Storm Tutorial
Tutorial
原文地址
在本教程中,你将学会如何创建Storm Topologies 并且部署它们到storm集群中。Java是主要用到的语言,少数例子用python来解释Storm的多语言功能。
Preliminaries
该教程用到 storm-starter中的例子。建议clone该项目,跟着里面的例子学习。搭建storm开发环境 ,并且在本机创建一个Storm Project
Components of a Storm cluster
storm集群和hadoop集群很类似。在Hadoop上,我们跑 MapReduce Jobs, 而在storm集群中我们跑topologies。Jobs 和 topologies本身是非常不一样的,一个重要的不同是:MapReduce job最终会结束,而topology将一直处理消息,直到你杀死它。
storm集群中有两类节点:master节点,worker节点。master节点运行一个叫作"Nimbus"的守护进程,类似于Hadoop中的 JobTracker。Nimbus负责在集群中分发代码,分配任务到各个worker,并且监控failures。
每个worker节点运行一个叫作Supervisor的守护进程。Supervisor监听Nimbus分配给它的work,根据Nimbus的分配开始或停止Worker 进程。每个worker进程执行一个topology的子集;一个运行的topology包含运行在很多节点上的worker进程。
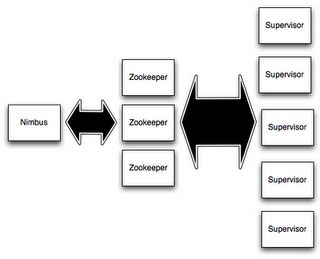
Nimbus和Supervisors之间的协作通过Zookeeper集群来完成。另外 Nimbus进程与Supervisor进程 都是快速失败的,并且是无状态的;所有的状态保存在zookeeper或者本地磁盘中。这意味着你可以通过kill -9 结束Nimbus和 Supervisors,然后可以像没发生任何事情一样重启。这种设计保证storm的稳定性。
Topologies
在storm上集群实现实时计算,你可以创建topologies。一个topology是一个计算图。在topology中的每个节点都包含一个处理逻辑,节点之间的关联,表明数据应该在节点之间传输。
运行一个topology是简单的。首先你把所有的代码和依赖打包成一个单独的jar。然后运行如下的命令:
storm jar all-my-code.jar backtype.storm.MyTopology arg1 arg2
加上参数 arg1 arg2 ,运行backtype.storm.MyToplogy类。该类主要的功能是定义了topology,并提交它到Nimbus。storm jar负责连接Nimbus,并将jar上传到Nimbus上。
由于topology的定义是Thrift结构,并且Nimbus是一个Thrift服务,所以你可以用任何语言创建提交topologies。上面的例子主要是基于JVM语言的方式。开始结束topologies具体信息见Running topologies on a production cluster
Streams
在storm中核心的抽象概念是stream。一个stream代表一个无界的tuples(元组)。storm用分布式,可靠的方式提供原语来把stream转化为新的stream。例如,你可以把tweets流转化为话题趋势流。
storm提供的最基本的原语是Spout和bolt。Spout和bolt包含你要实现的接口,在接口里面,你要实现自己的程序逻辑。
一个Spout是streams的来源。例如,spout可以从消息队列中读取tuples,并把它们作为stream提交。
一个Bolt消费任何数量的输入流,并处理这些流,处理完有可能把结果作为新的流提交。复杂的流转化需要很多步骤,需要在多个bolts之间传输。 Bolts 可以运行任何函数,比如filter tuples,或者做stream聚合,持久化结果数据。
Spouts与Bolts之间的网络结构被打包成"topology",topology是一个高度抽象的概念,是一个流转换图,图中的连线代表流的流转方向。
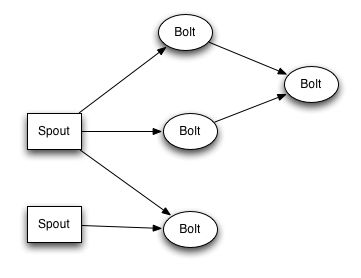
在storm toplogy中,每个节点都是并行的。在你的topology中,你可以为每个节点指定有多少并行。Storm将根据集群生成一定数量的线程来执行操作。
Data model
Storm用元组作为数据模型。一个元组代表一组值。在元组中一个字段可以是任意类型的数据。如果用Object类型的,你需要实现序列化接口。
在topology中你必须声明输出的字段。例如,下面的bolt声明了一个2个元素的tuple:'double','triple'
public class DoubleAndTripleBolt extends BaseRichBolt {
private OutputCollectorBase _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollectorBase collector) {
_collector = collector;
}
@Override
public void execute(Tuple input) {
int val = input.getInteger(0);
_collector.emit(input, new Values(val*2, val*3));
_collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("double", "triple"));
}
}
declareOutputFields 声明输出字段 ‘double’,'triple'。剩下的部分将在下面的部分讲解。
A simple topology
下面我们看一个简单的topology,并探索里面简单的概念。我们看storm-starter中 ExclamationTopology概念。
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("words", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3)
.shuffleGrouping("words");
builder.setBolt("exclaim2", new ExclamationBolt(), 2)
.shuffleGrouping("exclaim1");
该topology中包含一个spout 两个bolt 。spout提交words,每个bolt添加'!!!'到它的输入中。spout提交到第一个bolt,然后这个bolt把结果提交到第二个bolts。如果spout提交'bob',最后结果将会'bob!!!!!!'
用setSpout与setBolt方法定义节点。这些方法接受用户指定的ID,和一个处理逻辑的对象,以及你想要该节点的并行度。
处理逻辑对象的Spout与bolt必须实现相应的借口,spout要实现IRichSout,bolt要实现IRichBolt。
最后一个并行数据的参数可以省落。它代表多少个线程来处理改逻辑代码。如果省落,表明只有一个线程来处理。
setBolt 返回一个 InputDeclarer 对象,用来定义对bolt的输入。这里的exclaim1用shuffle grouping 代表它想读所有的 words 的输出。exclaim2用shuffle grouping代表它要读exclaim1的所有输出。
如果你想要exlaim2读取所有的words 与 exclaim1 组件的输出,你可以像下边的方式下
builder.setBolt("exclaim2", new ExclamationBolt(), 5)
.shuffleGrouping("words")
.shuffleGrouping("exclaim1");
如你所见,对于bolt的输入可以指定多个sources。
我们下面看下topology中spout bolt的具体实现。
TestWordSpout 每100ms 提交随机的单词,TestWordSpout中的nextTuple()的实现如下
public void nextTuple() {
Utils.sleep(100);
final String[] words = new String[] {"nathan", "mike", "jackson", "golda", "bertels"}; final Random rand = new Random();
final String word = words[rand.nextInt(words.length)];
_collector.emit(new Values(word));
}
ExclamationBolt只往输入的内容中添加'!!!',下面是具体的实现
public static class ExclamationBolt implements IRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) { _collector = collector;
}
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
public Map getComponentConfiguration() {
return null;
}
}
prepare方法提供了outPutCollector供提交tuples用。元组在任何时间从bolt提交:prepare,execute ,cleanup ,甚至在异步线程中都可以提交tuple。该prepare方法仅仅把OutputCollector实例保存到本地变量引用。
execute方法仅仅接收tuple,并在第一个filed后添加 '!!!',然后提交。如果你实现了多源输入,你可以通过Tuple.getSourceComponet获取输入来自哪个源。
cleanup方法主要是用来当bolt关闭时,用来清理关闭打开的资源。不保证该方法在关闭的时候一定被调用。
declareOutputFields用来声明ExclaimationBolt的提交的tuple元素字段。
cleanup与getComponentConfiguration不必实现。所以你可以定义bolt用一个默认的基类:BaseRichBolt
public static class ExclamationBolt extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) { _collector = collector;
}
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
Running ExclamationTopology in local mode
Storm有两种运行模式:本地模式 ,分布式模式。本地模式,Storm用多线程模拟worker处理过程。本地模式在测试开发过程是很有用的。当你运行storm-starter中的例子,它们将用本地模式启动,你能看到每个组件的提交消息。
分布式模式中, storm操作所有的机器作为一个集群。当你提交一个topology到master上,你必须也到提交所有的依赖代码到topology中。master将分发你的代码到集群,并且分配worker来跑topology。如果worker挂了, master将会重新分配任务到别的地方。下面是一个本地模式topology
Config conf = new Config();
conf.setDebug(true);
conf.setNumWorkers(2);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();
上边的代码通过LocalCluster定义了集群。通过提交topologies到虚拟集群与提交到分布式集群是一致的。LocalCluster通过调用submitTopology,加上topology的名字参数,配置参数,及topology对象本身。
name参数是用来区分topology的,你可以通过name来kill topology。一个topology将一直运行直到你kill 它。
config是用来调优topology运行的各个方面。下面两个配置是经常的:
1)TOPOLOGY_WORKERS(setNumWorkers) :指定了节点的worker数量。
2)TOPOLOGY_DEBUG(setDebug):当设为true时,storm 将打印每条被组件提交的消息。这对调试很有帮助。
Stream groupings
stream grouping告诉topology两个组件之间如何发送tuples。spouts 和bolts 都是以并行的方式来执行的。下边的图展示topology执行task的状态:

stream grouping 告诉storm 在任务集中如何去发送tuples。有以下几个种类型的grouping:
1) shuffle grouping: tuples在bolt的任务集中是是被随机分配的,每个bolts都会得到相同数量的tuples。
2)fields grouping:stream将被fileds分成不同的部分。如何group by 'user-id',那么相同user-id的 tuples将会被流向同一个task,不同的user-id或许流向不同的task.
3)all grouping:所有的stream将会被流向所有的tasks。应该小心的用这种grouping。
4)global grouping:整个stream流向bolt的一个单一task。
5)none grouping:不指定grouping ,效果类似shuffle grouping。
6)direct grouping: stream的生产者决定stream的流向。
Guaranteeing message processing
Guaranteeing message processing
Transactional topologies
Transactional-topology
Distributed RPC
Distributed-RPC
转载标注:http://my.oschina.net/robinyao/blog/415934