溢出攻击
缓冲区溢出
介绍
缓冲区溢出是指当计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上。
缓冲区:是一块连续的计算机内存区域,可以保存相同数据类型的多个实例。
堆 栈:是一个在计算机科学中经常使用的抽象数据类型。后进先出。PUSH操作在堆栈的顶部加入一个元素。POP操作相反,在堆栈顶部移去一个 元素,并将堆栈的大小减一。
CPU的ESP寄存器存放当前线程的栈顶指针
EBP寄存器中保存当前线程的栈底指针。
CPU的EIP寄存器存放下一个CPU指令存放的内存地址,当CPU执行完当前的指令后,从EIP寄存器中读取下一条指令的内存地址,然后继续执行。
shellcode,实际上是十六进制形式的机器语言,大家知道机器语言是二进制的,CPU只认识二进制,因为要被直接注入到内存中,没办法编译了,所以希望CPU可以执行,那就只能用机器代码了,一般用汇编语言写出程序,在从目标代码中提取出。十六进制和二进制是和容易转换的。
为什么叫shellcode,我想可能是因为它可以启动一个shell(命令解释程序)。也就是可以与system交互了,可以操作系统了。
危害
缓冲区溢出中,最为危险的是堆栈溢出,因为入侵者可以利用堆栈溢出,在函数返回时改变返回程序的地址,让其跳转到任意地址,带来的危害一种是程序崩溃导致拒绝服务,另外一种就是跳转并且执行一段恶意代码,比如得到shell,然后为所欲为。
我们将一段恶意代码通过漏洞插入到程序正常的代码当中,由于代码长度是固定的,这段代码会有一部分正常代码被溢出,也就是说我们的恶意代码代替了正常的程序代码。在程序要调用这段代码的时候,它会将我们插入的恶意代码当作正常代码调用,这时溢出攻击就完成了。这段恶意代码可实现的作用是任意的,例如提升用户权限、造成程序崩溃等等。
攻击
通过往程序的缓冲区写超出其长度的内容,造成缓冲区的溢出,从而破坏程序的堆栈,使程序转而执行其它指令,以达到攻击的目的。造成缓冲区溢出的原因是程序中没有仔细检查用户输入的参数。例如下面程序:
void function(char *str) {
char buffer[16]; strcpy(buffer,str);
}
上面的strcpy()将直接把str中的内容copy到buffer中。这样只要str的长度大于16,就会造成buffer的溢出,使程序运行出错。存在像strcpy这样的问题的标准函数还有strcat()、sprintf()、vsprintf()、gets()、scanf()等。
最常见的手段是通过制造缓冲区溢出使程序运行一个用户shell,再通过shell执行其它命令。如果该程序属于root且有suid权限的话,攻击者就获得了一个有root权限的shell,可以对系统进行任意操作了。
攻击者必须达到如下的两个目标:
有两种在被攻击程序地址空间里安排攻击代码的方法:
1、植入法
2、利用已经存在的代码
char buffer1[5];
char buffer2[10];
}
void main() {
function(1,2,3);
}
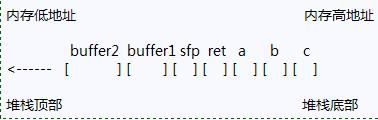
堆溢出
堆是内存的一个区域,它 被应用程序利用并在运行时被动态分配。堆内存与堆栈内存的不同在于它在函数之间更持久稳固。这意味着分配给一个函数的内存会持续保持分配直到完全被释放为 止。这说明一个堆溢出可能发生了但却没被注意到,直到该内存段在后面被使用。

格式化字符串
这类错误是指使用printf,sprintf,fprint等函数时,没有使用格式化字符串,比如:正确用法是:
如果直接写成:
将会出现漏洞,当input输入一些非法制造的字符时,内存将有可能被改写,执行一些非法指令。
如果不提供参数,prinf将从stack里获取值。
Below are some format parameters which can be used and their consequences:
•"%x" Read data from the stack (stack里存着memory address),读取stack里的内容,如”0x08047458“
•"%s" Read character strings from the process' memory,如显示address为0x08047458的memory内的内容
•"%n" Write an integer to locations in the process' memory,把前面参数的数量写入位置。如修改address为0x08047458的memory内的内容。
如:printf("hi%n",&x)——————x=2
例如:
printf ( “Buffer size is: (%d) \nData input: %s \n” , strlen (buf) , buf ) ;
当输入为Bob时,输出正常: Buffer size is (16) Data input : Bobprintf ( “Buffer size is: (%d) \n Data input: Bob %x %x \n” , strlen (buf) , buf )
输出:Buffer size is (27) Data input : Bob bffff 8740【stack里的值】
If the format string parameter “%x %x” is inserted in the input string, when the format function parses the argument, the output will display the name Bob, but instead of showing the %x string, the application will show the contents of a memory address. 【%x打出stack的内容——memory address】
2. DOS
printf (userName);
printf (%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s);
当地址不存在,程序就会崩溃。
The attacker could insert a sequence of format strings, making the program show the memory address where a lot of other data are stored, then, the attacker increases the possibility that the program will read an illegal address, crashing the program and causing its non-availability.
https://www.owasp.org/index.php/Format_string_attack
3. 改写
printf的%n格式化说明符它允许向后面一个存储单元写入前面输出数据的总长度,那么只 要前面输出数据的长度(这个长度的控制可以利用格式化说明符的特性,比如%.200d,这样我们就可以控制输 出数据长度为200了,想象一下如果我们用%f.呢?嗬嗬,堆栈地址固然很大,但是我们应该可以构造足够的 %f....用来到达我们需要改写的存储单元)等于我们需要程序跳转到的那个地址(通常是shellcode+nop的区域),而%n恰到好处的将这一地址写入适当位置,那么我们就可以按照我们的意愿改变程序流程了.:) 不过这里有一点需要注意,如果格式化字符串攻时覆盖函数的返回地址,那么实际上我们是去覆盖存储 这个函数返回地址的那块存储空间.也就是说我们是间接的覆盖.这一点很重要,不能混淆.回想一下C语言的指 针。
格式化字符串攻击中覆盖函数返回地址通常有两种选择:1.覆盖临近的一个函数(调用该函数的函数,比如main())的 返回地址.2.覆盖*printf()系列函数自身的返回地址.在这个例子中,两种方式都作了简单分析,并且给出覆盖*prinf()系列函数自身返回地址的Exploit,这样当这个函数执行完毕返回的时候,就可以按照我们的意愿改变程序的流程了.
我们需要知道以下几个信息:
1.堆栈中存储函数的返回地址的那个存储单元的地址.
2.shellcode的地址
如:
找位置
% ./fmtme "aaaa %x %x"
buffer (15): aaaa 1 61616161
x is 1/0x1 (@ 0x804745c)
说明stack内第一个是存的x的值,第二个是我们输入的值
【一般要寻找几个%x,这里恰好是第二个】
所以利用这一点
% perl -e 'system "./fmtme", "\x58\x74\x04\x08 %d %n"'
buffer (5): X1
x is 5/x05 (@ 0x8047458)
"\x58\x74\x04\x08%d%n" (x, 我们写的地址)
将"\x58\x74\x04\x08“存入buf,跳过x,遇到%n指令 。这个指令从栈堆中取出下一个值,将5写入buf里的内容指向的address(buf此时为0x08047458,则将5写入0x08047458的memory,也就是x的所在地)
另:
打印出制定location的值
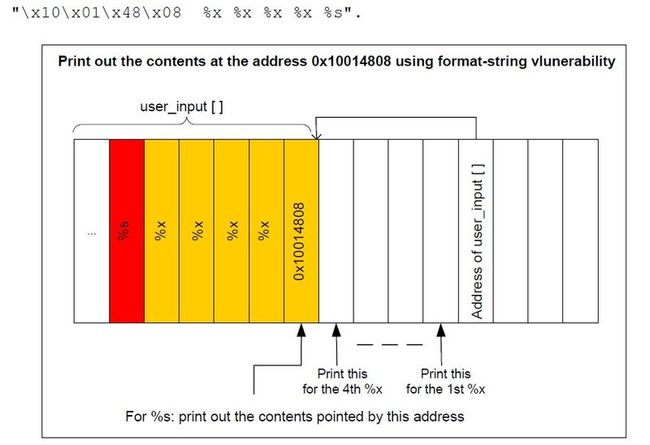
改写任意location的值
将上面的%s换成%n
防御:
1. 避免使用不安全的字符串处理函数,比如使用安全的函数代替:
| 不安全的函数 |
安全函数 |
| strcpy |
strncpy |
| strcat |
strncat |
| sprintf |
_snprintf |
| gets |
fgets |