基于hadoop+nutch+solr的搜索引擎环境搭载<三>hadoop,nutch,solr整合到eclipse上开发
版本:
eclipse:
eclipse-jee-juno-SR2-linux-gtk
tomcat7:
apache-tomcat-7.0.39
一,下载安装eclipse,tomcat
下载安装eclipse后,解压,运行eclipse
在菜单栏里
window->preferences->server->runtime environment
add tomcat7
二,集成hadoop。
hadoop之前的版本有集成好的eclipse插件,现在需要自己编译,具体步骤可以百度。
这里是我用的插件 。
将hadoop-eclipse-plugin-1.0.4放在/eclipse/plugins下(如果是用软件中心安装的话是/usr/share/eclipse/plugins/)
重启eclipse,然后可以看到在project Explorer中看到DFS locations
window->show view->other->Map/Reduce Locations 确认后配置Hadoop installation directory即可

点“蓝色大象“新建

修改参数
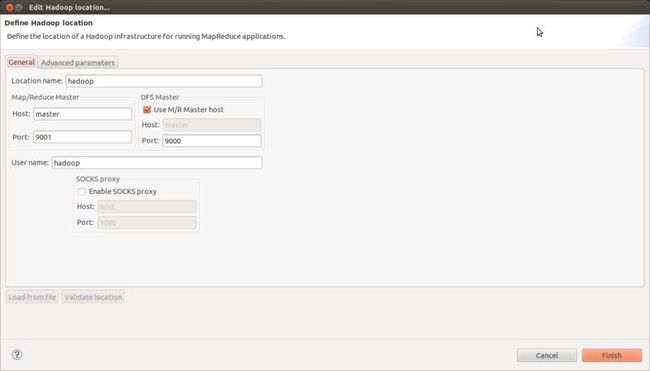
此处Map/Reduce Master与mapred-site.xml对应
DFS Master与hadoop/conf/core-site.xml中对应
重启eclipse,点开DFS location就可以看到hdfs(记得启动hadoop)
三,nutch,solr集成在hadoop上
nutch是一个应用程序,在我的这个项目里主要是做爬虫用,爬取后的内容存放在hdfs上,所以在hdfs整合模块已经整合上去了。
solr:
在eclipse新建动态网页项目,删除WebContent的所有内容。
在solr/dist下(或者/solr3.6.2/example/webapps下)解压solr.war 将所有内容拷贝到WenContent里。
修改WEB-INF里的web.xml
添加
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/home/hadoop/solr3.6.2/example/solr</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
到最后的</web-app>前。
解释下这个地方是你的solr core的位置
采用solr多核的话可以将
/home/hadoop/solr3.6.2/example/multicore,同时修改multicore中的solr.xml
<cores adminPath="/admin/cores">
<core name="core0" instanceDir="/home/hadoop/solr3.6.2/example/multicore/core0" />
<core name="core1" instanceDir="/home/hadoop/solr3.6.2/example/multicore/core1" />
</cores>
instanceDir为core的存放位置
在server中新建tomcat7服务,然后添加你刚新建的动态网页工程

启动tomcat7,在正常情况下,你可以选择运行wencontent下的index.jsp 避免你弄错url的路径。
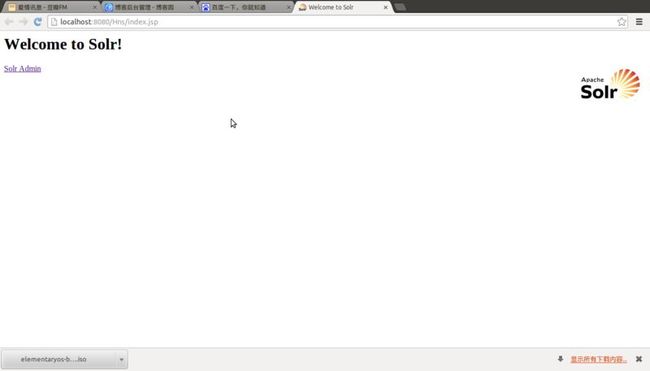
这样,hadoop+nutch+solr的eclipse环境就搭建好了。
本系列文章也就结束了,这一两个月的摸索与学习,收获很多,比如MapReduce机制,信息检索的一些知识。
当然后续还会继续主要学习hadoop。
这应该是acm后第一个知识积累的阶段。很好,继续努力。
Sleeper_qp,Fighting!!!
梦想就在眼前了。