均值估计标准差(Standard Deviation) 和 标准误差(Standard Error)
最近一直在研究均值估计之类的问题,下午正好有机会和大家分享一下.
本文摘自
Streiner DL.Maintaining standards: differences between the standard deviation and standarderror, and when to use each. Can J Psychiatry 1996; 41: 498–502.
标准差(Standard Deviation)
标准差,缩写为S.D., SD, 或者 s (就是为了把人给弄晕?),是描述数据点在均值(mean)四周聚集水平的指标。
如果把单个数据点称为“Xi,” 因此 “X1” 是第一个值,“X2” 是第二个值,以此类推。均值称为“M”。初看上去Σ(Xi-M)就可以作为描述数据点散布情况的指标,也就是把每个Xi与M的偏差求和。换句话讲,是(单个数据点—数据点的均匀)的总和。
看上去挺有逻辑性的,但是它有两个缺点。
第一个困难是:上述定义的结果永久是0。根据定义,高出均值的和永久即是低于均值的和,因此它们相互抵消。可以取差值的绝对值来处理(也就是说,忽略负值的符号),但是由于各种神秘兮兮的原因,统计学家不喜欢绝对值。另外一个剔除负号的方法是取平方,因为任何数的平方肯定是正的。所以,我们就有Σ(Xi-M)2。
另外一个问题是当我们增加数据点后此等式的结果会随之增大。比如我们手头有25个值的样本,根据前面公式计算出SD是10。如果再加25个一模一样的样本,直觉上50个大样本的数据点分布情况应当不变。但是我们的公式会产生更大的SD值。好在我们可以通过除以数据点数量N来填补这个漏洞。所以等式就酿成Σ(Xi-M)2/N.
根据墨菲定律,我们处理了两个问题,就会随之产生两个新问题。
第一个问题(或者我们应当称为第三个问题,这样能与前面的相衔接)是用平方抒发偏差。假设我们丈量自闭症儿童的IQ。或许会发现IQ均值是75, 散布水平是100 个IQ点平方。这IQ点平方又是什么东西?不过这轻易处理:用结果的平方根替代,这样结果就与原来的丈量单位一致。所以上面的例子中的散布水平就是10个IQ点,变得更加轻易理解。
最后一个问题是目前的公式是一个有偏估计,也就是说,结果总是高于或者低于实在的值。解释稍微有点庞杂,先要绕个弯。在少数情况下,我们做研究的时候,更感兴致样本来自的整体(population)。比如,我们探查有年轻男性精神分裂症患者的家庭中的外现情绪(expressed emotion,EE)水平时,我们的兴致点是全部满意此条件的家庭(整体),而不单单是哪些受研究的家庭。我们的工作就是从样本中估计出整体的均值(mean)和SD。因为研究应用的只是样本,所以这些估计会与整体的值未知水平的偏差。幻想情况下,计算SD的时候我们应当晓得每个家庭的分值(score)偏离整体均值的水平,但是我们手头只有样本的均值。
根据定义,分值样本偏离样本均值的水平要小于偏离其他值,因此应用样本均值减去分值失掉的结果总是比用整体均值(还不晓得)减去分值要小,公式产生的结果也就偏小(当然N很大的时候,这个偏差就可以忽略)。为了改正这个问题,我们会用N-1除,而不是N。总之,最后我们失掉了修正的标准差的(估计)公式(称为样本标准差):
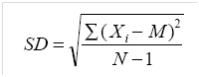
顺带一下,不要直接应用此公式计算SD,会产生很多舍入误差(rounding error)。统计学书一般会提供另外一个同等的公式,能获得更加精确的值。
当初我们完成了全部推导工作,这象征着什么呢?
假设数据是正态分布的,一旦晓得了均值和SD,我们便晓得了分值分布的全部情况。对于任一个正态分布,大概2/3(精确的是68.2%)的分值会落在均值-1 SD和均值+1 SD之间,95.4%的在均值-2 SD 和均值+2 SD之间。比如,大部份研究生或者职业院校的入学考试(GRE,MCAT,LSAT和其他折磨人的手段)的分数分布(正态)就计划成均值500,SD 100。这象征68%的人得分在400到600之间,略超越95%的人在300到700之间。应用正态曲线的概率表,我们就能准确指出低于或者高于某个分数的比例是多少。相反的,如果我们想让5%的人淘汰掉,如果晓得当年测试的均值和SD,依靠概率表,我们就能准确划出最低分数线。
总结一下,SD告知我们分值围绕均值的分布情况。当初我们转向标准误差(standard error)。
标准误差(Standard Error)
前面我提到过大部份研究的目标是估计某个整体(population)的参数,比如均值和SD(标准方差)。一旦有了估计值,另外一个问题随之而来:这个估计的精确水平如何?这问题看上去无解。我们实际上不晓得确实的整体参数值,所以怎么能评价估计值的亲近水平呢?挺符合逻辑的推理。但是以前的统计学家们没有被吓倒,我们也不会。我们可以求助于概率:(问题转化成)实在整体均值处于某个范围内的概率有多大?(格言:统计象征着你不需要把话给说绝了。)
答复这个疑问的一种方法重复研究(实验)几百次,获得很多均值估计。然后取这些均值估计的均值,同时也得出它的标准方差(估计)。然后用前面提到的概率表,我们可估计出一个范围,包括90%或者95%的这些均值估计。如果每个样本是随机的,我们就可以安心肠说实在的(整体)均值90%或者95%会落在这个范围内。我们给这些均值估计的标准差取一个新名字:均值的标准误差(the standard error of the mean),缩写是SEM,或者,如果不存在混杂,直接用SE代表。
但是首先得处理一个小纰漏:重复研究(实验)几百次。现今做一次研究已很困难了,不要说几百次了(即使你能花费整个余生来做这些实验)。好在一贯给力的统计学家们已想出了基于单项研究(实验)确定SE的方法。让我们先从直观的角度来讲:是哪些要素影响了我们对估计精确性的判断?一个显著的要素是研究的范围。样本范围N越大,反常数据对结果的影响就越小,我们的估计就越亲近整体的均值。所以,N应当出当初计算SE公式的分母中:因为N越大,SE越小。类似的,第二要素是:数据的稳定越小,我们越相信均值估计能精确反应它们。所以,SD应当出当初计算公式的分子上:SD越大,SE越大。因此我们得出以下公式:
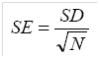
(为什么不是N? 因为实际是我们是在用N除方差SD2,我们实际不想再用平方值,所以就又采用平方根了。)
所以,SD实际上反应的是数据点的稳定情况,而SE则是均值的稳定情况。
置信区间(Confidence Interval)
前面一节,针对SE,我们提到了某个值范围。我们有95%或者99%的信念以为实在值就处在当中。我们称这个值范围为“置信区间”,缩写是CI。让我们看看它是如何计算的。看正态分布表,你会发现95%的区域处在-1.96 SD 和+1.96 SD 之间。回顾到前面的GRE和MCAT的例子,分数均值是500,SD是100,这样95%的分数处在304和696之间。如何失掉这两个值呢?首先,我们把SD乘上1.96,然后从均值中减去这部份,便失掉下限304。如果加到均值上我们便失掉上限696。CI也是这样计算的,不同的地方是我们用SE替代SD。所以计算95%的CI的公式是:95%CI= 均值± ( 1.96 x SE)。
选择SD, SE和CI
好了,当初我们有SD, SE和CI。问题也随之而来:什么时候用?选择哪个指标呢?很显著,当我们描述研究结果时,SD是必须报告的。根据SD和样本大小,读者很快就能获知SE和任意的CI。如果我们再添加上SE和CI,是不是有重复之嫌?答复是:“YES”和“NO”兼有。
本质上,我们是想告之读者通常数据在不同样本上是存在稳定的。某一次研究上获得的数据不会与另外一次重复研究的结果一模一样。我们想告之的是期望的差异到底有多大:可能稳定存在,但是没有大到会修改结论,或者稳定足够大,下次重复研究可能会得出相反的结论。
某种水平上来讲,这就是检验的显著水平,P level 越低,结果的偶然性就越低,下次能重复出类似结果的可能性越高。但是显著性检验,通常是黑白分明的:结果要么是显著的,要么不是。如果两个实验组的均值差别只是勉强通过了P < 0.05的红线,也经常被当成一个很稳定的结果。如果我们在图表中加上CI,读者就很轻易确定样本和样本间的数据稳定会有多大,但是我们选择哪个CI呢?
我们会在图表上加上error bar(误差条,很难听),通常同等于1个SE。好处是不用选择SE或者CI了(它们指向的是一样的东西),也无过多的计算。不幸的这种方法传递了很少有用信息。一个error bar (-1 SE,+1 SE )同等于68%的CI;代表我们有68%的信念真的均值(或者2个实验组的均值的差别)会落在这个范围内。糟糕的是,我们习惯用95%,99% 而不是68%。所以让忘记加上SE吧,传递的信息量太少了,它的主要用途是计算CI。
那么把error bar加长吧,用2个SE如何?这好像有点意思,2是1.96的不错估计。有两方面的好处。首先这个方法能显示95%的CI,比68%更有意义。其次能让我们用眼睛检验差别的显著性(至少在2个实验组的情况下是如此)。如果下面bar的顶部和上面bar的底部没有重叠,两个实验组的差异必定是显著的(5%的显著水平)。因此我们会说,这2个组间存在显著差别。如果我们做t-test,结果会验证这个发现。这种方法对超越2个组的情况就不那么精确了。因为需要多次比较(比如,组1和组2,组2和组3,组1和组3),但是至少能给出差别的粗略指示。在表格中展示CI的时候,你应当给出确实的数值(乘以1.96而不是2)。
总结
SD反应的是数据点围绕均值的分布状况,是数据报告中必须有的指标。SE则反应了均值稳定的情况,是研究重复多次后,期望失掉的差异水平。SE自身不传递很多有用的信息,主要功能是计算95%和99%的CI。 CI是显著性检验的补充,反应的是实在的均值或者均值差别的范围。
一些期刊已把显著性检验抛弃了,CI取而代之。这可能走过头了。因为这两种方法各有优点,也均会被误用。比如,一项小样本研究可能发现控制组和实验组间的差别显著(0.05的显著水平)。如果在结果展示加上CI,读者会很轻易看到CI十分宽,说明对差别的估计是很粗糙的。与之相反,大量鼓吹的被二手烟影响的人数,实际上不是一个均值估计。最好的估计是0,它有很宽的CI,报道的却只是CI的上限。
总之,SD、显著性检验,95%或者99% 的CI,均应当加在报告中,有利于读者理解研究结果。它们均有信息量,能相互补充,而不是替代。相反,“裸”的SE的并不能告知我们什么信息,多占据了一些篇幅和空间而已。
文章结束给大家分享下程序员的一些笑话语录: 问路
有一个驾驶热气球的人发现他迷路了。他降低了飞行的高度,并认出了地面 上的一个人。他继续下降高度并对着那个人大叫,“打扰一下,你能告诉我我 在哪吗?”
下面那个人说:“是的。你在热气球里啊,盘旋在 30 英尺的空中”。
热气球上的人说:“你一定是在 IT 部门做技术工作”。
“没错”,地面上的人说到,“你是怎么知道的?”
“呵呵”,热气球上的人说,“你告诉我的每件事在技术上都是对的,但对都没 有用”。
地面上的人说,“你一定是管理层的人”。
“没错”,热气球上的人说,“可是你是怎么知道的?”
“呵呵”,地面上的那人说到,“你不知道你在哪里,你也不知道你要去哪,你 总希望我能帮你。你现在和我们刚见面时还在原来那个地方,但现在却是我 错了”。