解码一帧Layer3第3步:哈夫曼解码 -- huffmanDecoder方法
1.哈夫曼码表 共有33张码表,从ISO/IEC 11172-3复制一张码表出来,看看码表的庐山真面目,下面说到的哈夫曼树的构造及解码过程都以这一张表为例。码表如下所示:
Huffman code table 6
x y hlen hcod No.
0 0 3 111 0
0 1 3 011 1
0 2 5 00101 2
0 3 7 0000001 3
1 0 3 110 4
1 1 2 10 5
1 2 4 0011 6
1 3 5 00010 7
2 0 4 0101 8
2 1 4 0100 9
2 2 5 00100 10
2 3 6 000001 11
3 0 6 000011 12
3 1 5 00011 13
3 2 6 000010 14
3 3 7 0000000 15
码表的每一行由4个元素x、y、hlen、hcod组成,其最后一列是为了后文描述问题方便,我加上去的。解码大值区,一个码字(hcod)解码得到x、y两个值,hlen是码字的长度。33张码表中这几个值的取值范围是:x=0..15,y=0..15,hlen=0..19。其实33张码表只有象“Huffman code table 6”这样的表15张,码表有“共用”的情况,但是“共用”码表的linbits不同,看一看HuffmanBits的构造方法就明白这一点了。
2.哈夫曼树 哈夫曼解码用位流索引查表法,无论你采用何种数据结构存储码表,码表在逻辑是仍然是树形结构。
(1).2叉树 可以构造一棵2叉树装入这张码表,从位流中读入一位,根据是0还是1确定指向左子树还是右子树,直至到达叶结点,叶结点保存x、y,这样就可以由位流解得一个码字的2个码值的x和y了。
(2).N叉树 采用2叉树这种数据结构一次只能从位流处理1位,效率比较低。如果一次处理位流中的n位,采用N(N=2^n)叉树这种数据结构。以一次处理2位的4叉树为例,上面的码表“Huffman code table 6”构造出的4叉树如下:
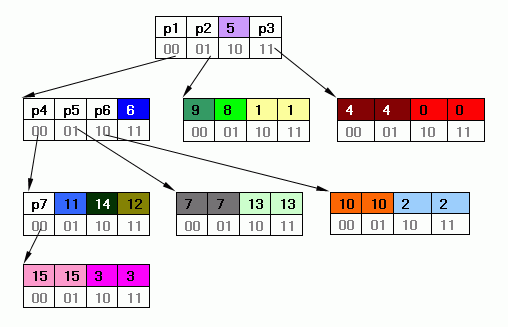
- 图中每一个2行4列的表格表示4叉树的的一个结点;
- 每个结点的第一行中的数字0..15表示码表“Huffman code table 6”中的序号,例如15表示NO.15这一行,存储4叉树的时候,编号0..15的域(图中的1格)存储码表的x、y、hlen,根据其取值范围,存储x和y各需4比特,存储hlen需5比特,所以这3个值可以存储在一个short类型的整数内;
- 每个结点第1行的p1..p7表示该结点不是叶结点,该结点的这个域存储的是指向下一个结点的“指针”,JAVA没有指针类型,这个4叉树采用数组来存储,用p1..p7存储数组下标,这个下标值同样用 一个 short类型的整数值表示 ;
- 存储4叉树用short类型的数组,其数组元素既有“指针”也有叶结点中某个域的值,用正、负号来区分它们。
- 每个结点第2行的00、01、10、11表示一个结点内“子树”的编号。2叉树用左子树、右子树描述其子孙;4叉树用00子树、01子树...去描述。
- 如果hlen为奇数,需要在末尾分别补上0和1凑成偶数。例如No.4这一行,hlen=3,hcod=110,要补成1100和1101,这两个二进制串都表示No.4这一行。这就是说,采用N叉树会使存储表冗余,n越大冗余度越大。
- 4叉树示意图举例:No.3这一行hcod=0000001,按长度2将hcod分为00、00、00、10(或11)共4部分,分别对应图中4个结点的p1、p4、p7、3这4个域。No.3这一行的hlen=7,为奇数,同样要补成偶数,所以图中有一个结点的两个域都是“3”。
- 遍历如图所示的4叉将结点的各个域存储到一个short类型的数组内,就存储好这张码表了。可以用任意一种方式遍历,先根次序、后根次序、层次遍历都可以。上图“Huffman code table 6”的4叉树存储在数组中为:
private final static short htbv6[] = { //32
-4, -24, 529, -28, -8, -16, -20,1042, -12,1571,1586,1584,1843,1843,1795,1795,
1299,1299,1329,1329,1314,1314,1282,1282,1057,1056, 769, 769, 784, 784, 768, 768};
htbv6被初始化到解码用的码表htBV[6],见下文给出的源代码 HuffmanBits.java的第52行,这一行中的0表示该码表的linbits=0。
3.哈夫曼解码 下文给出的源代码 HuffmanBits.java的第135行是选择码表,假设当前选中的是 htBV[6],即htCur= htBV[6],htCur.table=htbv6:
- 136行取得linbits,对htCur而言linbits=0;
- 138行刷新intMask,从位流中读入32位存储在intMask中,intMask的高几位为某一hcod,假如intMask=00010xxx xxxxxxxx xxxxxxxx xxxxxxxx ,这里的x可能为0,也可能为1;
- 139行用iTmp暂存intMask的值;
- 140行iTmp>>>30表示取iTmp的高2位(00),y=htbv6[0]=-4, y<0表示示该值是一个“指针”,其绝对值表示在htbv6[]中的下标 ;
- 141行,y<0进入while循环,这个while循环就是查表的过程。
- 第1次循环:142行iTmp <<= 2表示iTmp最高2位被移去,iTmp变为010xxxxx xxxxxxxx xxxxxxxx xxxxxxxx;143行iTmp >>> 30表示取iTmp最高2位(01),此时y=htbv6[1-(-4)]=htbv[5]=-16,y<0继续执行循环;
- 第2次循环:142行iTmp 最高2位被移去,iTmp变为0xxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx;143行 取iTmp最高2位,可能为00,也可能为01:
- 假如为00,y=htbv6[0-(-16)]=htbv[16]=1299,y>0结束循环;
- 假如为01,y=htbv6[1-(-16)]=htbv[17]=1299,y>0结束循环;
- 145行y>>8将y的16..23位被移到低字节,这一字节存储的是hlen,x=1299>>8=5;
- 146行intBitNum表示intMask剩余的比特数,本次解码用去5位,执行intBitNum-=5,表示要从intMask取走5位;
- 147行,将intMask的最高5位移出;
- y的低字节存储的是码表中的x和y,各4位;149行(y >> 4) & 0xf表示取y最低字节的高4位,所以x=(1299>>4) & 0xf=1;
- 150行 表示取y最低字节的低4位,所以y=1299 & 0xf=3;
- 此时已经解得码表中的No.7这一行:x=1,y=3,用去5比特;
- 152行是对x进一步处理。如果当前选择的某一码表解得的x=15并且码表的linbits>0,需要从位流中读入linbits得到一个整数值与x相加;
- 159行intMask<0意思是intMask的最高位为1,这一位表示x的符号位,若为1表示解得的x是一负数,反之表示解得的x为正数;
- 160行将解得的x保存到intHuffValue[];
- 168--182行对y进一步处理,同对x进一步处理的过程一样;
主信息的第二部分内容是以哈夫曼编码的主数据(main_data)。MP3编码器在将PCM编码过程中先是用有损压缩使数据长度大大缩短,然后用哈夫曼编码这种无损压缩方式进一步减小数据流长度。每个粒度组内的频谱值使用不同的哈夫曼码表编码,全频率段从0到奈奎斯特频率(Nyquist frequency,等于采样率的二分之一)被划分为几个按不同码表编码的区段,区段是根据最大量化值来划分的。对高频率低幅值的信号不编码,即被压缩掉了。为了提高编码过程中哈夫曼编码效率,主数据被划分为三部分:大值区、小值区、零值区。示意图如下:

大值区 一个码字(hcod)解码得到两个值,码表的成员变量linbits的值为0..13,如果linbits不为0并且x(或y)=15,还需要从位流中读入linbits位得到一个整数值与x(或y)相加,可以计算出解码大值区得到的最大值(绝对值)为15+(2^13-1)=8206。解码大值区最多可能用到三张不同的码表。怎么知道当前的码流该用哪一张码表呢?GRInfo内定义了两个成员变量:region1Start和region2Start,它表示一张码表解码得到的值的个数,解得指定个数的值之后更换另一张码表。该更换到哪一张码表呢?解码帧边信息时已经初始化了GRInfo的成员变量table_select,当前可能用到的码表(最多3张)编号就存储在其中。
region1Start和region2Start 这两个变量在 Layer3的huffmanDecoder方法内被初始化,根据MPEG的版本(1.0/2.0/2.5)和“块”的类型初始化为不同的值。不同的块,子带的宽度不同。块和子带这些概念在后文再作交待。
供解码大值区使用的共有31张码表,其中第0张表hlen=0(其实不会被使用吧),第4、14码表不用。大值区中的一个码字(hcod)解得两个值,由帧边信息结构中的big_values可以计算出解码出大值区得到的值的个数 。
小值区 又称为count1区 ,解码得到的值为0,1或-1,整个小值区解码只用一张码表。供解码小值区使用的共有两张码表。小值区中的一个码字解得4个值。
零值区 未编码,所以不用解码,直接置为缺省值0。
位流中一帧主数据的末尾可能填充了几位而使之凑足一个字节,解码时对填充位作舍弃处理。调试程序时发现有填充位超过一字节的情况。
class Layer3内的huffmanDecoder方法源码如下:
//3.
//>>>>HUFFMAN BITS=========================================================
/*
* nozero_index[]: 调用objHuffBits.decode()方法赋值;在Requantizer()方法内被修正;
* 在hybird方法内使用.
*/
private static int[] rzero_index = new int[2];
private static int[] is; //[32 * 18 + 4];
private static HuffmanBits objHuffBits;
private void huffmanDecoder(final int ch, final int gr) {
GRInfo s = objSI.ch[ch].gr[gr];
int r1, r2;
if (s.window_switching_flag != 0) {
int v = objHeader.getVersion();
if(v == Header.MPEG1 || (v == Header.MPEG2 && s.block_type == 2)){
s.region1Start = 36;
s.region2Start = 576;
} else {
if(v == Header.MPEG25) {
if(s.block_type == 2 && s.mixed_block_flag == 0)
s.region1Start = intSfbIdxLong[6];
else
s.region1Start = intSfbIdxLong[8];
s.region2Start = 576;
} else {
s.region1Start = 54;
s.region2Start = 576;
}
}
} else {
r1 = s.region0_count + 1;
r2 = r1 + s.region1_count + 1;
if (r2 > intSfbIdxLong.length - 1) {
r2 = intSfbIdxLong.length - 1;
}
s.region1Start = intSfbIdxLong[r1];
s.region2Start = intSfbIdxLong[r2];
}
rzero_index[ch] = objHuffBits.decode(ch, s, is); // 哈夫曼解码
}
//<<<<HUFFMAN BITS=========================================================
实例化class HuffmanBits类型变量objHuffBits,用语句objHuffBits.decode()调用HuffmanBits的decode方法就完成了解码一个粒度组中的一个声道的哈夫曼解码。解码输出的结果暂存到is[]供下一步使用。
进一步了解哈夫曼解码细节 哈夫曼解码是MP3的关键模块之一,对解码器的效率(速度和内存开销)有较大影响。怎样设计出高效的哈夫曼解码器,至今仍有不少人在探索。我的哈夫曼解码方法只是一个尝试。我的另一篇贴子《MP3解码之哈夫曼解码快速算法》也是讲哈夫曼解码的,网址:
论坛:http://www.iteye.com/topic/737963
博客:http://lfp001.iteye.com/blog/737850
HuffmanBits.java源码如下:
/*
* HuffmanBits.java -- MPEG 1.0/2.0/2.5 Audio Layer I/II/III 哈夫曼解码
*
* This program is free software: you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation, either version 3 of the License, or
* (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program. If not, see <http://www.gnu.org/licenses/>.
*/
package decoder;
import decoder.Layer3.GRInfo;
public final class HuffmanBits {
private final class HuffTab {
public int linbits;
public short[] table;
public HuffTab(int l, short[] t) {
this.linbits = l;
this.table = t;
}
}
/*
* intMask: 暂存位流缓冲区不超过32比特数据,位流2级缓冲
* intBitNum: intMask剩余的比特数
* intPart2Remain: 哈夫曼编码的主数据剩余的比特数
* intRegion[]: 大值区某一码表解码主数据的区域
*/
private int intBitNum, intMask, intPart2Remain;
private static final int[] intRegion = new int[3];
private BitStream bsMainData;
private static final HuffTab[] htBV = new HuffTab[32];
private static final HuffTab[] htCount1 = new HuffTab[2];
public HuffmanBits(BitStream objBS) {
this.bsMainData = objBS;
htBV[0] = new HuffTab(0, htbv0); //hlen=0
htBV[1] = new HuffTab(0, htbv1);
htBV[2] = new HuffTab(0, htbv2);
htBV[3] = new HuffTab(0, htbv3);
htBV[4] = new HuffTab(0, htbv0); //not used
htBV[5] = new HuffTab(0, htbv5);
htBV[6] = new HuffTab(0, htbv6);
htBV[7] = new HuffTab(0, htbv7);
htBV[8] = new HuffTab(0, htbv8);
htBV[9] = new HuffTab(0, htbv9);
htBV[10] = new HuffTab(0, htbv10);
htBV[11] = new HuffTab(0, htbv11);
htBV[12] = new HuffTab(0, htbv12);
htBV[13] = new HuffTab(0, htbv13);
htBV[14] = new HuffTab(0, htbv0); //not used
htBV[15] = new HuffTab(0, htbv15);
htBV[16] = new HuffTab(1, htbv16);
htBV[17] = new HuffTab(2, htbv16);
htBV[18] = new HuffTab(3, htbv16);
htBV[19] = new HuffTab(4, htbv16);
htBV[20] = new HuffTab(6, htbv16);
htBV[21] = new HuffTab(8, htbv16);
htBV[22] = new HuffTab(10, htbv16);
htBV[23] = new HuffTab(13, htbv16);
htBV[24] = new HuffTab(4, htbv24);
htBV[25] = new HuffTab(5, htbv24);
htBV[26] = new HuffTab(6, htbv24);
htBV[27] = new HuffTab(7, htbv24);
htBV[28] = new HuffTab(8, htbv24);
htBV[29] = new HuffTab(9, htbv24);
htBV[30] = new HuffTab(11, htbv24);
htBV[31] = new HuffTab(13, htbv24);
htCount1[0] = new HuffTab(0, htc0);
htCount1[1] = new HuffTab(0, htc1);
}
private void refreshMask() {
while(intBitNum < 24) {
intMask |= bsMainData.get1Byte() << (24-intBitNum);
intBitNum += 8;
intPart2Remain -= 8;
}
}
/*
* decode方法: 一个粒度组内的一个声道哈夫曼解码
*
* ch: 声道
* objGRI: 粒度组信息
* intHuffValue[]: 接收解码得到的576个值
* 返回值: 576减去rzone区长度.
*/
public int decode(final int ch, final GRInfo objGRI, int[] intHuffValue) {
int i, x, y, iTmp, linbits, intIndex=0;
HuffTab htCur;
/*
* 1. 初始化4个成员变量intBitNum,intMask,intPart2Remain,intRegion[]
*/
intBitNum = intMask = 0;
intPart2Remain = objGRI.part2_3_length - objGRI.part2_bits;
x = objGRI.region1Start; // region1
y = objGRI.region2Start; // region2
i = objGRI.big_values << 1; // bv
if(i > 574)
i = 574; // 错误的big_value置为0 ?
if(x < i) {
intRegion[0] = x;
if(y < i) {
intRegion[1] = y;
intRegion[2] = i;
} else
intRegion[1] = intRegion[2] = i;
} else
intRegion[0] = intRegion[1] = intRegion[2] = i;
/*
* 2. 使位流缓冲区bsMainData字节对齐
*/
intBitNum = 8 - bsMainData.getBitPos();
intMask = bsMainData.getBits9(intBitNum);
intMask <<= 32 - intBitNum;
intPart2Remain -= intBitNum;
/*
* 3. 解码大值区
*/
for (i = 0; i < 3; i++) {
htCur = htBV[objGRI.table_select[i]];
linbits = htCur.linbits;
while(intIndex < intRegion[i]) {
refreshMask();
iTmp = intMask;
y = htCur.table[iTmp >>> 30];
while (y < 0) {
iTmp <<= 2;
y = htCur.table[(iTmp >>> 30) - y];
}
x = y >> 8; // hlen
intBitNum -= x;
intMask <<= x;
x = (y >> 4) & 0xf; // 解得两个值
y &= 0xf;
if (x != 0) {
if(x == 15 && linbits != 0) {
refreshMask();
x += intMask >>> (32 - linbits); // 循环右移
intBitNum -= linbits;
intMask <<= linbits;
}
if(intMask < 0)
intHuffValue[intIndex++] = -x;
else
intHuffValue[intIndex++] = x;
intBitNum--;
intMask <<= 1;
} else
intHuffValue[intIndex++] = 0;
if (y != 0) {
if (y == 15 && linbits != 0) {
refreshMask();
y += intMask >>> (32 - linbits);
intBitNum -= linbits;
intMask <<= linbits;
}
if(intMask < 0)
intHuffValue[intIndex++] = -y;
else
intHuffValue[intIndex++] = y;
intBitNum--;
intMask <<= 1;
} else
intHuffValue[intIndex++] = 0;
}
}
/*
* 4. 解码count1区
*/
htCur = htCount1[objGRI.count1table_select];
while(intIndex < 572) {
refreshMask();
iTmp = intMask;
y = htCur.table[iTmp >>> 28];
while (y < 0) {
iTmp <<= 4;
y = htCur.table[(iTmp >>> 28) - y];
}
x = y >> 8; // hlen
intBitNum -= x;
intMask <<= x;
if(intPart2Remain + intBitNum <= 0) {
intBitNum -= intPart2Remain + intBitNum;
break;
}
y <<= 28;
for(i = 0; i < 4; i++) { // 一个码字(hcod)解码得到4个值
if(y < 0) {
if(intMask < 0)
intHuffValue[intIndex++] = -1;
else
intHuffValue[intIndex++] = 1;
intBitNum--;
intMask <<= 1;
} else
intHuffValue[intIndex++] = 0;
y <<= 1;
}
}
/*
* 5. rzone区直接置0,即intHuffValue[nozero_index..575]=0
*/
int nozero_index = intIndex;
while(intIndex < 576)
intHuffValue[intIndex++] = 0;
/*
* 6. 丢弃位流缓冲区中的填充位.填充位不超过多少位?
*/
intPart2Remain += intBitNum;
if(intBitNum > 0)
bsMainData.backBits(intBitNum); // intBitNum比特归还位流缓冲区
if(intPart2Remain > 0) {
while(intPart2Remain > 8) {
bsMainData.getBits9(8); // 不再是字节对齐的
intPart2Remain -= 8;
}
if(intPart2Remain != 0)
bsMainData.getBits9(intPart2Remain);
}
return nozero_index;
}
///////////////////////////////////////////////////////////////////////////
// 码表
// 码表较长,压缩后放在附件里的。打开附件htbv_htc.txt把代码COPY到这就OK啦~
}
JAVA没的“指针”类型,操作N叉树只能用JAVA的数组。尽管制作的码表存放在数组内,“逻辑上”仍然用N叉树存放的,这样去看待它,就很容易理解这N叉哈夫曼树。
上一篇:(八)用JAVA编写MP3解码器——解码增益因子
下一篇:(十)用JAVA编写MP3解码器——逆量化和重排序
【本程序下载地址】http://jmp123.sourceforge.net/