Stored Procedure 里的 WITH RECOMPILE 到底是干麻的?
在 SQL Server 创建或修改「存储过程(stored procedure)」时,可加上 WITH RECOMPILE 选项,但多数文档或书籍都写得语焉不详,或只解释为「每次执行此存储过程时,都要重新编译」。事实上,是指执行此一存储过程时,要强制重新产生「执行计划(execution plan)」,而不要从「缓存(cache)」去取得旧的「执行计划」。
SQL Server 在评估与产生「执行计划」时,非常耗 CPU 资源,因此,如何让其正确地从 cache 中,重复使用旧的「执行计划」就很重要;但是,若误用旧的「执行计划」,导致 SELECT 查询的性能大幅下降,则更得不偿失。
一般的 SQL 查询,两次或多次执行的 SQL 语句中,内容必须完全符合,才能延用旧的「执行计划」,包含: 大小写、换行、空白。如下图 1,因为两次执行的 SQL 语句,差了一个「半形空格」,导致产生了两次「执行计划」,而无法重复使用旧的「执行计划」。
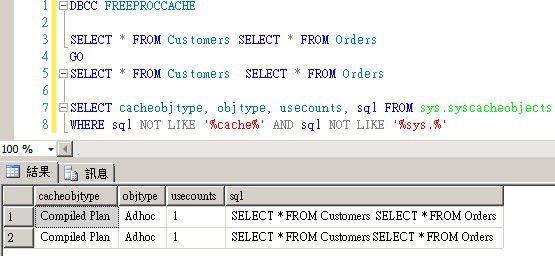
图 1 浪费资源产生了两次「执行计划」
1 DBCC FREEPROCCACHE 2 3 SELECT * FROM Customers SELECT * FROM Orders 4 GO 5 SELECT * FROM Customers SELECT * FROM Orders 6 7 SELECT cacheobjtype, objtype, usecounts, sql FROM sys.syscacheobjects 8 WHERE sql NOT LIKE '%cache%' AND sql NOT LIKE '%sys.%'
若是改用「参数化查询」,如下 :
SELECT * FROM Customers WHERE CustomerID=@CustomerID
即可避免因参数值不同,一直产生新的「执行计划」,亦可避免 SQL Injection 攻击。
而存储过程,相对于一般 SQL 语句,其在性能上的优势,除了已事先编译外,存储过程也可提升「执行计划」的重用性(复用性),避免产生新的「执行计划」、消耗 CPU 资源。如下图 2,两次调用同一个存储过程时,但传入不同的参数,SQL Server 会重复使用同一个「执行计划」,如同上述的「参数化查询」一样,不会浪费资源产生新的「执行计划」。

图 2 「执行计划」被重复使用,避免浪费资源
1 CREATE PROC spCust1 @CustID NVARCHAR(5) 2 AS 3 SELECT * FROM dbo.Customers 4 WHERE CustomerID=@CustID 5 GO 6 7 EXEC spCust1 'ALFKI' 8 EXEC spCust1 'BERGS' 9 10 --DBCC FREEPROCCACHE 11 SELECT cacheobjtype, objtype, usecounts, sql FROM sys.syscacheobjects 12 WHERE sql NOT LIKE '%cache%' AND sql NOT LIKE '%sys.%'
但若存储过程「数据内容分布不平均」,例如某个 Table,里面有个 Int 类型的字段,大量记录里所存储的值依序为 1~100,但只有某一条记录存的是 10000。亦即符合过滤条件的记录有时极多 (「执行计划」适合用「索引扫描」),但有时符合的只有一两条 (「执行计划」适合用「索引查找」)。而未来在调用此存储过程时,两种情境都有可能出现,因此我们希望此一存储过程,在执行时「不要 cache 执行计划」,亦即让此存储过程在每次执行时,都重新评估、产生最适当的「执行计划」,此时就可加上 WITH RECOMPILE 选项。或者如下图 3,丢给前端应用程序去决定,亦即 AP 在调用此存储过程时,再决定是否加上 WITH RECOMPILE 参数。

图 3
1 Exec select_Proc1 @Key1=5 --自動選用高效能的「執行計畫」 2 Exec select_Proc1 @Key1=10000 --從 cache 延用舊的「執行計畫」,因不適用,反而導致效能不佳 3 Exec select_Proc1 @Key1=10000 WITH RECOMPILE --強制重新產生新的、高效能「執行計畫」
还有其他进阶的选项应用,像是可以在创建存储过程时,使用 OPTIMIZE FOR 选项,只针对特定某一个参数值来做 cache,来产生固定一种、平均对性能影响最小的「执行计划」,又能避免一直重复产生新的「执行计划」而浪费 CPU 资源。
案例分析 - 同样的语法在存储过程内跑很慢,单独跑很快 (胡百敬, 繁体中文) :
http://byronhu.wordpress.com/2010/07/15/with-recompile/
引用该文部分内容 :
朋友问了一个有趣的问题:同样的语句,在存储过程内跑很慢,单独跑很快。
存储过程会缓存执行计划 (若未加上 WITH RECOMPILE),一般来说可以省掉 CPU 耗费。但若两次执行此存储过程的期间,所引用的记录数量差异很大,则第二次执行时沿用旧的执行计划,性能会变得很差。可以观察以下现象:
- 观察执行后的执行计划,传回大量记录却是用「索引查找」。
- 透过 Profiler 观察存储过程内的语法,和单独执行的语法,所耗的 IO/CPU/Duration 的数值。若将某句的语法单独拿到 Management Studio 执行的性能,远好于该句语法在存储过程内执行,就有可能是上述原因。
简单的解法,是在执行或创建存储过程时,搭配 WITH RECOMPILE 选项。
...中间略...
存储过程的执行情境可以分 80-20 定律,若少数执行状况 AP 自己知道,则 AP 可以判读是否要下 with recompile 或是撰写存储过程直接搭配 Option(Optimize for (参数定义))
但在一些状况,例如使用者下 Range 查询,或是「财务滚算」数据,会大量删除、插入中继表内的数据,developer 无法预先评估可能的数据量大小,则在存储过程创建时,直接搭配 with recompile,可得到较稳定的执行性能。
结语: 我自己早年写 AP 时,一直查不到 WITH RECOMPILE 是干麻的,当时我写用来「分页(换页)」的存储过程时 (双 TOP 夹击、或 ROW_NUMBER 函数),就一律加上 WITH RECOMPILE 选项。现在回想起来,其实是不必加的,因为重复用旧的「执行计划」即可 (可节省许多数据库伺服器上的资源),丢入的参数也都差不多 (用户目前所在页数、每页要传回几条记录)。
1 CREATE PROCEDURE [dbo].[GridView_pager] 2 @StartRowIndex int, 3 @PageSize int, 4 @tableName nvarchar(50), 5 @columnName nvarchar(100), 6 @sqlWhere nvarchar(1000), 7 @groupBy nvarchar(100), 8 @orderBy nvarchar(100), 9 @rowCount int output 10 WITH RECOMPILE 11 AS
相关文章 :
谈一谈 SQL Server 中的执行计划缓存
http://www.cnblogs.com/CareySon/archive/2013/05/04/3058592.html
http://www.cnblogs.com/CareySon/archive/2013/05/04/PlanCacheInSQLServerPart2.html