Oracle Sql高级编程 第2章 SQL 执行过程
Oracle架构基础
实例由系统全局内存区域(
SGA)以及一系列的后台进程组成。每一个连接到数据库的用户都是通过一个客户端进程来进行管理的。客户端进程是与服务器进程相连接的。每个服务器进程都会被分配一块私有的内存区域,称为程序共享内存区域或进程共享内存区(
PGA)。
SGA-
共享池
共享池是内存中最关键的部分之一,特别是对于SQL的执行来说。你写SQL语句的方法并不仅仅会影响到这一句SQL本身。数据库中正在执行的所有SQL语句结合在一起会因为它们对共享池的影响而对总体性能和可扩展性带来巨大的影响。
共享池是Oracle缓存程序数据的地方。执行过的每一条SQL在共享池中都存有解析后的内存。共享池中存储这些语句的地方称为
库高速缓存。即在解析每一件SQL之前,Oracle都会检查库高速缓存看是否已经存在相同的语句。如果存在,Oracle会直接从缓存中读取而不是在解析一遍。
因为共享池大小有限。使用最近最少使用算法在更新共享池。
在写SQL语句时,需要牢记:为了更高的使用共享池,语句需要可以共享。
库高速缓存
执行每一条SQL时必然会发生的事就是它必须被解析并装载到库高速缓存中。解析包括验证语句的语法,验证提及的对象,以及确认该对象的用户权限。如果检查都通过,下一步就是看语句之前是否执行过。如果执行过,oracle 会使用之前解析的信息,这种类型的解析叫
软解析。如果语句之前没有被执行过,那边oracle就将执行所有的工作来为当前语句生成
执行计划,并将它放在缓存中以便以后使用。这种解析叫
硬解析。
硬解析比软解析要做很多很多的工作。
完全相同的语句
可以通过查询
v$sql视图来查看存放在库高速缓存中的语句。在执行一条sql时,会首先将字符串转换为散列值。所有语句必须
严格一致,才会得到相同的散列值。所以任何把变量拼接到sql中的方式,其实都会造成硬解析。
锁存器是Oracle为了读取存放在库高速缓存或其他内存结构中的信息时必须获得的一种锁。在读取库高速缓存中的任何信息之前,Oracle都会获得一个锁存器,其他所有会话都必须等待,直到该锁存器被释放。如果锁存器已经被使用,Oralce基本上将会迭代轮询(使用CPU资源),继续查看锁存器是否可用,知道一段时间之后(隐藏参数_spin_count指定的次数,默认2000次),该请求就会被暂停,然后排到其他请求之后。
SGA-
缓冲区缓存
在数据库块从硬盘中读取出来后或写入硬盘之前,用于存储数据库块。块是Oracle进行操作的最小单位。块中含有表数据行或索引条目。Oracle必须读取块来获得SQL语句需要的数据行。
总的来说 共享池中保存要执行SQL相关信息,缓冲区中保存实际的数据块。现在来看下硬解析,软解析,物理读取,逻辑读取究竟差多少。
SQL>
alter system set events 'immediate trace name flush_cache';
System altered.
SQL> alter system flush shared_pool;
System altered.
SQL> set autotrace traceonly statistics
System altered.
SQL> alter system flush shared_pool;
System altered.
SQL> set autotrace traceonly statistics
SQL> select * from sysadm.ps_job;
Statistics
----------------------------------------------------------
5581 recursive calls
0 db block gets
1868 consistent gets
35 physical reads
0 redo size
12977 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
6 sorts (memory)
0 sorts (disk)
1 rows processed
Statistics
----------------------------------------------------------
5581 recursive calls
0 db block gets
1868 consistent gets
35 physical reads
0 redo size
12977 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
6 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> set autotrace off
QL> alter system set events 'immediate trace name flush_cache';
System altered.
SQL> set autotrace traceonly statistics
SQL> select * from sysadm.ps_job;
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
7 consistent gets
6 physical reads
0 redo size
12977 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
System altered.
SQL> set autotrace traceonly statistics
SQL> select * from sysadm.ps_job;
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
7 consistent gets
6 physical reads
0 redo size
12977 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> select * from sysadm.ps_job;
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
7 consistent gets
0 physical reads
0 redo size
12977 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
7 consistent gets
0 physical reads
0 redo size
12977 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
查询转换
该步骤发生在一个查询进行完语法和权限检查后,优化器为了决定最终的执行计划而为不同的计划计算成本之前。
查询会被转换为一系列查询块。查询块是通过SELECT关键字定义的。例如 select * from employees 只有一个查询块,而select * from employees where deptid in (select deptid from departments) 有2个查询块。
查询转换的目的是确定如果改变查询的写法会不会有更好的执行计划。所以,
查询转换可能会重新查询。
查询转换器可能会改变最初所写的查询结构,只要不会影响结果集。最常进行的改变就是将独立的查询块转换为直接联结。例如 上面 带 IN 的查询会被转换为联结。
可以通过查看执行计划来了解是否发生了查询转换。也可以通过
NO_QUERY_TRANSFORMATION提示,禁止查询转换(除了条件前推)。
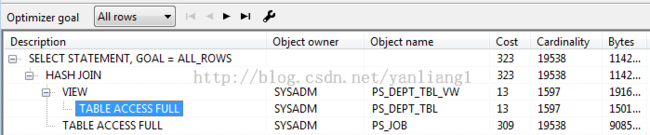
视图合并
视图合并是一种能将内嵌或存储式视图展开为能够独立分析或者与查询剩余部分合并成总体执行计划的查询转换。改写后的语句基本上不包含视图。转换后的查询将会由优化器进行复查,优化器会选择成本最低的执行计划。
例如:
SELECT
*
FROM
PS_JOB A, PS_DEPT_TBL_VW B
WHERE
A.DEPTID = B.DEPTID
AND
A.SETID_DEPT = B.DEPTID;

SELECT
/*+ NO_QUERY_TRANSFORMATION */
*
FROM
PS_JOB A, PS_DEPT_TBL_VW B
WHERE
A.DEPTID = B.DEPTID
AND
A.SETID_DEPT = B.DEPTID
子查询解嵌套
子查询位于WHERE子句,最典型的转换是将子查询转变为表联结。如果子查询没有解嵌套,将会作为独立的子计划
SELECT
*
FROM
PS_JOB A
WHERE
A.BUSINESS_UNIT
IN
(
SELECT
BUSINESS_UNIT
FROM
PS_BUS_UNIT_TBL_HR)

SELECT
*
FROM
PS_JOB A
WHERE
A.BUSINESS_UNIT
IN
(
SELECT
/*+NO_UNNEST*/
BUSINESS_UNIT
FROM
PS_BUS_UNIT_TBL_HR)
SELECT STATEMENT, GOAL = ALL_ROWS 309 19538 9085170
FILTER EXISTS (SELECT /*+ NO_UNNEST */ 0 FROM "PS_BUS_UNIT_TBL_HR" "PS_BUS_UNIT_TBL_HR" WHERE "BUSINESS_UNIT"=:B1)
TABLE ACCESS FULL SYSADM PS_JOB 309 19538 9085170
INDEX UNIQUE SCAN SYSADM PS_BUS_UNIT_TBL_HR 0 1 5 "BUSINESS_UNIT"=:B1
FILTER EXISTS (SELECT /*+ NO_UNNEST */ 0 FROM "PS_BUS_UNIT_TBL_HR" "PS_BUS_UNIT_TBL_HR" WHERE "BUSINESS_UNIT"=:B1)
TABLE ACCESS FULL SYSADM PS_JOB 309 19538 9085170
INDEX UNIQUE SCAN SYSADM PS_BUS_UNIT_TBL_HR 0 1 5 "BUSINESS_UNIT"=:B1
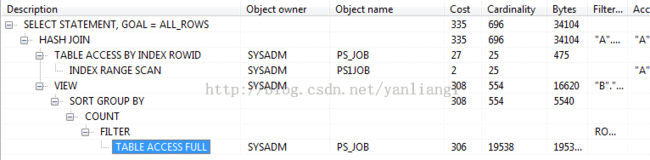
2种执行计划的主要区别是不进行子查询解嵌套将会选用
FILTER运算而不是
NESTED LOOPS连接。要注意FILTER 运算是比较低效的,会对主查询的每一条记录都执行一次子查询。因为ORACLE使用一种称为子查询缓存的优化功能,这2种的效率不好说,但是一般来说应避免FILTER 运算。
条件前推
条件前推用来将条件从一个内含查询块中应用到不可合并的查询块中。目的就是允许索引的使用或者让对数据集的筛选尽早的进行。
SELECT
A.EMPLID, A.COMPRATE, B.AVG_CM
FROM
PS_JOB A,
(
SELECT
C.DEPTID,
AVG
(C.COMPRATE) AVG_CM
FROM
PS_JOB C
GROUP
BY
C.DEPTID) B
WHERE
A.DEPTID = B.DEPTID
AND
A.COMPRATE > B.AVG_CM
AND
A.DEPTID =
'100001'

SELECT
A.EMPLID, A.COMPRATE, B.AVG_CM
FROM
PS_JOB A,
(
SELECT
C.DEPTID,
AVG
(C.COMPRATE) AVG_CM
FROM
PS_JOB C
WHERE
ROWNUM > 1
GROUP
BY
C.DEPTID) B
WHERE
A.DEPTID = B.DEPTID
AND
A.COMPRATE > B.AVG_CM
AND
A.DEPTID =
'100001'
我们使用
rownum
伪列可以禁止谓词前推,事实上,rownum也会禁止视图合并。使用rownum如同加入了
NO_MERGE和
NO_PUSH_PRED提示。要注意rownum的影响
使用物化视图进行查询重写
查询重写是一种发生在当一个查询或查询的一部分已经被保存为一个物化视图,转换器重写该查询已使用预先计算好的物化视图。
选定执行计划
执行计划就是Oracle 访问你的查询所使用的对象并返回相应结果数据将会采用的一系列步骤。oracle确定执行计划所用到的最关键的信息之一就是
统计信息。可以针对对象收集统计信息,也可以收集系统统计信息。
来看下统计信息:
SQL> @st-all
PL/SQL procedure successfully completed
Session altered
===================================================================================================================================
TABLE STATISTICS
===================================================================================================================================
Owner : sysadm
Table name : ps_bus_unit_tbl_hr
Tablespace : pyapp
Cluster name :
Partitioned : no
Last analyzed : 07/04/2012 17:45:51
Sample size : 2
Degree : 1
IOT Type :
IOT name :
# Rows : 2
# Blocks : 5
Empty Blocks : 0
Avg Space : 0
Avg Row Length: 61
Monitoring? : yes
PL/SQL procedure successfully completed
PL/SQL procedure successfully completed
PARTI PARTITION_NAME SAMPLE_SIZE NUM_ROWS BLOCKS HIGH_VALUE LAST_ANALYZED
----- ------------------------------ ----------- ---------- ---------- -------------------------------------------------------------------------------- -------------
===================================================================================================================================
COLUMN STATISTICS
===================================================================================================================================
Name Analyzed Null? NDV Density # Nulls # Buckets Sample AvgLen Lo-Hi Values
===================================================================================================================================
active_inactive 05/25/2012 22:00:36 N 1 1.000000 0 1 1 2 A | A
business_unit 07/04/2012 17:45:51 N 2 .500000 0 1 2 5 1 | 1
business_unit_am 05/25/2012 22:00:36 N 1 1.000000 0 1 1 2 |
business_unit_ap 05/25/2012 22:00:36 N 1 1.000000 0 1 1 2 |
business_unit_ar 05/25/2012 22:00:36 N 1 1.000000 0 1 1 2 |
business_unit_bal 05/25/2012 22:00:36 N 1 1.000000 0 1 1 2 |
business_unit_bd 05/25/2012 22:00:36 N 1 1.000000 0 1 1 2 |
business_unit_bi 05/25/2012 22:00:36 N 1 1.000000 0 1 1 2 |
business_unit_dup 05/25/2012 22:00:36 N 1 1.000000 0 1 1 2 |
business_unit_gl 05/25/2012 22:00:36 N 1 1.000000 0 1 1 2 |
business_unit_in 05/25/2012 22:00:36 N 1 1.000000 0 1 1 2 |
business_unit_om 05/25/2012 22:00:36 N 1 1.000000 0 1 1 2 |
business_unit_pc 05/25/2012 22:00:36 N 1 1.000000 0 1 1 2 |
business_unit_po 05/25/2012 22:00:36 N 1 1.000000 0 1 1 2 |
default_setid 05/25/2012 22:00:36 N 1 1.000000 0 1 1 6 1 | 1
descr 07/04/2012 17:45:51 N 2 .500000 0 1 2 15 1| 1
descrshort 05/25/2012 22:00:36 N 1 1.000000 0 1 1 10 1 | 1
PL/SQL procedure successfully completed
PL/SQL procedure successfully completed
===================================================================================================================================
INDEX INFORMATION
===================================================================================================================================
PL/SQL procedure successfully completed
Cannot SET NULL
INDEX_NAME BLEVEL LEAF_BLOCKS NUM_ROWS DISTINCT_KEYS AVG_LEAF_BLOCKS_PER_KEY AVG_DATA_BLOCKS_PER_KEY CLUSTERING_FACTOR SAMPLE_SIZE UNIQU INDEX_TY STATUS DEG PARTI VISI LAST_ANALYZED
------------------------------ ------ ----------- ---------- ------------- ----------------------- ----------------------- ----------------- ----------- ----- -------- -------- --- ----- ---- -------------
PS0BUS_UNIT_TBL_HR 0 1 2 2 1 1 1 2 NO NORM VALID 1 NO 2012-07-04 17
PS_BUS_UNIT_TBL_HR 0 1 2 2 1 1 1 2 YES NORM VALID 1 NO 2012-07-04 17
INDEX_NAME COLUMN_PO DESCE COLUMN_NAME
------------------------------ --------- ----- ------------------------------
ps0bus_unit_tbl_hr 1 ASC descr
ps0bus_unit_tbl_hr 2 ASC business_unit
ps_bus_unit_tbl_hr 1 ASC business_unit
PL/SQL procedure successfully completed
INDEX_NAME PARTI PARTITION_NAME BLEVEL LEAF_BLOCKS NUM_ROWS DISTINCT_KEYS AVG_LEAF_BLOCKS_PER_KEY AVG_DATA_BLOCKS_PER_KEY CLUSTERING_FACTOR STATUS LAST_ANALYZED HIGH_VALUE
------------------------------ ----- ------------------------------ ---------- ----------- ---------- ------------- ----------------------- ----------------------- ----------------- -------- ------------- ------------------------------------------------------------------------------------------------------------------------
第一组统计信息是
表统计信息。这些值可以从
all_tables(或dba_tables,user_tables)视图中得到.
第二组是列统计信息,可以从
all_tab_cols中的到,注意
NDV
信息表示本列有多少个不同的数据。每个数据出现的概率相同。
优化器基于统计信息计算每种执行计划所花费的时间,如果统计信息已经过时或缺失,那就会影响执行计划的选择。
执行并取得数据行
一个执行计划就是告诉Oracle对于每一个表对象使用哪种访问方法。执行计划中的每个步骤产生一个行源,然后与另一个行源相联结,直到所有的对象都被访问和联结。对于结果集,需要返回的数据行很可能都不是在一次往返的过程中传递给应用的。
当执行一个SQL查询,是由一系列单独执行的调用完成的。查询将会完成解析,绑定,执行,提取的步骤。在一个查询过程中可能有多个提取调用,每次返回满足查询结果所需的一部分数据行。
每次调用客户端和数据库之间的网络往返回路将会影响语句总的响应时间。每次访问数据块时,oracle会从块中取出数据行然后在一次回路中返回给客户端。 一次返回的行数是一个可配置的值称为列大小。SQLPLUS中的默认列大小为15,可以通过
SET ARRAYSIZE n
设置。JDBC的默认值是10,可以使用
((OracleConnection)conn).setDefaultRowPrefetch(n)设置。较大的值可以减少网络往返。
来看下对逻辑读取的影响
SQL> set arraysize 15
SQL> set autotrace traceonly statistics
SQL> select * from sysadm.ps_gp_pin;
44585 rows selected.
Statistics
----------------------------------------------------------
1324 recursive calls
0 db block gets
44887 consistent gets
1551 physical reads
0 redo size
27361965 bytes sent via SQL*Net to client
13534683 bytes received via SQL*Net from client
75242 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
44585 rows processed
SQL> set autotrace traceonly statistics
SQL> select * from sysadm.ps_gp_pin;
44585 rows selected.
Statistics
----------------------------------------------------------
1324 recursive calls
0 db block gets
44887 consistent gets
1551 physical reads
0 redo size
27361965 bytes sent via SQL*Net to client
13534683 bytes received via SQL*Net from client
75242 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
44585 rows processed
SQL> set arraysize 50
SQL> /
44585 rows selected.
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
44623 consistent gets
1536 physical reads
0 redo size
27361965 bytes sent via SQL*Net to client
13534683 bytes received via SQL*Net from client
75242 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
44585 rows processed
SQL> /
44585 rows selected.
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
44623 consistent gets
1536 physical reads
0 redo size
27361965 bytes sent via SQL*Net to client
13534683 bytes received via SQL*Net from client
75242 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
44585 rows processed
注意:在实验中,不知道为什么,网络往返没有减少。