join多表连接和group by分组
join多表连接和group by分组
上一篇里面我们实现了单表查询和top N查询,这一篇我们来讲述如何实现多表连接和group by分组。
一、多表连接
多表连接的时间是数据库一个非常耗时的操作,因为连接的时间复杂度是M*N(M,N是要连接的表的记录数),如果不对进行优化,连接的产生的临时表可能非常大,需要写入磁盘,分多趟进行处理。
1、双表等值join
我们看这样一个连接sql:
select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME from SUPPLIER,PARTSUPP where PS_SUPPKEY = S_SUPPKEY and PS_AVAILQTY > 2000and S_NATIONKEY = 1;
可以把这个sql理解为在SUPPLIER表的S_SUPPKEY属性和PARTSUPP表的PS_SUPPKEY属性上作等值连接,并塞选出满足PS_AVAILQTY > 2000和 S_NATIONKEY = 1的记录,输入满足条件记录的PS_AVAILQTY,PS_SUPPLYCOST,S_NAME属性。这样的理解对我们人来说是很明了的,但数据库不能照这样的方式执行,上面的PS_SUPPKEY其实是PARTSUPP的外键,两个表进行等值连接,得到的连接结果是很大的。所以我们应该先从单表查询条件入手,在单表查询过滤之后再进行等值连接,这样需要连接的记录数会少很多。
首先根据PS_AVAILQTY > 2000找出满足条件的PARTSUPP表的记录行号集A,然后根据S_NATIONKEY = 1找出SUPPLIER表找出相应的记录行号集B,在记录集A、B上进行等值连接,看图很简单:

依次扫描的时间复杂度为max(m,n),加上折半查找,总的时间复杂度为max(m,n)*(log(m1)+log(n1)),其中m1、n1表示where条件塞选出的记录数。
来看一下执行的结果:
Input SQL: select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME from SUPPLIER,PARTSUPP where PS_SUPPKEY = S_SUPPKEY and PS_AVAILQTY > 2000 and S_NATIONKEY = 1; {'FROM': ['SUPPLIER', 'PARTSUPP'], 'GROUP': None, 'ORDER': None, 'SELECT': [['PARTSUPP.PS_AVAILQTY', None, None], ['PARTSUPP.PS_SUPPLYCOST', None, None], ['SUPPLIER.S_NAME', None, None]], 'WHERE': [['PARTSUPP.PS_AVAILQTY', '>', '2000'], ['SUPPLIER.S_NATIONKEY', '=', '1'], ['PARTSUPP.PS_SUPPKEY', '=', 'SUPPLIER.S_SUPPKEY']]} Quering: PARTSUPP.PS_AVAILQTY > 2000 Quering: SUPPLIER.S_NATIONKEY = 1 Quering: PARTSUPP.PS_SUPPKEY = SUPPLIER.S_SUPPKEY Output: The result hava 26322 rows, here is the fisrt 10 rows: ------------------------------------------------- rows PARTSUPP.PS_AVAILQTY PARTSUPP.PS_SUPPLYCOST SUPPLIER.S_NAME ------------------------------------------------- 1 8895 378.49 Supplier#000000003 2 4286 502.00 Supplier#000000003 3 6996 739.71 Supplier#000000003 4 4436 377.80 Supplier#000000003 5 6728 529.58 Supplier#000000003 6 8646 722.34 Supplier#000000003 7 9975 841.19 Supplier#000000003 8 5401 139.06 Supplier#000000003 9 6858 786.94 Supplier#000000003 10 8268 444.21 Supplier#000000003 ------------------------------------------------- Take 26.58 seconds.
从Quering后面的信息可以看到我们处理where子条件的顺序,先处理单表查询,再处理多表连接。
2、多表join
处理完双表join后,我们看一下怎么实现三个的join,示例sql:
select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME from SUPPLIER,PART,PARTSUPP where PS_PARTKEY = P_PARTKEY and PS_SUPPKEY = S_SUPPKEY and PS_AVAILQTY > 2000 and P_BRAND = 'Brand#12' and S_NATIONKEY = 1;
这里进行三个表的连接,三个表连接得到的应该是三个表的记录合并的结果,那根据where条件选出的记录行号应当包含三列,每一列是一个表的行号:
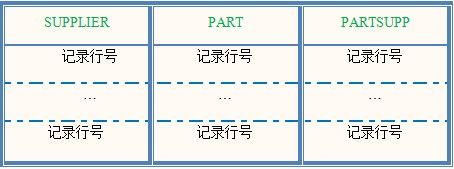
三个表的连接事实上建立在两个表连接的基础上的,先进行两个表的连接后,得到两组行号表,再将这两组行号表合并:

主要代码如下:
1 sortJoin(joina,cloumi)#cloumi表示公共表在joina的列号 2 sortJoin(joinb,cloumj)#cloumj表示公共表在joinb的列号 3 i = j = 0#左右指针初试为0 4 while i < len(joina) and j < len(joinb): 5 if joina[i][cloumi] < joinb[j][cloumj]: 6 i += 1 7 elif joina[i][cloumi] > joinb[j][cloumj]: 8 j += 1 9 else:#相等,进行连接 10 lastj = j 11 while j < len(joinb) and joina[i][cloumi] == joinb[j][cloumj]: 12 temp = joina[i] + joinb[j] 13 temp.remove(joina[i][cloumi])#删掉重复的元素 14 mergeResult.append(temp) 15 j += 1 16 j = lastj#右指针回滚 17 i += 1
我们分析一下这个算法的时间复杂度,首先要对两个表排序,复杂度为O(m1log(m1)),在扫描的过程中,右边指针会回溯,所以不再是O(max(m1,n1)),我们可以认为是k*O(m1*n1),这个系数k应该是很小的,因为一般右指针不会回溯太远,总的时间复杂度是O(m1log(m1))+k*O(m1*n1),应该是小于N方的复杂度。
看一下执行的结果:
Input SQL: select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME from SUPPLIER,PART,PARTSUPP where PS_PARTKEY = P_PARTKEY and PS_SUPPKEY = S_SUPPKEY and PS_AVAILQTY > 2000 and P_BRAND = 'Brand#12' and S_NATIONKEY = 1; {'FROM': ['SUPPLIER', 'PART', 'PARTSUPP'], 'GROUP': None, 'ORDER': None, 'SELECT': [['PARTSUPP.PS_AVAILQTY', None, None], ['PARTSUPP.PS_SUPPLYCOST', None, None], ['SUPPLIER.S_NAME', None, None]], 'WHERE': [['PARTSUPP.PS_AVAILQTY', '>', '2000'], ['PART.P_BRAND', '=', 'Brand#12'], ['SUPPLIER.S_NATIONKEY', '=', '1'], ['PARTSUPP.PS_PARTKEY', '=', 'PART.P_PARTKEY'], ['PARTSUPP.PS_SUPPKEY', '=', 'SUPPLIER.S_SUPPKEY']]} Quering: PARTSUPP.PS_AVAILQTY > 2000 Quering: PART.P_BRAND = Brand#12 Quering: SUPPLIER.S_NATIONKEY = 1 Quering: PARTSUPP.PS_PARTKEY = PART.P_PARTKEY Quering: PARTSUPP.PS_SUPPKEY = SUPPLIER.S_SUPPKEY Output: The result hava 1022 rows, here is the fisrt 10 rows: ------------------------------------------------- rows PARTSUPP.PS_AVAILQTY PARTSUPP.PS_SUPPLYCOST SUPPLIER.S_NAME ------------------------------------------------- 1 4925 854.19 Supplier#000002515 2 4588 455.04 Supplier#000005202 3 8830 852.13 Supplier#000007814 4 8948 689.89 Supplier#000002821 5 3870 488.38 Supplier#000005059 6 6968 579.03 Supplier#000005660 7 9269 228.31 Supplier#000000950 8 8818 180.32 Supplier#000003453 9 9343 785.01 Supplier#000003495 10 3364 545.25 Supplier#000006030 ------------------------------------------------- Take 50.42 seconds.
这个查询的时间比Mysql快了很多,在mysql上运行这个查询需要10分钟(建立了索引),想想也是合理的,我们的设计已经大大简化了,完全不考虑表的修改,牺牲这么的实用性必然能提升在查询上的效率。
二、group by分组
在执行完where条件后,读取原始记录,然后可以按group by的属性分组,分组的属性可能有多条,比如这样一个查询:
select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME,COUNT(*) from SUPPLIER,PART,PARTSUPP where PS_PARTKEY = P_PARTKEY and PS_SUPPKEY = S_SUPPKEY and PS_AVAILQTY > 2000 and P_BRAND = 'Brand#12' and S_NATIONKEY = 1; group by PS_AVAILQTY,PS_SUPPLYCOST,S_NAME;
按 PS_AVAILQTY,PS_SUPPLYCOST,S_NAME这三个属性分组,我们实现时使用了一个技巧,将每个候选记录的这三个字段按字符串格式拼接成一个新的属性,拼接的示例如下:
"4925" "854.19" "Supplier#000002515" -->> "4925+854.19+Supplier#000002515"
注意中间加了一个加号“+”,这个加号是必须的,如果没有加号,"105","201"与"10","5201"的拼接结果都是"105201",这样得到的group by结果将会出错,而添加一个加号它们两的拼接结果是不同的。
拼接后,我们只需要按新的属性进行分组,可以使用map来实现,map的key为新的属性值,value为新属性值key的后续记录。再在组上进行聚集函数的运算。
这个小项目就写到这里了,或许这压根只是一个数据处理,谈不上数据库实现,不过通过这个小项目我对数据库底层的实现还是了解了很多,以后做数据库优化理解起来也容易一些。
谢谢关注,欢迎评论。