编写自己的sniffer(一)
一、系统环境

借助官方的API快速开发链路层->IP层->TCP层->HTTP层的协议解析,这样下来就有了很清楚的路线和理解,其他协议的分析就比较简单、明了了。
三、核心数据结构(Hash)
考虑到应用层协议识别的对象不是以单个报文为单位,而是将流作为一个整体考虑。以此为目的,要对数据流进行协议识别,首先需要对
网络数据包做分流处理。流表操作的性能,将直接影响整个系统的性能。流表通过对网络流数据包的五元组信息(源IP地址、目的IP地址、源端口、
目的端口、协议号)进行解析,对五元组信息进行哈希计算,按照哈希值将数据包分为不同的流,从而达到对数据包分流的目的。分流后,将每个
流的基本信息保存在流表中,为应用层协议识别等提供数据支持。
1、流表的设计
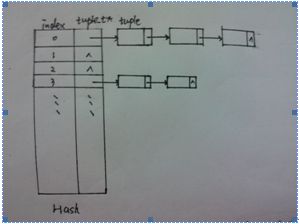
2、流表的处理流程

3、hash设计和计算
h(key)=((源端口号& 0xff) |((目的端口号&0xff) << 8) |((源IP地址& 0xff) << 16) |((目的IP地址& 0xff) << 24)) % HASH_SIZE ;
很容易想到同一个流有两个方向,所以为了提高效率,先将五元组按照IP地址和端口号大小进行排序,这里规定最终的顺序为:小口地址、大IP地址、小端口号、大端口号、协议号。因此,同一个流的两个方向只需要计算一次hash值,提高了效率。除TCP、UDP外,其它协议的端口号规定为零。
四、流量统计
主要用于将系统运行过程中统计出的ip数据包的数量、长度、当前识别流的总数量、被识别出每种应用层协议数据包的个数、数据量的大小、
流的个数等信息实时的进行统计。统计模块主要划分为以下几个部分:全局信息统计、流表信息统计、协议信息统计。
统计模块:
将系统运行过程中统计出的ip数据包的数量、长度、当前识别流的总数量、被识别出每种应用层协议数据包的个数、数据量的大小、流的
个数等信息实时的进行统计。将统计模块主要划分为以下几个部分:全局信息统计、流表信息统计、协议信息统计。
全局信息统计
全局信息统计主要包括收包数目、发包数目,IP包数目、非lP包数目、TCP包数目、UDP包数目等在进入流表之前通过分析五元组就可以获得
的和数据包相关的统计信息。
流表的信息统计
主要统计流的数量,如:建立流的数量、已结束流的数量、TCP流的个数、UDP流的个数等。
协议统计信息
此处统计只在流删除时进行,当删除流时,触发统计机制,从而将此流的相关信息记录在相应的协议信息统计位置。
全局信息、流表信息、协议信息的统计时机
主要分为以下三点:
l、分析出五元组并进入流表之前。主要统计全局信息,例如收发包数目、IP包数目、TCP包数目等信息。
2、流表建立时刻。统计建立流表数目、TCP流表数目、UDP流表数目等信息。
3、流表结束时刻。统计完成流表数目、协议相关统计等信息。
五、上行/下行速率计算
1、首先是抓包时间的计算,我们要用的应该是网卡抓包时的时间戳,而不是系统时间,否则会有误差。pcap_loop调用的回调函数的第二个参数
struct pcap_pkthdr可以获取该时间戳。每次调用回调函数时保存上一次的时间,相邻两次相减就是传输时间。
2、为了提高计算的准确性,总数据量在链路层统计,而不是网络层,这样就需要获取本地Mac地址,并对数据帧的目的Mac和本地Mac比较确定
是上传还是下载数据包。
可以参考:http://blog.csdn.net/fengyun1989/article/details/7384879的策略。
以下是一些流量统计(IP包数、丢包率、上行/下行平均速率等)的运行结果:
