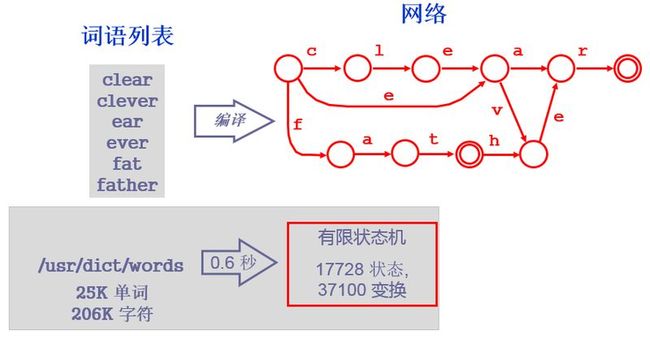
存储词的有限状态接收器
使用工具XFST(http://www.cis.upenn.edu/~cis639/docs/xfst.html)
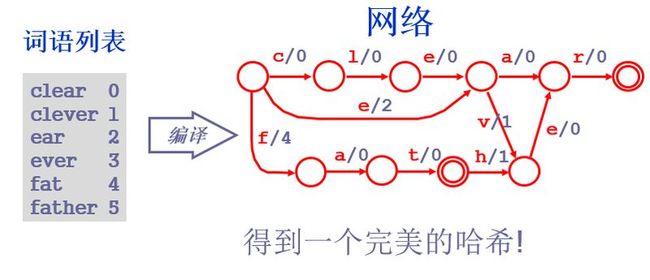
最小完美哈希
对给定的关键词构建最小完美哈西(Order Preserving Minimal Perfect Hash Function简称OPMPHF):
哈西函数:映射关键词到整数
完美:每个关键词映射到唯一的整数
最小:n个关键词映射到0...n-1的值范围
保留顺序:关键词的字母顺序反映到整数值的顺序上
加权有限状态接收器
有限状态转换器(FST)
随着状态的转换,把输入串映射成输出串
识别人名的例子
输入:潘安
输出:姓名
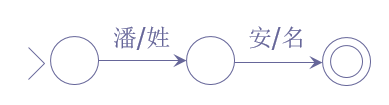
使用有限状态转换器的例子
l小写化字符串
“Go away” ->“go away”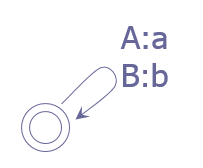
l简繁转换
l把阿拉伯数字转换成汉字
123 ->一百二十三
加权有限状态转换器(WFST)
l有限状态机 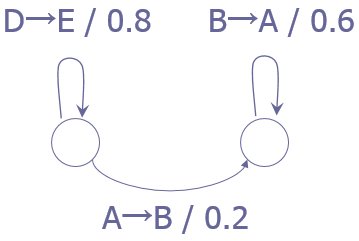
§只根据输入判断是否接收
l有限状态转换器
§根据输入产生输出
l加权有限状态转换器
§根据输入产生带权重的输出
l实现包
§OpenFst
实现从字符串到…

用途举例
FST的操作
合并(Union):
![]()
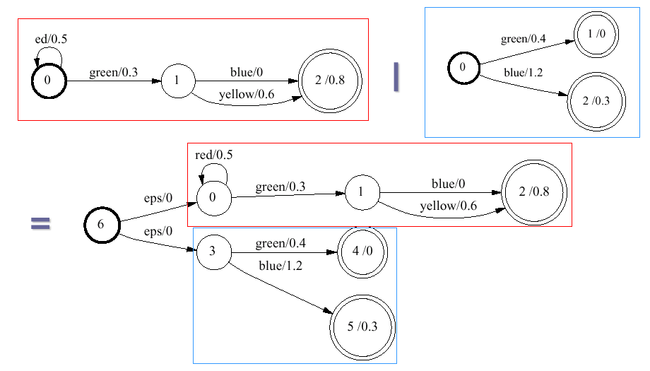
级联(Concatenation):
![]()

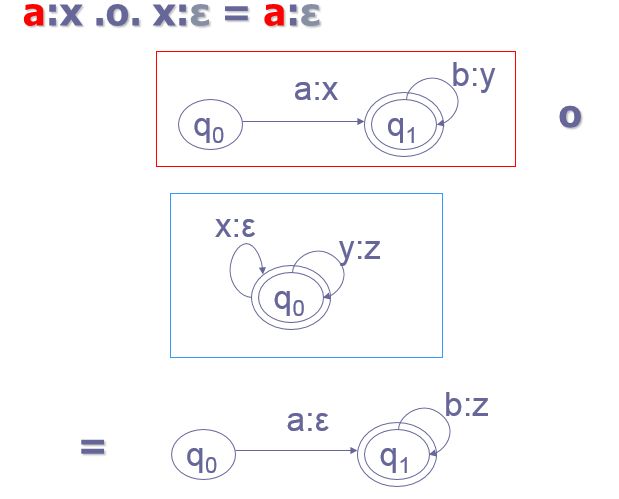
组合(Composition):
![]()
A: (x, z, z, x) → (y, x, x, x)
权重: 1 + 4 + 4 + 3 = 12.
B: (y, x, x, x) → (z, y, y, y)
权重: 3 + 6 + 5 + 5 = 19.
A ○ B: (x, z, z, x) → (z, y, y, y)
总权重: 12 + 19 = 31.
C = A ○ B: (x, z, z, x) → (z, y, y, y)
同样的总权重: 4 + 10 + 9 + 8 =
31.
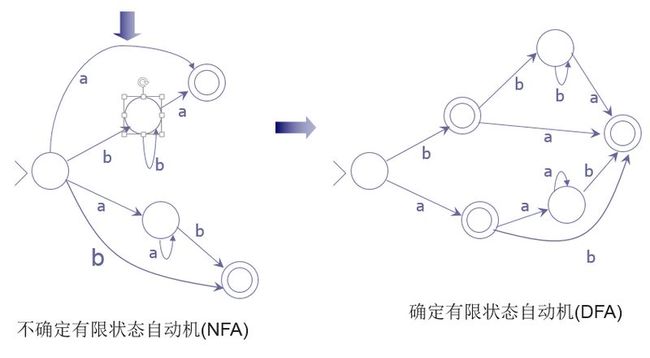
有限状态自动机实现——dk.brics.automaton
l不确定有限状态自动机(NFA)
§Perl或者java.util.regex
lbrics使用确定的有限状态自动机(DFA)
一个简单的模式匹配的例子:
RegExp r = new RegExp("ab(c|d)*");
Automaton a = r.toAutomaton();//把正则表达式转换成DFA
String s = "abcccdc";
System.out.println("Match: " + a.run(s)); // prints: true
lAutomaton用于描述有限状态机。
Automaton 匹配时间复杂度:O(n) 这里n=单词长度
采用了独立于模式复杂性的变换函数:
return transitions[state * points.length+ classmap[c]];
lRunAutomaton用于运行有限状态机。
boolean run(String s) 测试有限状态机是否能接收给定的字符串
public boolean run(String s) {
int p = initial;
int l = s.length();
for (int i = 0; i < l; i++) {
//返回从当前状态读入给定字符后的状态
p = step(p, s.charAt(i));
if (p == -1) return false;
}
return accept[p];
}
int run(String s, int offset) 返回从指定位置开始的可接收的最大长度
状态转换表
每一行代表一个状态,每一列代表一个输入符号。
第0列代表’a’,第1列代表’b’,……,依此类推
int[][] d = {
{},
{2, 3},
{2, 4},
{2, 3},
{2, 5},
{2, 3}
};
dk.brics.automaton中的状态转换表
//用一维数组存储状态转换表
int[] transitions; // delta(state,c) = transitions[state*points.length + getCharClass(c)]
//取得状态转换表
static Transition[][] getSortedTransitions(Set<State> states) {
setStateNumbers(states);
Transition[][] transitions = new Transition[states.size()][];
for (State s : states)
transitions[s.number] = s.getSortedTransitionArray(false);
return transitions;
}
Lucene中的自动机——AutomatonQuery
用有限状态机(不确定有限状态自动机NFA或确定性有限状态自动机DFA)表示Lucene词典。索引作为状态机,识别单词并且转换出匹配的文档
AutomatonQuery把用户查询表示成FSM。例如,正则表达式匹配:(http|ftp)://foo.com

AutomatonQuery可用于指定编辑距离的模糊搜索
AutomatonQuery实现来源于http://www.brics.dk/automaton/
编辑距离(Levenshtein Distance)
编辑距离就是用来计算从原串(s)转换到目标串(t)所需要的最少的编辑操作次数。可能的操作包括插入,删除和替换。例如源串是“诺基压”,目标串是“诺基亚”,则编辑距离是1。
例如将kitten一词转成sitting的过程:
sitten (k→s)
sittin ( e→i )
sitting ( →g )
因此编辑距离是3。
编辑距离的算法是首先由俄国科学家Levenshtein提出的,故又叫Levenshtein Distance。
使用AutomatonQuery
l前缀查询(PrefixQuery):
例如“bla*”可以重复0到n次,可以匹配bla,或blabla,...
l模糊查询(FuzzyQuery) :
例如编辑距离在2以内的字符串,例如“bla~”可以匹配blana或blue
l一个模糊前缀查询(FuzzyPrefixQuery)的例子:
//查询的term代表,包含列
Term term= new Term("yourfield", "bla~*");
//对所有的和“bla”编辑距离在2以内的字符串构建一个确定性有限状态自动机
Automaton fuzzy = new LevenshteinAutomata("bla").toAutomaton(2);
//串联它和另外一个DFA等于"*"操作符
Automaton fuzzyPrefix=
BasicOperations.concatenate(fuzzy,BasicAutomata.makeAnyString());
//构建一个查询,用它搜索以得到结果
AutomatonQueryquery = new AutomatonQuery(term, fuzzyPrefix);
AutomatonQuery用于词干化
l在索引和查询时词干化:
§例如:walked, walking -> walk
§通过合并词形,可以提高检索效率
l存在的问题:
§错误:international -> intern
§词干化后的词对模糊匹配不友好
l改进:把词干化看成是一种查询扩展。索引时不删除数据
§用扩展查询代替。搜索walk时,同时也搜索walked, walking。
§可以支持模糊匹配和精确查找