HTMLParser1.6 源代码阅读
HTMLParser1.6 源代码阅读
看到博客园的大牛们都喜欢发系列的文章,我也发一篇。不过我不打算写什么spring hibernate配置什么的,我只想写写自己阅读别人代码的一些笔记。欢迎大家拍砖。
从开始进行阅读,第一个包是:org.htmlparser.里面的类包括
Attribute.java
Node.java
NodeFactory.java
NodeFilter.java
Parser.java
PrototypicalNodeFactory.java
Remark.java
Tag.java
Text.java
可以看出都是针对基本数据结构的类。
一个一个进行分析,Attribute.java是记录网页元素的属性的,
<a href="EditPosts.aspx" id="TabPosts">随笔</a>
这个是博客园的,那Attribute应当可以记录 href=“MySubscibe.aspx"这样的元素。看他的构造方法:
public Attribute (String name, String assignment, String value, char quote) { setName (name); setAssignment (assignment); if (0 == quote) setRawValue (value); else { setValue (value); setQuote (quote); } }
看见分为是否含有引号的情况。setName,和setValue没有什么可以看的,如果不含引号的情况,value怎么设置
/** * Set the value of the attribute and the quote character. * If the value is pure whitespace, assign it 'as is' and reset the * quote character. If not, check for leading and trailing double or * single quotes, and if found use this as the quote character and * the inner contents of <code>value</code> as the real value. * Otherwise, examine the string to determine if quotes are needed * and an appropriate quote character if so. This may involve changing * double quotes within the string to character references. * @param value The new value. * @see #getRawValue * @see #getRawValue(StringBuffer) */ public void setRawValue (String value) { char ch; boolean needed; boolean singleq; boolean doubleq; String ref; StringBuffer buffer; char quote; quote = 0; if ((null != value) && (0 != value.trim ().length ())) { if (value.startsWith ("'") && value.endsWith ("'") && (2 <= value.length ())) { quote = '\''; value = value.substring (1, value.length () - 1); } else if (value.startsWith ("\"") && value.endsWith ("\"") && (2 <= value.length ())) { quote = '"'; value = value.substring (1, value.length () - 1); } else { // first determine if there's whitespace in the value // and while we're at it find a suitable quote character needed = false; singleq = true; doubleq = true; for (int i = 0; i < value.length (); i++) { ch = value.charAt (i); if ('\'' == ch) { singleq = false; needed = true; } else if ('"' == ch) { doubleq = false; needed = true; } else if (!('-' == ch) && !('.' == ch) && !('_' == ch) && !(':' == ch) && !Character.isLetterOrDigit (ch)) { needed = true; } } // now apply quoting if (needed) { if (doubleq) quote = '"'; else if (singleq) quote = '\''; else { // uh-oh, we need to convert some quotes into character // references, so convert all double quotes into " quote = '"'; ref = """; // Translate.encode (quote); // JDK 1.4: value = value.replaceAll ("\"", ref); buffer = new StringBuffer ( value.length() * (ref.length () - 1)); for (int i = 0; i < value.length (); i++) { ch = value.charAt (i); if (quote == ch) buffer.append (ref); else buffer.append (ch); } value = buffer.toString (); } } } } setValue (value); setQuote (quote); }
如果没有设置分割字符的话,需要进行判断,首先判断value的字符是哪种?单引号,双引号,还是其他。如果是单引号开头,单引号结尾,那么分割是单引号。如果是双引号,就是双引号。如果不是这样,可能需要修复,如果里面有单引号,那么我们用双引号进行包装,里面含有双引号,我们用单引号进行包装。或者其中含有一些特别的字符(不是数字,字符,-,_,:),我们需要用引号引用起来。这样属性就可以保存下来。
属性暂时分析到这里,有兴趣的可以自己阅读剩下的部分。
Node.java
其实htmlParser就是一个词法语法分析器,学过自动机的同学应当对此很熟悉,(ps,本人自动机挂掉了。。)而HTML的元素有三种类型,text,Tag,Remark(remark是不是这种<!--ddd-->,这个不确定)。 我们进行语法解析的时候肯定要返回相应的node,那这个node应当设计成抽象类或者接口,的确,也是这样设计的。看代码
package org.htmlparser; import org.htmlparser.lexer.Page; import org.htmlparser.util.NodeList; import org.htmlparser.util.ParserException; import org.htmlparser.visitors.NodeVisitor; public interface Node extends Cloneable { String toPlainTextString (); String toHtml (); String toHtml (boolean verbatim); String toString (); void collectInto (NodeList list, NodeFilter filter); int getStartPosition (); void setStartPosition (int position); int getEndPosition (); void setEndPosition (int position); Page getPage (); void setPage (Page page); void accept (NodeVisitor visitor); Node getParent (); void setParent (Node node); NodeList getChildren (); void setChildren (NodeList children); Node getFirstChild (); Node getLastChild (); Node getPreviousSibling (); Node getNextSibling (); String getText (); void setText (String text); void doSemanticAction () throws ParserException; Object clone () throws CloneNotSupportedException; }
这里光看这个也没办法领略精髓,大致就是一个开始克隆,可以转换成html元素,转换成string的类型,并且可以迭代的一系列方法。不过下一步我们应当从lexer中寻找相关答案,保持我们的阅读顺序,我们继续进行下一个java分析
NodeFactory
先看代码
package org.htmlparser; import java.util.Vector; import org.htmlparser.lexer.Page; import org.htmlparser.util.ParserException; public interface NodeFactory { Text createStringNode (Page page, int start, int end) throws ParserException; Remark createRemarkNode (Page page, int start, int end) throws ParserException; Tag createTagNode (Page page, int start, int end, Vector attributes) throws ParserException; }
就是创建上面三种HTML页面的基本元素。
NodeFilter
package org.htmlparser; import java.io.Serializable; /** * Implement this interface to select particular nodes. */ public interface NodeFilter extends Serializable, Cloneable { boolean accept (Node node); }
进行一个Node的合理性验证
Parser
终于看到重点了
package org.htmlparser; import java.io.Serializable; import java.net.HttpURLConnection; import java.net.URLConnection; import org.htmlparser.filters.TagNameFilter; import org.htmlparser.filters.NodeClassFilter; import org.htmlparser.http.ConnectionManager; import org.htmlparser.http.ConnectionMonitor; import org.htmlparser.http.HttpHeader; import org.htmlparser.lexer.Lexer; import org.htmlparser.lexer.Page; import org.htmlparser.util.DefaultParserFeedback; import org.htmlparser.util.IteratorImpl; import org.htmlparser.util.NodeIterator; import org.htmlparser.util.NodeList; import org.htmlparser.util.ParserException; import org.htmlparser.util.ParserFeedback; import org.htmlparser.visitors.NodeVisitor; public class Parser implements Serializable, ConnectionMonitor { public static final double VERSION_NUMBER = 1.6 ; public static final String VERSION_TYPE = "Release Build" ; public static final String VERSION_DATE = "Jun 10, 2006" ; public static final String VERSION_STRING = "" + VERSION_NUMBER + " (" + VERSION_TYPE + " " + VERSION_DATE + ")"; protected ParserFeedback mFeedback; protected Lexer mLexer; public static final ParserFeedback DEVNULL = new DefaultParserFeedback (DefaultParserFeedback.QUIET); public static final ParserFeedback STDOUT = new DefaultParserFeedback (); static { getConnectionManager ().getDefaultRequestProperties ().put ( "User-Agent", "HTMLParser/" + getVersionNumber ()); } public static String getVersion () { return (VERSION_STRING); } public static double getVersionNumber () { return (VERSION_NUMBER); } public static ConnectionManager getConnectionManager () { return (Page.getConnectionManager ()); } public static void setConnectionManager (ConnectionManager manager) { Page.setConnectionManager (manager); } public static Parser createParser (String html, String charset) { Parser ret; if (null == html) throw new IllegalArgumentException ("html cannot be null"); ret = new Parser (new Lexer (new Page (html, charset))); return (ret); } public Parser () { this (new Lexer (new Page ("")), DEVNULL); } public Parser (Lexer lexer, ParserFeedback fb) { setFeedback (fb); setLexer (lexer); setNodeFactory (new PrototypicalNodeFactory ()); } public Parser (URLConnection connection, ParserFeedback fb) throws ParserException { this (new Lexer (connection), fb); } public Parser (String resource, ParserFeedback feedback) throws ParserException { setFeedback (feedback); setResource (resource); setNodeFactory (new PrototypicalNodeFactory ()); } public Parser (String resource) throws ParserException { this (resource, STDOUT); } public Parser (Lexer lexer) { this (lexer, STDOUT); } public Parser (URLConnection connection) throws ParserException { this (connection, STDOUT); } public void setResource (String resource) throws ParserException { int length; boolean html; char ch; if (null == resource) throw new IllegalArgumentException ("resource cannot be null"); length = resource.length (); html = false; for (int i = 0; i < length; i++) { ch = resource.charAt (i); if (!Character.isWhitespace (ch)) { if ('<' == ch) html = true; break; } } if (html) setLexer (new Lexer (new Page (resource))); else setLexer (new Lexer (getConnectionManager ().openConnection (resource))); } public void setConnection (URLConnection connection) throws ParserException { if (null == connection) throw new IllegalArgumentException ("connection cannot be null"); setLexer (new Lexer (connection)); } public URLConnection getConnection () { return (getLexer ().getPage ().getConnection ()); } public void setURL (String url) throws ParserException { if ((null != url) && !"".equals (url)) setConnection (getConnectionManager ().openConnection (url)); } public String getURL () { return (getLexer ().getPage ().getUrl ()); } public void setEncoding (String encoding) throws ParserException { getLexer ().getPage ().setEncoding (encoding); } public String getEncoding () { return (getLexer ().getPage ().getEncoding ()); } public void setLexer (Lexer lexer) { NodeFactory factory; String type; if (null == lexer) throw new IllegalArgumentException ("lexer cannot be null"); // move a node factory that's been set to the new lexer factory = null; if (null != getLexer ()) factory = getLexer ().getNodeFactory (); if (null != factory) lexer.setNodeFactory (factory); mLexer = lexer; // warn about content that's not likely text type = mLexer.getPage ().getContentType (); if (type != null && !type.startsWith ("text")) getFeedback ().warning ( "URL " + mLexer.getPage ().getUrl () + " does not contain text"); } public Lexer getLexer () { return (mLexer); } public NodeFactory getNodeFactory () { return (getLexer ().getNodeFactory ()); } public void setNodeFactory (NodeFactory factory) { if (null == factory) throw new IllegalArgumentException ("node factory cannot be null"); getLexer ().setNodeFactory (factory); } public void setFeedback (ParserFeedback fb) { if (null == fb) mFeedback = DEVNULL; else mFeedback = fb; } public ParserFeedback getFeedback() { return (mFeedback); } public void reset () { getLexer ().reset (); } public NodeIterator elements () throws ParserException { return (new IteratorImpl (getLexer (), getFeedback ())); } public NodeList parse (NodeFilter filter) throws ParserException { NodeIterator e; Node node; NodeList ret; ret = new NodeList (); for (e = elements (); e.hasMoreNodes (); ) { node = e.nextNode (); if (null != filter) node.collectInto (ret, filter); else ret.add (node); } return (ret); } public void visitAllNodesWith (NodeVisitor visitor) throws ParserException { Node node; visitor.beginParsing(); for (NodeIterator e = elements(); e.hasMoreNodes(); ) { node = e.nextNode(); node.accept(visitor); } visitor.finishedParsing(); } public void setInputHTML (String inputHTML) throws ParserException { if (null == inputHTML) throw new IllegalArgumentException ("html cannot be null"); if (!"".equals (inputHTML)) setLexer (new Lexer (new Page (inputHTML))); } public NodeList extractAllNodesThatMatch (NodeFilter filter) throws ParserException { NodeIterator e; NodeList ret; ret = new NodeList (); for (e = elements (); e.hasMoreNodes (); ) e.nextNode ().collectInto (ret, filter); return (ret); } public void preConnect (HttpURLConnection connection) throws ParserException { getFeedback ().info (HttpHeader.getRequestHeader (connection)); } public void postConnect (HttpURLConnection connection) throws ParserException { getFeedback ().info (HttpHeader.getResponseHeader (connection)); } public static void main (String [] args) { Parser parser; NodeFilter filter; if (args.length < 1 || args[0].equals ("-help")) { System.out.println ("HTML Parser v" + getVersion () + "\n"); System.out.println (); System.out.println ("Syntax : java -jar htmlparser.jar" + " <file/page> [type]"); System.out.println (" <file/page> the URL or file to be parsed"); System.out.println (" type the node type, for example:"); System.out.println (" A - Show only the link tags"); System.out.println (" IMG - Show only the image tags"); System.out.println (" TITLE - Show only the title tag"); System.out.println (); System.out.println ("Example : java -jar htmlparser.jar" + " http://www.yahoo.com"); System.out.println (); } else try { parser = new Parser (); if (1 < args.length) filter = new TagNameFilter (args[1]); else { filter = null; // for a simple dump, use more verbose settings parser.setFeedback (Parser.STDOUT); getConnectionManager ().setMonitor (parser); } getConnectionManager ().setRedirectionProcessingEnabled (true); getConnectionManager ().setCookieProcessingEnabled (true); parser.setResource (args[0]); System.out.println (parser.parse (filter)); } catch (ParserException e) { e.printStackTrace (); } } }
首先我们要看看构造方法:通常,我们使用HTMLParser的时候是这样new的 Parser a = Parser.createParser(content,"UTF-8");而这个方法就是通过new Parser(New Lexer(new Page(html,charset)));方法创建一个Parser,也就是核心是Page对象,Lexer对象和Parser对象。
看其他的构造方法,空构造方法,我们略去。
public Parser(Lexer lexer,ParserFeedback fb),里面无非就是设置词法解析器,设置异常信息接收器,和设置一个nodeFactory。
public Parser (URLConnection connection, ParserFeedback fb)网页
public Parser (String resource, ParserFeedback feedback) 对内容进行解析
public Parser (String resource)
public Parser (Lexer lexer)
public Parser (URLConnection connection)
无非就是用默认的fd,之后会对FeedBack类进行相关说明。
到这里,parser完成的无非就是对给定的url,或者content,或者urlconnection对象,创建相应的词法分析器,feedback,和根据条件创建相应的Page对象。同时,我们看到Nodefactory实际上的设置是在Lexer中进行的。这里先不管。
这里有几个我们经常用的方法
public NodeList parse (NodeFilter filter) throws ParserException 根据过滤条件返回相应的nodelist
public void visitAllNodesWith (NodeVisitor visitor) throws ParserException 运用迭代器的方式进行遍历,这里涉及了NodeVisitor,IteratorImpl 这里还没有看。暂时不知道为什么这样设计。
public void setInputHTML (String inputHTML) 可以对html元素进行解析
public NodeList extractAllNodesThatMatch (NodeFilter filter) 根据过滤条件返回满足条件的NodeList
最后是测试方法。parser类读完了,其实parser类就是一个大的入口,将与页面相关的信息传递给parser类,parser调用其他类对其进行解析,返回nodelist。nodelist里面有若干node,而实例化的node里面存有我们相用的各种信息,到这里没有看到词法分析器的影子。。
PrototypicalNodeFactory
对Text,Remark,Tag进行标准化的约束。这个类暂时不做过多介绍,等用到的时候进行相关解释。
Remark
Text
Tag 这三个接口类,实现node,为具体的Node提供接口。
至此,org.htmlParser 阅读完毕,看见还是比较简单的。为什么我要阅读这个代码,一时项目中用到了这个HTMLParser,因为不放心,想知道内部是如何实现的。二是,我自动机以前挂掉过,我想自己实现一个Parser。三是,我的时间和充裕。
下一章节,我们将介绍另一个核心包:org.htmlparser.lexer 。同时,我们要对html页面标准进行学习,不然如何自己实现一个Parser呢?
欢迎批评指正。
吸取上次代码过多的教训,这次主要讲设计。
org.htmlparser.lexer 包,是主要的进行html解析的包。Page类可以根绝传入的urlConnection,text,stream等类型,构造相应的Page对象,Page对象中比较关键的是Source,url,PageIndex对象,他们的用途是:Source相当于一个Reader,但是与Reader不同的地方是,Source应当是线程同步的,字符可以改变,而且有可能多次请求。这边主要是要对解析的内容进行记录,记录位置等信息。Source是抽象类,具体的实现是StringSource和InputStreamSource。而inputStreamSource 的同步操作是依赖Stream类实现的同步方法。对于string类型的的source,直接构造相应buffered data即可。pageIndex对象是是对每行的第一个字符的位置进行记录。最后lexer是对page对象进行词法解析,我们看到有如下的几个方法,parseCDATA,scanJIS,parseString,parseTag,parseRemark,parseJsp,parsePI。这个可能要根据不同的页面进行不同的解析方法的编写。剩下的比较重要的包无非就是filter包。那这样我们对HTMLParser的构造就大致了解了,用图呈现如下:
HTMLParser各个包之间的关系图(只将比较重要的几个类,用流程的方式串联起来)
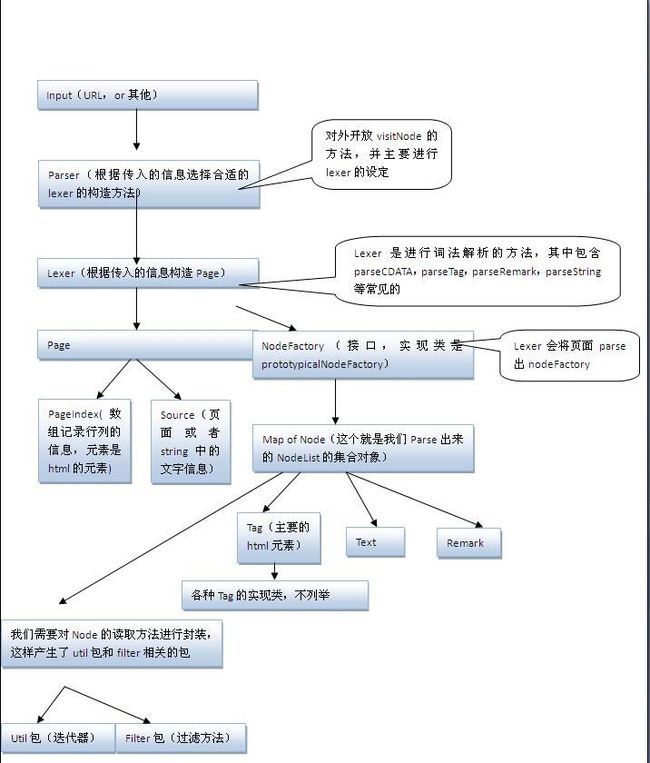
以上是我对htmlparser 包和类之间的分析,具体的htmlparser的包的组织结构如下图:
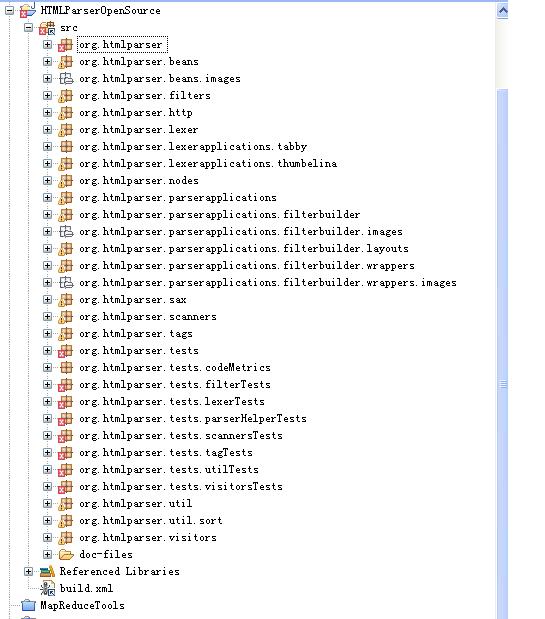
大部分的包都在关系图中显示了,剩下的是一些测试包,一些数据的组织包,并不是htmlparser的核心。按照这个思路,下一步可以自己做一个小型的parser解析器了。
总感觉少了点什么,缺又不清楚少了什么。