基础架构篇
起因
大概花了一个月不到的时间,看完了这本400页不到的书《构建高性能web站点》,不得不说这是我第一次真正意义上完全看完一本书,尽管曾经看过许多技术类的书。其中一个原因,就是大部分的技术类书籍偏向枯燥,即使是本着某种虔诚的目的和愿望去阅读,仍然很容易中途放弃。但是这本书却不同,它十分能吸引我的阅读愿望,几乎在所有的环节上能够引起我的共鸣思考,于是便快速的阅读了一遍此书。
作者主要以典型的LAMP为例子,我几乎没有接触过这方面,但是相信思想是一致的,学思想打基础才是关键。因此,本文是以概要性的总结为主。
概览图
下面这张图我花了比较长的时间绘制,提炼了书中关于基础架构设计方面的部分,希望能把它们浓缩在一张图中,而且图中包含image-map,可以通过点击虚框链接到下文的对应部分。不过需要强调的是,这张图仅仅是一个杂烩,并不是实际的架构,切勿对号入座。
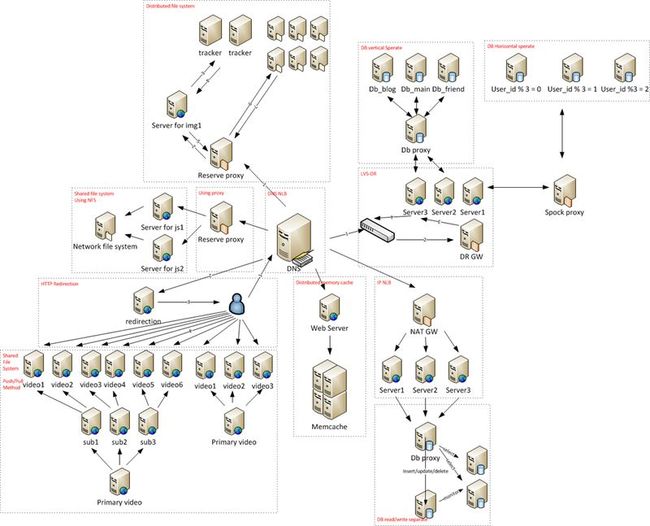
组件分离
DNS负载均衡
不同的web内容分布到不同的服务器上,并划分子域,利用DNS将请求自然转移到不同的服务器上。主要可以分为两大内容:
- 动态内容,CPU、IO密集型
- 静态内容,IO密集型
通过在DNS中配置多个A记录,将请求转移到集群中不同的服务器,这有助于具有地域性问题的大型web站点上,DNS可以使用户就近访问相应的web服务器。像BIND这样的DNS服务软件提供丰富的调度策略。但是,如果集群中的主机出现故障的话,需要更新DNS缓存,这通常需要一定的时间。另外,客户端也可以通过设置host来绕开DNS调度。
跨域共享cookie:将cookie的范围扩大到父域
HTTP重定向
通过使客户端重定向,来分散和转移请求压力,比如一些下载服务通常都有几个镜像服务器。
分布式缓存
无法使用页面级别缓存时,需要考虑直接缓存数据,比如使用memcached作为缓存。此时,需要考虑并发写memcached的问题。 另外,当memcached横向规模扩大,服务器数量增加时,需要一种对应算法,能够使应用程序知道应该链接哪个memcached服务器(比如,取模运算)。分布式缓存能够自动重建缓存,不必担心down机。
负载均衡
负载均衡就是将请求分散,这涉及到应当如何设计调度策略,以让集群发挥最大的性能。当集群中的主机能力相当时应当尽量平均调度,能力不均时应当能者多劳。随着问题的复杂,要时刻关注调度的性能,不要让调度成为性能瓶颈。
反向代理负载均衡
反向代理服务器工作在HTTP层,类似代理服务器,与普通的代理服务器不同的是,服务器在代理的后端,而不是客户端在代理的后端,这类似于NAT,只是NAT工作在网络层。同样是负载均衡,反向代理服务器强调“转发”而不是“转移”,因为它不仅要转发客户端的请求,还要转发服务端的响应。可以用作反向代理服务器的软件有Nginx、lighttp、Apache,另外目前也有一些专业的代理转发设备能够工作在应用层,例如A10。
使用代理转发要注意以下问题:
- 由于反向代理的转发特性,使得代理本身很可能成为性能瓶颈。一般对于CPU密集型请求,使用代理比较合适,如果是IO密集型的话,这种集群方式很可能无法发挥最大性能
- 在代理上要开启健康检查,及时发现集群中的故障机,从而调整转发策略,这通常比DNS方式实时性更好
- 黏滞会话:对于启动session保存用户信息,或者后端服务器使用动态内容缓存的应用,必须将用户在一段会话中的的请求保持在同一台服务器上。代理服务器一般支持类似的配置。然而,尽量不要使应用过于本地化,比如可以使用cookie保存用户数据,或者分布式Session或分布式缓存。
IP负载均衡
字面上看,便是利用网络层进行请求转发,类似NAT网关。然而,使用网关转发在带宽上可能出现瓶颈,因为出口只有一个,所以出口的带宽要求较高。Linux中的Netfilter模块可以通过iptables的配置。比如:对外网端口8001的请求转发给内网某台服务器,而对外网端口8002的请求转发给内网另一台服务器。这种方式简单易行,但是无法对调度做太多配置。LVS-NAT同样是Linux中的在网络层进行转发的方式,与Netfilter不同,它支持一些动态调度算法,比如最小链接、带权重的最小链接、最短期望延迟等。
直接路由
直接路由是通过调度器修改数据包的目的MAC地址,转发请求数据包,但是响应数据包可以直接发送给外网的方式。这样做显而易见的好处就是无需担心网关瓶颈,但是实际的服务器和调度服务器都需要链接在WAN交换机上,并且拥有独立的外网IP地址。
这种方式的工作原理略微复杂:
首先每台服务器都需要设置一个IP别名,这个IP别名是面向客户端的一个虚拟IP,只有代理服务器对这个IP别名的ARP请求做出响应,这样客户端发给这个IP的请求包首先会到代理服务器。然后代理服务器将这个请求包的目的MAC地址填写为实际服务器的MAC地址(通过某种调度算法决定目的服务器),由于目标服务器也具有这个IP别名,因此,转发过来的数据包能够被实际的服务器接收并处理。最后由于数据包的源IP地址还是客户端请求的IP地址,因此,实际的服务器将通过交换机直接将响应包转发给客户端而无需通过代理服务器。
")
Linux下可以通过LVS-DR实现直接路由方式
IP隧道
IP隧道的意思是,调度器将原始的IP数据包封装在新的IP数据包中,以实现调度,实际的服务器可以将响应数据包直接转发给用户端。
共享文件系统
对于一些简单的提供文件下载的服务(包括html中静态资源等),自然要考虑利用集群来减压,但是如何使这些资源在集群中的主机上同步呢。
NFS
一种方案是让这些主机从同一个地方取数据。比如采用NFS(Network File System),基于PRC。这种方式简单易行,但是由于NFS服务器本身的磁盘吞吐率,或者并发处理能力以及带宽等问题,往往很有局限性。
冗余分发
另一个方案就是在主机上冗余存储资源,这样主机无需访问共享文件系统,只需读取本地磁盘上的资源即可。但是这也带来了一个同步的问题,如何同步这些数据呢:
主动分发式,还分为单级分发和多级分发,分发可以借助SCP、SFTP、HTTP扩展协议WebDAV
- 单级分发:通过一次分发,就达到目的,这样的方案简单易行,但是性能瓶颈会出现在磁盘压力和网络带宽,难以扩展
- 多级分发:通过多次分发,才达到目的地,这样的方案能够分散磁盘压力和网络带宽压力,而且容易扩展,坏处是成本高
被动同步式容易理解,可以使用rsync,rsync同步时是根据最后更新时间进行判定是否需要同步的条件的,因此,如果一个文件夹中有的文件数量太多的话,rsync扫描的时间就很长了,可以通过给文件夹设置最后更新时间,并合理的规划文件目录,来加快rsync的扫描时间。即使不使用rsync,自己开发同步程序也可以借助这样的思想来提升性能。
分布式文件系统
分布式文件系统工作在用户进程层面上,它是一个管理文件的平台,内部维护冗余,检索,追踪、调度等工作,通常包含一个物理层面的组织结构和逻辑层面的组织结构。物理层面的组织结构由分布式文件系统自行维护,逻辑层面的组织结构面向用户。其中“追踪器”起到了关键的作用。
MogileFS就是一个开源分布式文件系统,用Perl编写,包含追踪器、存储节点、管理工具,它使用MySQL分布式文件系统的所有信息、使用WebDAV实现文件复制。其他著名的还有Hadoop。
每个文件由一个key定义,需要读取文件时,指定一个key,追踪器会返回一个实际的路径,在访问这个地址即可获得文件。甚至可以将这个key对应的path用分布式缓存缓存起来,这样可以减少追踪器的查询开销,但这样也会失去分布式文件系统的调度策略的优越性。另外,可以利用支持reproxy的反向代理服务器(比如:Perlbal)让路径重定向的工作由反向代理服务器完成。
数据库扩展
主从复制,读写分离
这种方式是指利用数据库的复制或镜像功能,同时在多台数据库上保存相同的数据,并且将读操作和写操作分开,写操作集中在一台主数据库上,读操作集中在多台从数据库上,对于读取比写更多的站点适合使用这种方式。如果不想在应用程序层面维护这种分离映射,那么可以使用数据库反向代理来自动完成对读写的分离。
垂直分区
对于不需要进行联合查询的数据表可以分散到不同的数据库服务器上,这称为垂直分区;当然每个分区自身也可以使用读写分离。
水平分区
将同一个表的记录拆分到不同的表甚至是服务器上,称为水平分区,这往往需要一个稳定的算法来保证读取时能正确从不同的服务器上取得数据,比如简单的对ID取模、范围划分、亦或者是保存映射关系。 也可以使用类似代理的产品spock。
总结
本文概括了《构建高性能web站点》书中关于基础架构部分的内容,只是一个简明的概要,几乎每个地方都有很大的学问值得深究。
劳动果实,转载请注明出处:http://www.cnblogs.com/P_Chou/archive/2012/10/10/high-performance-web-site-infrastructure.html