C#
C#复习
第一章
1、.NET是平台,C#是.NET上的一门语言。
2、C#的异常处理机制:try catch finally
Try 引发异常 catch捕获异常 finally 释放资源
3、catch finally(错误)
问题:.NET Framework由什么组成?
答:有公共语言运行时(CLR)和.NET Framework基类库(FCL)这两大组件组成。
第二章 类、对象、方法
1、什么是类:具有相似特性(属性)和行为(方法)的对象的集合。
2、什么是对象:在现实世界中存在的,并且看得见摸得着的一切事物。
3、类与对象之间的关系:一对多的关系。类是对象的蓝图。
4、面向对象的三大特性:封装、继承、多态。
封装:隐藏内部实现,稳定外部接口。
继承:子类继承父类的所有成员,实现代码的复用。
多态:不同的子类对于同一个消息做出的不同一种反映。
5、类的访问修饰符:public(公共的) Intermal(默认的访问修饰符)
成员访问修饰符:
| public |
允许类的使用者从外部进行访问 |
| private |
C#中的私有成员公限于类中的成员可以访问,从类的外部访问私有成员是不合法。 |
| protected |
为了方便派生类的访问,有希望成员对于外界隐藏的,这时可以使用protected修符声明成员为保护成员。 |
| intemal |
对于同一应用程序是可以访问的。 |
6、类中分为两种成员:成员变量(字段,属性),成员函数(方法)
属性的作用:1、封装字段,为字段提供有效的数据验证。
2、为其他类提供一个外部的访问接口。
属性的分类:只读属性、只写属性、可读可写属性。
7、方法的分类:实例方法、静态方法、构造方法(构造函数)
实例方法:当一个类被实例化后,通过类的实例(对象)调用的方法。
静态方法:当直接通过类名调用的方法。静态方法中只能包含静态成员变量。
构造方法:当类的实例(对象)被创建的过程中,所调用的方法称为构造方法。
特点:构造方法与类名相同,且没有反回类型。
8、重载和重写的概念:
| 重写(override) |
在面向对象中重新实现父类的虚方法或者抽象对象方法,通过override关键字来重写体现面向对象的多态性。重写又称覆盖。 |
| 重载 |
同一类中添加几个方法名字相同,参数个数或者参数类型不同的方法,称为重载,重载与方法的返回类型无关。 |
第三章 static、构造函数
1、八大基本数据类型:
类型:
|
|
数据类型 |
所占字节数 |
| 整型 |
int |
4字节 |
| Byte |
1字节 |
|
| Short |
2字节 |
|
| long |
8字节 |
|
| 浮点型 |
Double |
|
| Float |
|
|
| 字符型 |
Char |
|
| String |
|
|
| 布尔型 |
Boolean |
|
2、const:常量是在字段定义时初始化,是静态赋值。
Readonly:只读的变量,可以在字段初始化或构造函数中动态赋值。
注意: const与readonly不能同时存在。
3、构造函数的概念:函数的名字与类名相同,并且没有返回值,这样的函数称为构造函数
构造函数的作用:
(1)初始化字段或属性;
(2)用于创建对象。
4、析构函数的概念:用~开头,函数名和类同名,函数没有访问修饰符,函数没有参数,这样的函数称为析构函数
如:~类名(){}
析构函数的调用规则:
(1) 一个类只能有一个析构函数
(2) 析构函数没有访问修饰符,没有参数
(3) 析构函数由C#程序自动调用,程序员不能调用
(4) 析构函数的作用:用于回收无用的对象所占用的内存空间
比较构造函数和析构函数调用时间和调用频率
| 实例 |
构造函数 |
在创建类的每个新实例时调用一次 |
| 析构函数 |
在每个实例被销毁前调用 |
|
| 静态 |
构造函数 |
只调用一次,在类的任意静态变量第一次被访问之前,或在类的任何实例被创建之前,无论两者谁先发生。 |
| 析构方法 |
不存在,只有实例才有析构方法 |
5、C#中数据类型分类:值类型、引用类型。
值类型:将实际的值保存在内存的栈中。
引用类型:通过指针指向内存栈中实际值的地址。引用类型的本身保存在堆中。
String sl=null;//空引用
Sl=””;//空值
6、关键字this公在构造函数、类的方法和类的实例中使用,主要有以下含义:
(1)出现在类的构造函数中的this,表示正在构造的对象本身的引用
(2)出现在类的方法中的this,表示对调用该方法的对象的引用。
第四章 索引器、枚举、结构
1、定义索引器的语法
访问修饰符 返回类型 this[数据类型 标识]
{
Get{return 内容;}
Set{}
}
注意:
(1) get{}访问器中,return后的内容的类型要和定义索引的返回类型一致;
(2) 索引器一般用在将对象作为数组的情况;
(3) [数据类型 标识]数据类型根据具体情况进行定义;
(4) 根据[]中的不同数据类型根据具体情况进行定义;
(5) 索引器类似于属性,可以根据下标访问元素,也包含get{}和set{}访问器;
(6) 索引器也类似于数组,可以根据下标访问元素,但索引器比数据更灵活,数据元素只能根据下标访问,索引器还可以根据其他类型进行访问。
2、枚举(enum)是一个指定的常数,其基础类型可以是任何整型,如果没有显示声明基础类型,则用int。
枚举是值类型的一种特殊形式。
枚举的限制:
(1) 不能定义自己的方法;
(2) 不能实现接口;
(3) 不能定义属性或索引。
3、结构(struck)是程序员自定义的数据类型,非常类似于类
语法:struck 结构名称
{
//结构成员;
}
第五章 继承、多态
1、在C#继承中,如果子类继承父类,那么子类就必须继承父类的构造函数。如果父类没有默认构造函数,那么子类就必须显示调用父类带参的构造函数。
2、在C#中,如果子类继承父类,在实例化子类的时候,首先执行父类的构造函数,再执行子类的构造函数。
3、在C#继承中,父类可以派生多个子类,子类只能直接继承一个父类,继承具有传递性以及单根性的特点。
4、创建子类对象时,程序先调用父类无参的构造方法,再调用子类自己的构造方法,无论子类的构造方法是否有参数,始终调用父类无参的构造方法。
5、注意:
(1) base关键字表示调用父类的构造方法;
(2) base(参数1,参数2,……)中的参数只有参数名,没有数据类型;
(3) 根据base()中的参数个数决定调用父类的哪个构造方法;
(4) base(参数1,参数2,……)中的参数名要和子类([参数……])中的参数名相同。
6、继承的特点:单根性和传递性。
7、is检查对象是否与指定类型兼容。
as用于在兼容的引用类型之间执行转换。
第六章 抽象类、接口
1、抽象类(abstract):在C#中通过关键字abstract定义的类称为抽象类。
2、抽象类主要用于类的蓝图或模版。
3、抽象类(abstract)的特点:
(1) 抽象类中既包含抽象方法又包含实例方法;
(2) 有抽象方法的类一定是抽象类;
(3) 抽象类可以被继承,但是不能被实例化;
(4) 抽象类一般作为基类,子类继承抽象类,必须实现抽象类中的抽象方法;
(5) 抽象类不能是密封类或静态类。
抽象方法:只能定义没有实现的方法称为抽象方法。
有抽象方法的类一定是抽象类。
当子类继承的父类是一个抽象类时,子类要么实现父类中所有的抽象方法,要么将自己也声明为抽象类,子类重写父类的抽象方法时,必须使用关键字override。
抽象类的作用:强制约束子类的行为。
4、密封类(sealed):用关键字sealed定义的类为密封类。
密封类的特点:
(1) 类中不能有虚方法;
(2) 密封类不能被其它类继承。
string是密封类,所以不能被继承。
5、虚方法(virtual):在C#中默认的方法形式都是非虚方法。如果父类的方法被定义为虚方法,那么子类就可以通过override重写父类的虚方法,否则子类将隐藏(new)父类的方法。
6、接口:接口是单纯对事物行为的描述。
接口的作用:实现多重继承。
接口的特点:为了C#中继承单根性的扩展。
子类继承父类,可以实现多个接口。
接口中包含的内容:属性、方法、索引器、事件。
7、类实现接口的语法:类名:接口名{类成员、方法}。
注意:当类实现接口时要实现接口中的所有方法。
8、接口的默认修饰符是public,而且public不需要显示的定义,也不能修改成其它修饰符
注意:
1) 接口可以继承接口,当类实现的接口继承于其它接口时,类需要实现子接口和父接口中的所有定义内容。
2) 父类实现接口中的方法时将方法定义为虚方法,子类继承父类时用override关键字重写父类的方法,接口中的方法子类就不需要再实现。
比较类与结构的区别
a) 类中字段可以有初始值,结构中字段不可以有初始值。
b) 类中可以包含默认构造函数,结构中不能有显示定义的默认构造函数,结构体中带参数构造函数,但是构造函数中的参数必须为所有字段赋值。
c) 类属于引用类型,结构属于值类型。
d) 类可以被继承,结构不能被继承。
e) 类必须实例化,结构可以实例化也可以不实例化
虚方法与抽象方法的区别
| 虚方法 |
抽象方法 |
| 用virtual修饰 |
用abstract修饰 |
| 要用方法体,哪怕是一个分号 |
不允许有方法体 |
| 可以被子类override(重写) |
必须被子类override(重写) |
| 除了密封类都可以写 |
只能在抽象类中 |
抽象类与接口的区别
|
|
抽象类 |
接口 |
| 不同点 |
用abstract定义 |
用interface定义 |
| 只能继承一个类 |
可以实现多个接口 |
|
| 非抽象派生类必须实现抽象方法 |
实现接口的类必须实现所有成员 |
|
| 需要override实现抽象方法 |
直接实现 |
|
| 相似点 |
不能被实例化 |
|
| 包含未实现的方法 |
||
| 派生类必须实现未实现的方法 |
||
第七章 ListView 和TreeView
TreeView中的常用属性的方法:
属性 :
1、 nodes:获取TreeView控件的所有节点集合,返回一个treenodecollection,表示此控件的树节点集合。
2、 SelectNode:获取或设置当前在树视图控件中选定的树节点。
3、 ShowNodeTooltips:获取或设置一个值,当鼠标县停在TreeNode上时显示工具示。
TreeView.Node返回的是Treenodecollection类型。
Treenodecollection属性:
1、 count:获取TreeNode中对象的总数。
TreeNodeCollection方法:
1、 Add()向集合中添加新的树节点。
2、 Clear()删除所有树节点。
TreeView中每一个节点表示一个TreeNode对象
TreeNode常用属性和方法:
Level属性:获取TreeView控件中树视图的深度。
Nodes属性:获取当前树节点的TreeView对象的集合。
ToolTipText和ShowNodeToolTips的区别:
方法:
Collapse():折叠TreeNode
CollapseAll():折叠所有的树节点。
Expand():展开树节点。
ExpandAll():展开所有子树节点。
GetNodeCount():返回子树节点的数目
AfterSelect事件:选定树节点时触发。
创建TreeView实例
//创建根节点
TreeNode root=new TreeNode(“根节点名”);
//创建子节点
TreeNode node=new TreeNode(“子节点名”);
//将子节点添加到根节点中
Root.Nodes.Add(node);
//将根节点添加到TreeView控件中
TreeView.Node.Add(root);
TreeNode对象用于创建节点
节点对象名1.Nodes.Add(节点对象名2)——节点对象名2是对象名1的子节点
节点对象名1.Text——给节点设置文本
注意:TreeView中只需添加根节点
ExpandAll()方法展开所有节点
SelectedNode属性得到是选中的TreeNode对象
Level属性得到一个节点的深度(层次),根节点的深度是0,以此类推。
ListView常用属性及方法
属性:
View:设置或获取项在控件中的显示方式。
FocusedItem:获取或设置当前具有焦点的控件的项。
Items:获取包含控件中所有项的集合。
Columns:获取控件中显示的所有列标题的集合。
SelectedItems:获取控件中当前选中的项。
FullRowSelect:制定时某一项还是某一项所在的行。
ListViewItem:属性的方法
SubItems:获取包含该项的所有子项的集合。
Text:获取或设置项的显示文本。
ToolTipText:获取或设置当鼠标停留在ListViewItem上时显示的文本。
ListView常用的方法:
Clear:删除ListView中的所有的项。
创建ListView的实例:
//清空原有项
ListView1.Items.Clear();
//创建ListView对象
ListViewItem item=new ListViewItem(“集点项数据”);
//添加子项
Item.SubItems.Add(“子项数据”);
//向ListView中添加项
ListView1.Items.Add(item);
第八章 委托与事件
委托的定义:委托是一种引用方法的类型。一旦为委托分配了方法,委托将与该方法具有完全相同的行为。委托方法的调用可以像其他任何方法一样,具有参数的返回值,委托方法将方法作为参数进行引用。
语法:
访问修饰符 delegate 返回值类型 委托名();
委托不能被继承和重载。
委托的签名:由返回类型和参数值组成。
将方法委托给对象的实现步骤:
(1) 定义委托:访问修饰符 delegate 返回值类型 委托名();
(2) 定义类,在类中定义方法:
class 类名
{
访问修饰符 返回值类型 方法名1(){……}
访问修饰符 返回值类型 方法名2(){……}
访问修饰符 返回值类型 方法名3(){……}
}
(3) 创建类的对象:类名 对象名 =new 类名();
(4) 创建委托对象:
方法一:委托名 委托对象名=new 委托名(对象名.方法名());
方法二:委托名 委托对象名=对象名.方法名;
注意:方法后不要带();
(5)(可选步骤)给委托对象委托多个方法
如:委托对象名+=对象名.方法名2;
(6)调用委托对象:如
委托对象名();
例:委托的实例:
//定义一个无参无返回值的委托
public delegate void Hello();
//创建委托对象
HelloDel del=new HeelDel(方法名);
//在测试为中调用委托
Del();
注意:委托对象名后一定要跟();
委托名、类名、方法名1、对象名、委托对象名均由程序员定义
匿名方法:
语法:
Delegate 参数弄表 {语句块}
匿名方法实例
//定义委托
Delegate void Hello()
//通过匿名方法创建委托对象
Hello hello=delegate()
{
Console.WriteLine(“hello!”);
}
//调用委托
Hello();
练习:使用委托,输出本周和下周的学习安排
将方法给委托对象的规则:
(1) 委托的参数类型要和方法的参数类型一致。
(2) 可以委托多个有返回值的方法,但委托对象的返回值是最后一个方法的返回值
(3) +=表示添加要委托的方法,-=表示去掉已经委托的方法。
练习:定义委托,执行接收一个数字,返回该数字的立方的方法。
事件
事件是类在发生其关注的事情时用来提供通知的一种方式。
1、 委托是事件的基础,事件返回委托的类型。
2、 定义事件的语法:
访问修饰符 event 委托名 事件名;
使用事件的步骤:
1) 定义委托,如:访问修饰符 delegate 返回值类型 委托名();
2) 定义触发事件的类及方法,如:
class 类名1
{
//定义事件
访问修饰符 event 委托名 事件名;
//定义方法调用事件
访问修饰符 返回值类型 方法名1()
{
[//代码部分]
//调用事件
事件名();
}
}
3) 定义响应事件的类及方法,如:
class 类名2
{
//定义方法响应事件
访问修饰符 返回值类型 方法名2()
{
//代码部分
}
}
4) 订阅事件,如:
//创建响应事件类的对象
类名2 对象名2=new 类名2();
//将类中方法给委托
委托名 委托对象名=对象名.方法名2;
//创建角发事件类的对象
类名1 对象名1=new 类名1();
//将委托加载到事件
对象名1.事件名+=委托对象名;
//调用角发事件的方法
对象名1.方法名1();
this.button1.Click+=new System.EventHandler(this.button1_Click);
注意:委托事件的基础。
事件的事例:
//定义委托
Public delegate void del();
//定义事件
public event del eve;
//定义角发事件的方法
public void begin()
{
Console.WriteLine(“处理。”);
}
//定义订阅事件的方法
public void DingYue()
{
eve+=new del(chuli);
}
第十章 文件操作
File 类——操作文件,是一个静态类
主要提供用于创建、复制、删除、移动和打开文件的静态方法,其更侧重于对文件的操作。
File类是一个密封类,不能被继承。其所有成员皆是静态的,可以不要创建实例
File类的常用方法
Create(路径及文件名.后缀)——创建文件
delete(路径及文件名.后缀)——删除文件
exists(路径及文件名.后缀)——判断文件是否存在,存在返回true,不存在返回false。
copy(源文件路径,目标文件路径)——复制文件
move(源文件路径,目标文件路径)——移动文件(相当于剪切和粘贴)
OpenWrite(路径及文件名.后缀)——以写入的方式打开文件
练习:在E盘下创建文件:学习计划.txt,然后将文件移动到D盘,再判断D盘下是否存在该文件,如果存在,将文件删除。
创建文件的实例:
//声明一个变量,存储路径
string path=@“E:\test.txt”
//判断文件是否存在
if(File.Exists(path))
{
//如果存在则删除
File.Delete(path);
}
else
{
//创建文件
File.Create(path);
}
//向文件中写入内容的操作步骤
(1) 打开文件(可以判断,如果文件不存在则先创建,如果存在则以写的方式打开);
(2) 将要写进文件的内容用字节数组保存;
(3) 调用文件流的Write()方法将内容写进文件;
(4) 关闭文件流。
用FileStream向文件中写入内容的实例:
//创建一个文件流
FileStream fs=null;
//创建一个FileStream对象
fs=new FileStream(“E:\test.text”,FileModel.OpenOrCreate);//使用指定的路径和创建模式初始化
FileStream类的新实例。
将字符串按UTF8的编码方式转换为字节数组:
byte[] array=new UTF8Encoding(true).GetBytes(“内容”);
Encoding.Default.GetBytes(内容)——使用系统默认的字符集将内容转换成字节数组
////写入内容
fs.write(“写入的内容”,0,“写入字节长度”);缓冲区读取的数据将字节块写入该流,0:从零开始的字节偏一,从此处开始将字节复制到当前流。
//清空缓冲区
fs.flush();
//关闭流
fs.Close();
从文件中读取内容的操作步骤:
(1) 打开文件(可以判断文件是否存在)
(2) 定义字节数组
(3) 调用文件流的Read()方法,将文件中的内容读取到字节数组
(4) 将字节数组转换后输出
(5) 关闭文件流
练习:向E盘下的“学些计划.txt”文件写入学习计划,然后读取学习计划,在控制台中打印
FileInfo类:提供创建、复制、删除、移动和打开文件的实例方法,FileInfo类属于sealed密封类,不能被继承。
FileInfo类的常用属性
l Exists 判断该文件是否存在
l Length 文件的大小
l Name 文件名
l FullName 文件的完整路径
l IsReadOnly 是否为只读
l Creationtime 当前文件的创建时间
l
Directory类:提供用于创建、移动、删除目录和子目录的静态方法
l Delete 删除目录及其内容
l Exists 判断目录是否存在
l GetCurrentDirectory 应用程序的当前工作目录
l GetDirectories 指定目录中子名称
l GetFiles 指定目录的文件名称
l Move 将目录移动新的位置
DirectoryInfo类:提供了用于创建、移动、删除目录和子目录的实例方法
l Create 创建目录
l delete 删除DirectoryInfo及其内容
l GetDirectories 指定目录中子目录的名称
l GetFiles 指定目录中的文件名称
l MoveTo将DirectoryInfo 实例及其内容移动到新位置
File类静态类,FileInfo密封类
使用建议:
(1) 如果需要对文件进行多次操作,应FileInfo类,因为在创建对象时就指定了正确的路径,File中的方法大多是静态的,每次都需要重新寻找文件,会花费更多资源。
(2) 如果公操作文件一次,应使用File类,直接调用方法,无需创建对象。
我的问题:WinForm中的文件与Java中有何区别?
第十一章 集合与泛型
泛型:List<T>
T表示任意数据类型,用来约束添加到集合中的内容
|
|
ArrayList |
List<T> |
| 不同点 |
可以添加任何元素,添加元素时装箱,读取元素时拆箱。 |
添加元地有类型的约束,无需装箱和拆箱。 |
| 相同点 |
可以动态的添加、删除元素,使用索引引访问元素。 注意:使用ArrayList的地方均可以用Lit<T>代替。 |
|
|
|
HashTable |
Dictionary<KT,VT> |
| 不同点 |
可以添加任何元素,添加时装箱,读取时拆箱 |
添加的元素有类型约束,无需装箱、拆箱。 |
| 相同点 |
动态的添加、删除元素,根据键访问元素。 |
|
泛型集合细解:
Array:
Array是所有数组类的基类
创建一个数组的语法:Array a=Array.CreateInstance(typeOf(指定数据类型),大小);
a.Length;数据元素的个数
a.SetValue();给数组元素赋值
a.GetValue();从数组中取得指定下标的元素
a.Sort();给数组元素排序
a.Reverse();翻转原有数组元素
……
ArrayList:
ArrayList(列表集合)是常用的集合类型,他可以动态添加、删除元素,其大小可以动态变化,他把所有元素都当成object对象引用,因此访问ArrayList元素时要进行类型转换。
构造函数:
(1) 默认构造函数:ArrayList arrayList=new ArrayList();
(2) 添加指定数组到集合中的构造方法:ArralList arrayList=new ArrayList(arrayName);
arrName:数组名字
(3) 使用指定大小初始化内部大小的数组构造函数:ArrayList arrayList=new arrayList(n);
n:指定的初骀大小。
添加元素:
Add();该方法将对象添加到ArrayList集合的末尾处。
Insert();该方法用于将元素插入ArrayList集合的指定索引处。
InsertRange();该方法用于将一个数组插入ArrayList集合的指定索引处
删除元素:
Remove();该方法用于将指定名称的元素从集合中移除
RemoveAt();该方法用于将指定索引处的元素从集合中移除。
RemoveRange(int index,int count);该方法用于从集合中移除一定范围的元素
index要移除的元素从0开始的索引
count要移除的元素的个数
Clear();该方法用于从集合中移除所有的元素。
搜索元素:
Contains();该方法用于确定指定名称的元素是否在集合。
IndexOf();该方法与string字符串类的同名方法用法作用基本相同
HashTable:
HashTable(哈希表)是System.Collections命名空间提供的一个集合,可以将数据作为一组键/值对来存储,它的每个元素都是一个存储在DictionaryEntry对象中的键/值对。键不能为空,区分大小写,不能重复;值可以为空,可重复。
构造函数:
(1) 默认构造函数:HashTable ht =new hashTable();
(2) 使用指定初始容量、默认加在子、默认哈希代码提供程序和默认比较器初始化HashTable类的新的空实例:HashTable ht=new HashTable(int 初始大小);
添加元素:
Add(object Key,object value);将带有键、值的元素添加到HashTable中
删除元素:
Clear();将HashTable中所有元素移除。
Remove();将HashTable中带有指定键的元素移除。
搜索元素:
ContainsKey();确认是否含有指定键。
ContainsValue();确认是否含有指定值。
泛型:
泛型一个主要优点是性能,泛型的目标是采用广泛适用的和可交互性的形式来表示算法和数据结构,以使他们能直接用于软件构造。泛型能在编译时提供强大的类型检查,减少数据类型之间的显示转换,装拆箱操作和运行时的类型检查,可以强化类型的集合,提高性能。
List<T>
ArrayList是一个很方便的集合类,但添加的其中的任何引用或值类型都将隐式转换为Object类型,强制转换以及装拆箱操作都会降低性能。与ArrayList相比,List<T>比它更安全并且速度更快,特别适合列表项是值类型的情况。
构造函数:
默认构造函数:List<T> list=new List<T>();该实例为空并且具有默认初始容量
List中,有添加、删除、插入元素的方法,与ArryList的方法类似,在确定是要使用List还是ArrayList的时候,最好使用List。
第十三章 序列化和反射
序列化:将对象转换成可存储格式的过程称为序列化。
反序列化:将文件中的内容生成对象的过程称为反序列化。
序列化的步骤:
(1) 创建要保存的内容:字符串、集合对象、泛型集合对象、对象数组……
(2) 创建文件流:FileStream fs=new FileStream(“路径”,“打开方式”);
(3) 创建序列化对象:BinaryFormatter bf=new BinaryFormatter();
(4) 调用方法,将内容保存到文件中: bf.Serialize(fs,内容);
(5) 清空缓存:fs.Flush();
(6) 关闭流件流:fs.Close();
反序列化的步骤:
(1) 创建文件流:FileStream fs=new FileStream(“路径”,“打开方式”);
(2) 创建序列化对象:BinaryFormatter bf=new BinaryFormatter();
(3) 调用方法,将读取的内容保存到对应类型的以象中:
数据类型 变量名/对象名=(数据类型)bf.Deserialize(fs);
(4) 清空缓存:fs.Flush();
(5) 关闭文件流:fs.Close();
(6) 输出变量/对象中的内容。
三 层
三层结构:(3W1H)
(一)问题:
1、 什么是三层?
2、 为什么要使用三层?
3、 在哪儿用三层?
4、 怎样搭建三层?
5、 有哪三层?
三层在生活中的案例:客户去茶馆吃饭,呼叫服务员点菜,服务员将菜单交给厨师做菜,厨师将做好的菜传递给服务员,服务员交给客户。
(二)三层分为:UI(表示层,User Interface)
BLL(Business Logic Layer 业务逻辑层)
DAL(Data Access Layer 数据访问层)
(三)三层的依赖关系:
1、 数据访问层依赖于实体层与数据访问接口。
2、 业务逻辑层依赖于实体层与数据访问层。
3、 表示层依赖于实体层与逻辑层。
(四)三层的职责
- 数据访问层:提出数据库中的数据,对数据进行增、删、改操作。
- 业务逻辑层:提取数据访问层中的数据,对数据进行业务功能上的筛选与验证。
- 表示层:为客户提供人机交互的界面。
(五)三层的作用:分工明细,有利于软件的可维护性与可扩展性。
一条记录,对应一个实体类,一张表的记录就对应一个泛型集合。
一个表的增删改操作都保存在DAL类中。
一个业务功能点的实现都需要在BLL类中筛选与验证,BLL中不包含任何的数据库操作语句。
QUESTION AND ANSWER
一、imageKey和imageIndex的区别?
imageKey:获取或设置为该项显示的图像的键。
imageIndex:获取或设置为该项显示的图像的索引。
二、什么是重写和重载?
重写:在面向对象中,子类继承父类,子类将父类的抽象方法具体实现或重新实现父类中的虚方法的过程。
重载:方法名相同,参数个数、顺序、类型不同。重载与方法的返回类型无关。
三、异常关键字解释
try:监控代码
catch:捕获异常
finally:释放资源,始终都会执行
四、类的默认访问修饰符?类的访问修饰符能不能是私有的?
默认的访问修饰符是:internal。类的访问修饰符不能是私有的,它只有public和internal两种。
五、for和foreach的区别?
for:是循环,根据下标找元素,可读可写。
foreach:是遍历,可读不可写(自动遍历给定的集合体的所有值。)
六、SqlDataAdapter和SqlCommand的区别?
SqlDataAdapter是数年开式连接,不用打开,主要用于对sql的查询
SqlCommand需要打开服务器连接同时主要用于对sql的增删改操作。
七、DataSet和SqlDataReader的区别?
DataSet:断开式连接,一次性填充所有数据到内存中。
SqlDataReader:一次只读取一行记录,需要一直保护连接,效率高于DataSet。
八、ADO.net常用的组件?
Sqlcommand命令对象
SqlConnection连接对象
SqlDataAdapter数据适配器
SqlTransaction表示要在SQL Server中处理Transact-SQL事务。
SqlParameter表示SqlCommand的参数,也可以是它到DataSet列的映射。
九、泛型集合的好处?
1、 避免装拆箱;
2、 提供指定类型;
3、 泛型里有大量的扩展方法,方便查找和操作数据。
十、三层的依关系?
数据访问层:依赖于实体层和数据访问接口(补充:实现对数据的保存和读取操作);
业务逻辑层:依赖于实体层和数据访问层(补充:是表示层与数据访问层之间的桥梁,负责数据处理、传递)。
表示层:依赖于实体层和业务逻辑层。
十一、什么是装拆箱?
将值类型转换为引用类型是装箱,将引用类型转换为值类型是拆箱。
十二、静态类包含的方法一定是静态方法?
一定是。静态类不能被实便化。
十三、如何防止一个类不能被继承?
使用sealed关键字,表示密封类。
十四、解释这个表达式的相关符号
Regex reg=new regex(@”[0-9]+(,[0-9]{1})?$”);
^:开始
&:结束
{1}:表示一位小数
+:前面出现的表达式只能是1次或多次
?:前面出现的表达式只能是0次或1次
*:前面出现的表达式只能是0次或多次
十五、属性的作用?
1、 封装字段,为字段提供有效的数据验证;
2、 为其它类提供一个外部的访问接口。
十六、封装的作用?
隐藏内部实现,稳定外部接口
十七、show和showDialog的区别?
show()可以同时弹出多个窗体(非模式化窗口)
showDialog()(模式化窗口)
十八、MessageBox.Show()的返回值是什么类型?
DialogResult类型
十九、解释as和is的使用?
as:用于在兼容的引用类型之间执行转换。
is:检查对象是否与指定类型兼容
二十、public class SQLHelper:DBHelper在子类中通过什么关系字符继承基类?
在C#中使用:
二十一、FocusedItem表示的是什么?
表示具有焦点的项。
二十二、解释图片上传的相关代码
//打开文件对话框
this.openFileImage.ShowDialog()=dialogResult.OK
//获得选择的图片路径
string filename=openFileImage.FileName;
//FileName:获取或设置一个包含在文件对话框中选定的文件名的字符串,文件名既包含文件路径也包含扩展名。
//LastIndexOf:在此实例中的最后一个匹配项的索引位置
string fileType=filename.SubString(FileName.LastIndexOf(“.”)+1;
//从指定的文件创建image
ptbImage.Image=Image.FromFile(FileName);
this.txtLiuLan.Text=Filename;//把获取的图片路径赋值给浏览文本框
//获取对话框中所选择文件的文件名和扩展名。文件名不包含路径
string picName=openFileImage.SafeFileName;
//Application.StartupPath:获取启动了应用程序的可执行文件的路径,返回string类型
//File…Copy方法(string,string,Boolean)将现有文件复制到新文件。true允许覆盖同名的文件
File.Copy(FileName,Application.StartupPath+@”\images\”+picName,true);
//保存图片到ImageList图片集合控件
//@符号的作用:把字符按原样输出
frmBookInfo.ImageList1.Image.Add(picName,Image.FromFile(FileName));
//Image.FromFile返回image类型
二十三、怎样将至绑定到下拉列表中?隐藏绑定图书类型的编号有什么用意?
//获取数据源
cboType.DataSource=ttypeServers.SelectBookType();
//指定显示的成员名字
cboType.Displaymember=”BookTypeName”;
//指定显示成员的value属性
cboType.ValueMember=”BookTypeId”;
隐藏图书类型编号的用意:以便新增、修改图书信息时获取图书类型编号。
二十四、string类型是否能被继承?
string类型不能被继承,因为string前面有sealed修饰,它是一个密封类。
二十五、#region、#endregion的意思?
指定可展开或折叠的代码块,#region块必须以#endregion指定终止
二十六、C#是否支持多继承?
C#中不支持多继承,因为继承具有单根性。
二十七、结构体是值类型还是引用类型?
是值类型。
二十八、command有哪几种常用的方法?
ExecuteNonQuery()返回的是一个影响的行数,为int类型;
ExecuteReader()表示读取查询的数据
ExecuteScalar()返回第一行第一列的值
熟悉的话,那么谈何选择合适的数据结构呢?如果你也存在和我一样的问题,可以尝试着继续读这篇文章,或许能给你带来帮助。
这篇文章讨论的主题是集合,重点在于分析集合的区别和联系,加深对集合的认知与使用,熟悉常用C#类库有关集合类的组织结构。
数组
论集合,不得不谈的第一项就是数组。C#数组需要声明元素类型,元素类型可以是值类型也可以是引用类型,数组是静态类型,初始化必须指定个数大小,且创建后的数组是连续存放在内存中的。声明方式如下所示:
int[] intArray = new int[10]; //整型数组 string[] stringArray = new string[10]; //字符串数组 Random[] randArray = new Random[10]; //类数组
数组是从Array隐式派生的,这是由编译器完成的,Array类被组织在System命名空间下。
Array myArray1 = new int[10]; Array myArray2 = new string[10]; Array myArray3 = new Random[10];
数组是引用类型,初始化后分配在堆上。
System.Collections
1. System.Collections 组织空间
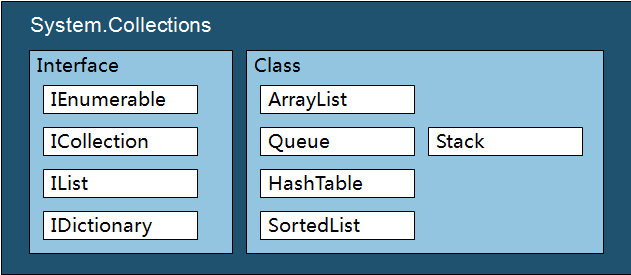
2. 通用接口
集合类型都实现了IEnumerable接口,从而可以使用foreach迭代。
实现了ICollectoin接口的集合类表明集合中的元素是有先后顺序的。
IList接口继承了ICollection接口,实现了IList接口的集合类不止表明集合中的元素是有先后顺序,而且表明集合类可以通过下标访问的方式访问集合元素。
IDictionary接口也继承了ICollection接口,实现了IDicionary接口的集合类可以通过下标key访问的访问方式访问集合元素。
3. ArrayList
Array是静态分配的,意味着创建数组后的大小不能改变,然而实际应用中,我们很多时候无法在一开始确定数组的大小,这样便需要一种能动态分配的数组类型,ArrayList就是为此而生的。ArrayList主要实现的接口有IList,所以这是一个索引集合。
//声明ArrayList ArrayList myArray = new ArrayList(); //插入元素 可以为值类型 也可以为引用类型 myArray.Add(1); myArray.Add("hello"); myArray.Add(new Random()); int i = (int)myArray[0]; string str = (string)myArray[1]; Random rand = (Random)myArray[2];
使用Reflector查看ArrayList的底层实现,可以看到动态数组其实是由一个object[] _items维系着的,这就解释了为什么集合的元素可以为值类型也可以为引用类型。这样的底层实现貌似灵活性很高,集合可以容纳异构类型,然而却带来了性能上的问题,因为当插入值类型的时候,就存在隐式装箱操作,而当把元素还原为值类型变量的时候,又发生了一次显式拆箱操作,如果这种装箱拆箱存在上千万次,那么程序的性能是要大打折扣的。同时要注意一点的是object类型可以强制转化为任何类型,这是说编译器不会检查object强制转换的类型,如果无法转换的话,这必须等到运行时才能确定出错,这就是类型安全问题。
所以应该尽量避免使用ArrayList。
4. Stack 和 Queue
对于栈和队列这两种经典的数据结构,C#也将它们组织在System.Collections命名空间中。Stack是后进先出的结构,Queue是先进先出的结构,这两者主要实现的接口有ICollection,表示它们都是有序集合,应注意到这两者都不可以使用下标访问集合元素。这两者的底层实现都是由一个object[] _array维系着,都存在着装箱拆箱的性能问题和类型安全问题,所以应该尽量避免直接使用它们。
5. HashTable
前面我们提到的集合类都属于单元素集合类,实际应用中我们需要一种键值对的形式存储数据,即集合类中存储的不再是单个元素,而是key-value两个元素,HashTable就是为此而生的。HashTable实现了IDictionary接口。
//创建一个HashTable实例 Hashtable hashDict = new Hashtable(); //往容器中加入key-value hashDict.Add("a", "hello"); hashDict.Add("b", "hello"); hashDict.Add("c", "go"); hashDict.Add(4, 300); //通过下标key获取value string str1 = hashDict["a"].ToString(); string str2 = (string)hashDict["b"]; int i4 = (int)hashDict[4];
HashTable中的key关键字必须唯一,不能重复。如果深入到HashTable的底层实现,应该可以清楚的看到key和value是结构体bucket数组维护着,bucket中key和value的实现也是object,所以存在着与ArrayList,Stack,Queue同样的问题,应该尽量避免使用HashTable。
为什么键值集合类要命名为HashTable?
从HashTable的命名来看,我们可以断定说键值集合跟Hash必定存在某种联系。哈希又称为散列,散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key),f又称为散列函数。HashTable实现了IDictionary接口,表明HashTable可以通过下标key访问的方式获取数组元素,即 HashTable[key],这与实现了IList接口的集合类的数字下标访问存在着明显的不同。那么如何通过key快速定位得到value呢?我相信通过前面的铺垫大伙都知道是什么回事了,对,就是哈希函数的运用。具体可以参考文章http://www.cnblogs.com/abatei/archive/2009/06/23/1509790.html。
6. SortedList
在控制台应用程序下运行以下代码并观察结果:
Hashtable hashDict = new Hashtable(); hashDict.Add("key1", "1"); hashDict.Add("key2", "2"); hashDict.Add("key3", "3"); hashDict.Add("key4", "4"); foreach (string key in hashDict.Keys) { Console.WriteLine(hashDict[key]); }
我们可以看到这里并没有按照预期的Key顺序输出Value。也就是说HashTable是不按照key顺序排序的,具体原理可以参考HashTable的源码。SortedList很好地解决了键值集合顺序输出的问题。
//创建一个SortedList实例 SortedList sortList = new SortedList(); //往容器中加入元素 sortList.Add("key1", 1); sortList.Add("key2", 2); sortList.Add("key3", 3); sortList.Add("key4", 4); //获取按照key排序的第index个Key string str1 = sortList.GetKey(0).ToString(); Console.WriteLine(str1); //获取按照key排序的第index个Value int i1 = (int)sortList.GetByIndex(0); Console.WriteLine(i1.ToString()); //下标key访问 string str2 = sortList["key2"].ToString(); Console.WriteLine(str2); //遍历sortList foreach (DictionaryEntry item in sortList) { Console.WriteLine(item.Key); Console.WriteLine(item.Value); }
SortedList实现了IDictionary接口,所以可以使用下标key访问元素的形式,同时要求key必须唯一。
SortedList的底层实现与HashTable有着本质的区别。SortedList中使用object[] keys 和 object[] values 两个对象数组分别来存储key和value,要求实现能按照key有序输出,在下标key访问的时候就无法使用Hash函数了,所以SortedList虽然也是键值集合,但与Hash却没有任何联系。通过查看SortedList的底层代码,原来它的实现是二分查找(BinarySearch),也就是说要求key是有序排列的,在查找的时候进行二分比较搜索,找到对应的index,从而返回values[index]。
如果需要实现按照key有序输出,那么毫无疑问就要选择SortedList了。如果不需要按照key有序输出,在小数据量的情况下,两者选择任何一个性能都应该差不多,但大数据量的情况下,则更应该选择HashTable。为什么呢?理由有两点。1.HashTable的key下标访问更直接更快。通过上面分析我们知道SortedList的key下标访问是由二分查找实现的,实现的时间复杂度为O(log n),而Hash函数的时间复杂度为O(1),HashTable的实现更优。2.SortedList要求key有序,这意味着在插入的时候必须适当地移动数组,从而达到有序的目的,所以存在性能上的消耗,HashTable的实现更优。
SortedList也并没有走出装箱拆箱性能和类型安全的圈子,所以应该尽量避免直接使用它。
System.Collections.Generic
1. System.Collections.Generic 组织空间

2. 何为集合泛型
新的命名空间下,可以看到接口或集合类后都携带了<T>或<TKey,TValue>。很明显,携带<T>对应的是单元素集合,携带<TKey,TValue>对应的是键值集合。那么泛型又是如何工作的呢?来看一下其编译过程吧:初次编译时,首先生成IL代码和元数据,T(TKey,TValue)只是作为类型占位符,不进行泛型类型的实例化;在进行JIT编译时,将以实际类型替换IL代码和元数据中的T占位符,并将其转换为本地代码,下一次对该泛型类型的引用将使用相同的本地代码。
泛型即解决了装箱拆箱的性能问题,又解决了潜在的类型转换安全问题,所以在实际应用中,推荐使用泛型集合代替非泛型集合。
3. 泛型集合与非泛型集合的对应
ArrayList => List<T> 新的泛型集合去掉了Array前缀。
Stack,Queue => Stack<T>,Queue<T>
HashTable => Dictionary<TKey,TValue> 新的泛型键值集合的命名放弃了HashTable,但其内部实现原理还是和HashTable有很大相似的。
SortedList => SortedList<TKey,TValue> | SortedDictionary<TKey,TValue>
SortedList<TKey,TValue>的底层实现基本是按照SortedList,下标key访问是二分查找的O(log n),插入和移除运算复杂度是O(n)。而SortedDictionary<TKey,TValue> 底层实现是二叉搜索树,下标key访问也为O(log n),插入和移除运算复杂度是O(log n)。所以SortedList<TKey,TValue>使用的内存会比SortedDictionary<TKey,TValue>小,SortedDictionary<TKey,TValue>在插入和移除元素的时候更快。
C#基础之类型和成员基础以及常量、字段、属性
首先吐糟一下今天杭州的天气,真是太热了!虽然没有妹子跟我约会,但宅在方寸大的窝里,也是烦躁不已!
接上一篇《C#基础之基本类型》
类型和成员基础
在C#中,一个类型内部可以定义多种成员:常量、字段、实例构造器、类型构造器(静态构造器)、方法、操作符重载、转换操作符、属性、事件、类型。
类型的可见性有public和internal(默认)两种,前者定义的类型对所有程序集中的所有类型都可见,后者定义的类型只对同一程序集内部的所有类型可见:
public class PublicClass { } //所有处可见 internal class ExplicitlyInternalClass { } //程序集内可见 class ImplicitlyInternalClass { } //程序集内可见(C#编译器默认设置为internal)
成员的可访问性(按限制从大到小排列):
- Private只能由定义成员的类型或嵌套类型中方法访问
- Protected只能由定义成员的类型或嵌套类型或派生类型中方法访问
- Internal 只能由同程序集类型中方法访问
- Protected Internal 只能由定义成员的类型或嵌套类型或派生类型或同程序集类型中方法访问(注意这里是或的关系)
- Public 可由任何程序集中任何类型中方法访问
在C#中,如果没有显式声明成员的可访问性,编译器通常默认选择Private(限制最大的那个),CLR要求接口类型的所有成员都是Public访问性,C#编译器知道这一点,因此禁止显式指定接口成员的可访问性。同时C#还要求在继承过程中派生类重写成员时,不能更改成员的可访问性(CLR并没有作这个要求,CLR允许重写成员时放宽限制)。
静态类
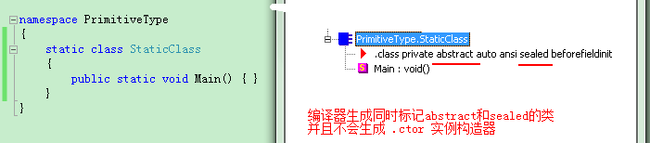
永远不需要实例化的类,静态类中只能有静态成员。在C#中用static这个关键词定义一个静态类,但只能应用于class,不能应用于struct,因为CLR总是允许值类型实例化。
C#编译器对静态类作了如下限制:
- 静态类必须直接从System.Object派生
- 静态类不能实现任何接口(因为只有使用类的一个实例才能调用类的接口方法)
- 静态类只能定义静态成员(字段、方法、属性、事件)
- 静态类不能作为字段、方法参数或局部变量使用
- 静态类在编译后,会生成一个被标记为abstract和sealed的类,同时编译器不会生成实例构造器(.ctor方法)
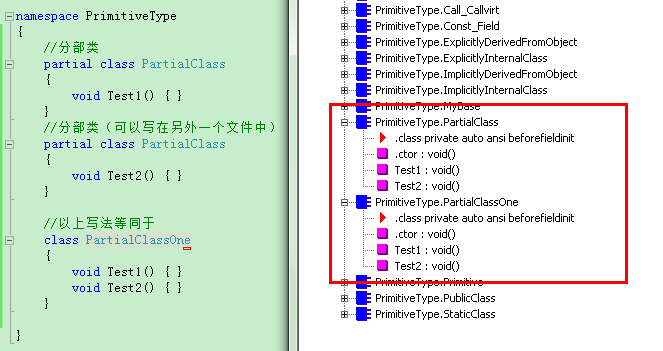
分部类、结构和接口
C#编译器提供一个partial关键字,以允许将一个类、结构或接口定义在多个文件里。
在编译时,编译器自动将类、结构或接口的各部分合并起来。这仅是C#编译器提供的一个功能,CLR对此一无所知。
常量
常量就是代表一恒定数据值的符号,比如我们将圆周率3.12415926定义成名为PI的常量,使代码更容易阅读。而且常量是在编译时就代入运算的(常量就是一个符号,编译时编译器就会将该符号替换成实际值),不会造成任何性能上的损失。但这一点也可能会造成一个版本问题,即假如未来修改了常量所代表的值,那么用到此常量的地方都要重新编译(我个人认为这也是常量名称的由来,我们应该将恒定不变的值定义为常量,以免后期改动时产生版本问题)。下面的示例也验证了这一点,Test1和Test2方法内部的常量运算在编译后,就已经运算完成。

从上面示例,我们还能看出一点:常量key和value编译后是静态成员,这是因为常量通常与类型关联而不是与实例关联,从逻辑上说,常量始终是静态成员。但对于在方法内部定义的常量,由于作用域的限制,不可能有方法之外的地方引用到这个常量,所以在编译后,常量被优化了。
字段
字段是一种数据成员,在OOP的设计中,字段通常是用来封装一个类型的内部状态,而方法表示的是对这些状态的一些操作。
在C#中字段可用的修饰符有
- Static 声明的字段与类型关联,而不是与对象关联(默认情况下字段与对象关联)
- Readonly 声明的字段只能在构造器里写入值(可以通过反射修改)
- Volatile 声明的字段为易失字段(用于多线程环境)
这里要注意的是将一个字段标记为readonly时,不变的是引用,而不是引用的值。示例:
class ReadonlyField { //chars 保存的是一个数组的引用 public readonly char[] chars = new char[] { 'A', 'B', 'C' }; void Main() { //以下改变数组内存,可以改成功 chars[0] = 'X'; chars[1] = 'Y'; chars[2] = 'Z'; //以下更改chars引用,无法通过编译 chars = new char[] { 'X', 'Y', 'Z' }; } }
属性
CLR支持两种属性:无参属性和有参属性(C#中称为索引器)。
面向对象设计和编程的重要原则之一就是数据封装,这意味着字段(封装对象的内部状态)永远不应该公开。因此,CLR提供属性机制来访问字段内容(VS中输入propfull加两次Tab会为我们自动生成字段和属性的代码片断)。
下面的示例中,Person对象内部有一个表示年龄的字段,如果直接公开这个字段,则不能保存外部不会将age设置为0或1000,这显然是没有意义的(也破坏了数据封装性),所以通过属性,可以在操作字段时,加一些额外逻辑,以保证数据的有效性。
class Person { //Person对象的内部状态 private int age; //用属性来安全地访问字段 public int Age { get { return age; } set { if (value > 0 && value <= 150) age = value; else { } //抛出异常 } } }
编译上述代码后,实际上编译器会将属性内的get和set访问器各生成一个方法,方法名称是get_和set_加上属性名,所以说属性的本质是方法。

如果只是为了封装一个字段而创建一个属性,C#还为我们提供了一种更简单的语法,称为自动实现的属性(AIP)。下面是一个示例(在VS中输入prop加两次TAB会为我们生成AIP片断):
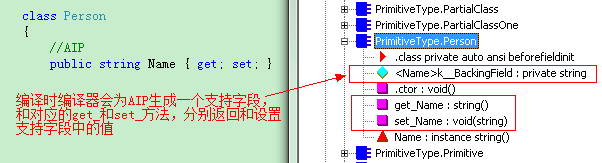
这里要注意一点,由于AIP的支持字段是编译器自动生成的,而且编译器每次编译都可能更改这个名称。所以在任何要序列化和反序列化的类型中,都不要使用AIP功能。
对象和集合初始化器
在实现编程中,我们经常构造一个对象,然后设置对象的一些公共属性或字段。为此C#为我们提供了一种简化的语法来完成这些操作。如下示例:
class Person { //AIP public string Name { get; set; } public int Id { get; set; } public int Age { get; set; } void Main() { //没有使用对象初始化器的语法 Person p1 = new Person(); p1.Id = 1; p1.Name = "Heku"; p1.Age = 24; //使用对象初始化器的语法 Person p2 = new Person() { Id = 1, Name = "Heku", Age = 24 }; } }
使用对象初始化器的语法时,实际上编译器为我们生成的代码和上面是一致的,但是下面的代码明显更加简洁。如果本来就是要调用类型的无参构造器,C#还允许我们省略大括号之前的小括号:
Person p2 = new Person { Id = 1, Name = "Heku", Age = 24 };
如果一个属性的类型实现了IEnumerable或IEnumerable<T>接口,那么这个属性就被认为是一个集合,我们同样类似的语法来初始化一个集合。比如我们在上例中的Person类中加入一个新属性Skills
public List<string> Skills { get; set; }
然后可以用下面的语法来初始化
//使用简化的对象初始化器语法+简化集合初始化器语法 Person p3 = new Person { Id = 1, Name = "heku", Age = 24, Skills = new List<string> { "C#", "jQuery" } };
这里我们用new List<string> { "C#", "jQuery" }一句来初始化了一个集合(实现上new List<string>完全可以省略,编译器会根据属性的类型来自动推断集合类型),并添加了两项纪录。编译器会我们生成的代码看起来是这样的:
p3.Skills = new List<string>(); p3.Skills.Add("C#"); p3.Skills.Add("jQuery");
匿名类型
有时候,我们需要封装一组数据,只有属性或字段,没有方法,并且只用于当前程序,不在项目间重用。
如果按传统做法,我们需要手工定义一个类来封装这组数据。匿名类型提供了一种方便的方法,可用来将一组只读属性封装到单个对象中,而无需首先显式定义一个类型。如下示例:

从上面示例可以看到,我们只写了一句
var obj = new { Id = 1, Name = "Heku", Addr = "China" };
编译器会为我们做大量的工作,首先为我们定义一个类型(类型名称是编译器编译时才生成的,编程时还不知道,所以叫匿名类型),类型内部包含了三个属性Id、Name、Addr以及对应的支持字段,同时也生成了三个get访问器方法,没有生成set访问器方法(说明匿名类型的属性是只读的)。
另外在Main方法中,由于我们编程过程中,并不知道类型名称,所以必须用var关键字来让编译器自行推荐类型(虽然也可以用object或dynamic,但这完全没有意义)。通过查看Main编译后的IL代码我们还可以发现,匿名类型的初始化是通过调用匿名类型的有参构造器来完成的,这点与之前也不相同(因为匿名类型属性是只读的,不能通过调用无参初始化器初始化后再设置属性值,编译器也根本没有生成匿名类型的无参构造器)。
有参属性
前面讲到的属性都没有参数,实现上还有一种可以带参数的属性,称之为有参属性(C#中叫索引器)。
class StringArray { private string[] array; public StringArray() { array = new string[10]; } //有参属性 public string this[int index] { get { return array[index]; } set { array[index] = value; } } void Main() { StringArray array = new StringArray(); array[0] = "Hello"; array[1] = "World"; string ss = array[0] + array[1]; } }
上面的例子中,和定义无参属性不同的是,这里并没有属性名称,而是用this[参数]的语法来定义一个有参属性(索引器),这是C#的要求。和无参属性不同,有参属性还支持重载:
//有参属性 public string this[int index] { get { return array[index]; } set { array[index] = value; } } //有参属性重载 public string this[int index, bool isStartFromEnd] { get { if (isStartFromEnd) return array[10 - index]; else return array[index]; } set { if (isStartFromEnd) array[10 - index] = value; else array[index] = value; } }
属性本质是方法,有参属性也一样(对CLR来说甚至并不分有参还是无参,对它来说都是方法的调用),那么有参属性的编译后生成的IL是什么样子呢?事实上C#对所有的有参属性生成的IL方法都默认命名为get_Item和set_Item。当然这是可以通过在索引器上应用System.runtime.CompliserServices.IndexerNameAttribute定制Attribute来改变这一默认行为。
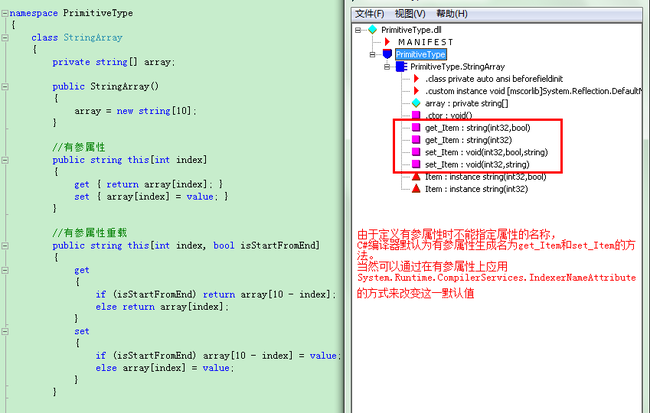
属性访问器的可访问性
属性的get和set访问器是可以定义不同的访问性的,如果get和set访问器的可访问性不一致,C#要求必须为属性本身指定限制最小的那一个。
protected string Name { get { return name; } private set { name = value; } }
注意:如果同时设置get和set的访问性,会提示“不能为属性的两个访问器同时指定可访问性修改符”,因为对属性或索引器使用访问修饰符受以下条件的制约:
- 不能对接口或显式接口成员实现使用访问器修饰符
- 仅当属性或索引器同时具有 set 和 get 访问器时,才能使用访问器修饰符。这种情况下,只允许对其中一个访问器使用修饰符
- 如果属性或索引器具有 override 修饰符,则访问器修饰符必须与重写的访问器的访问性(如果有的话)匹配
- 访问器的可访问性级别必须比属性或索引器本身的可访问性级别具有更严格的限制
结尾的话
一边搬书一边敲代码一边写博文,不知不觉又坐了将近一天(汗~我要出去活动一下了)。
能力水平有限,博文主要还是出于自我总结目的,如果有文中有误,还请大家指出,感谢!
参考
1、CLR Via C#