Oracle笔记(六) 多表查询
本次预计讲解的知识点
1、 多表查询的操作、限制、笛卡尔积的问题;
2、 统计函数及分组统计的操作;
3、 子查询的操作,并且结合限定查询、数据排序、多表查询、统计查询一起完成各个复杂查询的操作;
一、多表查询的基本概念
在之前所使用的查询操作之中,都是从一张表之中查询出所需要的内容,那么如果现在一个查询语句需要显示多张表的数据,则就必须应用到多表查询的操作,而多表查询的语法如下:
SELECT [DISTINCT] * | 字段 [别名] [,字段 [别名] ,…] FROM 表名称 [别名], [表名称 [别名] ,…] [WHERE 条件(S)] [ORDER BY 排序字段 [ASC|DESC] [,排序字段 [ASC|DESC] ,…]];
但是如果要进行多表查询之前,首先必须先查询出几个数据 —— 雇员表和部门表中的数据量,这个操作可以通过COUNT()函数完成。
范例:查询emp表中的数据量 ——返回了14条记录
SELECT COUNT(*) FROM emp;
范例:查询dept表中的数据量 ——4条记录
SELECT COUNT(*) FROM dept;
额外补充一点:何为经验?
在日后的开发之中,很多人都肯定要接触到许多新的数据库和数据表,那么在这种时候有两种做法:
- 做法一:新人做法,上来直接输入以下的命令:
SELECT * FROM 表名称;
如果此时数据量较大的话,一上无法浏览数据,二有可能造成系统的死机;
- 做法二:老人做法,先看一下有多少条记录:
SELECT COUNT(*) FROM 表名称;
如果此时数据量较小,则可以查询全部数据,如果数据量较大则不能直接使用SELECT查询。
现在确定好了emp和dept表中的记录之后,下面完成一个基本的多表查询:
SELECT * FROM emp, dept;
但是现在查询之后发现一共产生了56条记录 = 雇员表的14条记录 * 部门表的4条记录,之所以会造成这样的问题,主要都是由数据库的查询机制所决定的,例如,如下图所示。
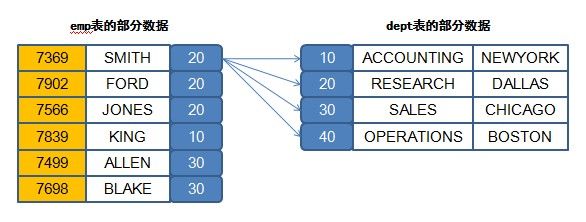
本问题在数据库的操作之中被称为笛卡尔积,就表示多张表的数据乘积的意思,但是这种查询结果肯定不是用户所希望的,那么该如何去掉笛卡尔积呢?
最简单的方式是采用关联字段的形式,emp表和dept表之间现在存在了deptno的关联字段,所以现在可以从这个字段上的判断开始。
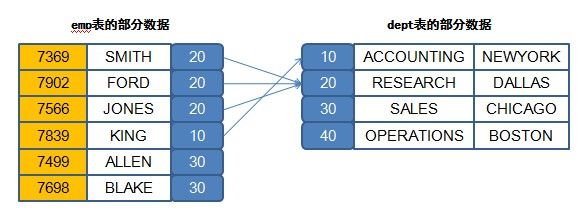
当在查询之中,不同的表中有了相同字段名称的时候,访问这些字段必须加上表名称,即“表.字段”。
SELECT * FROM emp WHERE emp.deptno=dept.deptno;
此时的查询结果之中已经消除了笛卡尔积,但是现在只属于显示上的消除,而真正笛卡尔积现在依然存在,因为数据库的操作机制就属于逐行的进行数据的判断,那么如果按照这个思路理解的话,现在假设两张表的数据量都很大的话,那么使用这种多表查询的性能。
范例:以sh用户的大数据表为例
SELECT COUNT(*) FROM sales, costs WHERE sales.prod_id=costs.prod_id;
这两张表即便消除了笛卡尔积的显示,但是本身也会有笛卡尔积的问题,所以最终的查询结果会很慢显示,甚至是不显示,所以通过这道程序一定要记住,多表查询的性能是很差的,当然,性能差是有一个前提的:数据量大。
但是以上的程序也存在一个问题,在之前访问表中字段的时候使用的是“表.字段”名称,那么如果说现在假设表名称很长,例如“yinhexi_diqiu_yazhou_zhongguo_beijing_xicheng_ren”,所以一般在进行多表查询的时候往往都会为表起一个别名,通过别名.字段的方式进行查询。
SELECT * FROM emp e, dept d WHERE e.deptno=d.deptno;
范例:查询出每一位雇员的编号、姓名、职位、部门名称、位置
1、确定所需要的数据表:
- emp表:可以查询出雇员的编号、姓名、职位;
- dept表:可以查询出部门名称和位置;
2、确定表的关联字段:emp.deptno=dept.deptno;
第一步:查询出每一位雇员的编号、姓名、职位
SELECT e.empno, e.ename, e.job FROM emp e;
第二步:为查询中引入部门表,同时需要增加一个消除笛卡尔积的条件
SELECT e.empno, e.ename, e.job, d.dname, d.loc FROM emp e, dept, d WHERE e.deptno=d.deptno;
以后遇到问题,发现没有解决问题的思路,就按照上面的步骤进行,慢慢的分析解决,因为多表查询不可能一次性全部写出,需要逐步分析的。
范例:要求查询出每一位雇员的姓名、职位、领导的姓名。
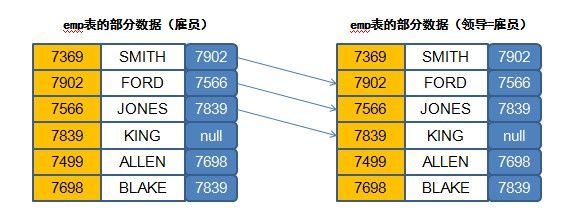
现在肯定要准备出两个emp表,所以这个时候可以称为emp表的自身关联,按照之前的分析如下:
1、确定所需要的数据表:
- emp表(雇员):取得雇员的姓名、职位、领导编号;
- emp表(领导):取得雇员的姓名(领导的姓名);
2、确定关联字段:emp.mgr=memp.empno(雇员的领导编号 = 领导(雇员)的雇员编号)
第一步:查询每一位雇员的姓名、职位
SELECT e.ename, e.job FROM emp e;
第二步:查询领导信息,加入自身关联
SELECT e.ename, e.job, m.ename FROM emp e, emp m WHERE e.mgr=m.empno;
此时的查询结果之中缺少了“KING”的记录,因为KING没有领导,而要想解决这个问题,就需要等待之后讲解的左、右连接的问题了。
范例:查询出每个雇员的编号、姓名、基本工资、职位、领导的姓名、部门名称及位置。
1、确定所需要的数据表:
- emp表:每个雇员的编号、姓名、基本工资、职位;
- emp表(领导):领导的姓名;
- dept表:部门的名称及位置。
2、确定已知的关联字段:
- 雇员和部门:emp.deptno=dept.deptno;
- 雇员和领导:emp.mgr=memp.empno;
第一步:查询出每个雇员的编号、姓名、基本工资、职位
SELECT empno, ename, sal, job FROM emp;
第二步:加入领导的信息,引入自身关联,同时增加消除笛卡尔积的条件
SELECT e.empno, e.ename, e.sal, e.job, m.ename FROM emp e, emp m WHERE e.mgr=m.empno;
第三步:加入部门的信息,引入dept表,既然有新的表进来,则需要继续增加消除笛卡尔积的条件
SELECT e.empno, e.ename, e.sal, e.job, m.ename, d.dname, d.loc FROM emp e, emp m, dept d WHERE e.mgr=m.empno AND e.deptno=d.deptno;
所以以后的所有类似的问题最好都能够按照如上的方式编写,形成自己的思路。
思考题:现在要求查询出每一个雇员的编号、姓名、工资、部门名称、工资所在公司的工资等级。
1、确定所需要的数据表:
- emp表:雇员的编号、姓名、工资;
- dept表:部门名称;
- salgrade表:工资等级;
2、确定已知的关联字段:
- 雇员和部门:emp.deptno=dept.deptno;
- 雇员和工资等级:emp.sal BETWEEN salgrade.losal AND salgrade.hisal;
第一步:查询出每一个雇员的编号、姓名、工资
SELECT e.empno, e.ename, e.sal FROM emp e;
第二步:引入部门表,同时增加一个消除笛卡尔积的条件
SELECT e.empno, e.ename, e.sal, d.dname FROM emp e, dept d WHERE e.deptno=d.deptno;
第三步:引入工资等级表,继续增加消除笛卡尔积的条件
SELECT e.empno, e.ename, e.sal, d.dname, s.grade FROM emp e, dept d, salgrade s WHERE e.deptno=d.deptno AND e.sal BETWEEN s.losal AND s.hisal;
如果现在有如下的进一步要求:将每一个工资等级替换成具体的文字信息,例如:
1 替换成 第五等工资、2 替换成 第四等工资、3 替换成 第三等工资,依次类推 --> 依靠DECODE()实现
SELECT e.empno, e.ename, e.sal, d.dname DECODE(s.grade,1,’第五等工资’,2,’第四等工资’,3,’第三等工资’,4,’第二等工资’,5,’第一等工资’) gradeinfo FROM emp e, dept d, salgrade s WHERE e.deptno=d.deptno AND e.sal BETWEEN s.losal AND s.hisal;
以后的所有的题目都按照类似的方式分析,只要是表关联,肯定有关联字段,用于消除笛卡尔积,只是这种关联字段需要根据情况使用不同的限定符号。
二、左、右连接
关于左、右连接指的是查询判断条件的参考方向,例如,下面有如下查询:
SELECT * FROM emp e, dept d WHERE e.deptno=d.deptno;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO DEPTNO DNAME LOC
---------- ---------- --------- ---------- -------------- ---------- ---------- ---------- ---------
7782 CLARK MANAGER 7839 09-6月 -81 2450 10 10 ACCOUNTING NEW YORK
7839 KING PRESIDENT 17-11月-81 5000 10 10 ACCOUNTING NEW YORK
7934 MILLER CLERK 7782 23-1月 -82 1300 10 10 ACCOUNTING NEW YORK
7369 SMITH CLERK 7902 17-12月-80 800 20 20 RESEARCH DALLAS
7876 ADAMS CLERK 7788 23-5月 -87 1100 20 20 RESEARCH DALLAS
7902 FORD ANALYST 7566 03-12月-81 3000 20 20 RESEARCH DALLAS
7788 SCOTT ANALYST 7566 19-4月 -87 3000 20 20 RESEARCH DALLAS
7566 JONES MANAGER 7839 02-4月 -81 2975 20 20 RESEARCH DALLAS
7499 ALLEN SALESMAN 7698 20-2月 -81 1600 300 30 30 SALES CHICAGO
7698 BLAKE MANAGER 7839 01-5月 -81 2850 30 30 SALES CHICAGO
7654 MARTIN SALESMAN 7698 28-9月 -81 1250 1400 30 30 SALES CHICAGO
7900 JAMES CLERK 7698 03-12月-81 950 30 30 SALES CHICAGO
7844 TURNER SALESMAN 7698 08-9月 -81 1500 0 30 30 SALES CHICAGO
7521 WARD SALESMAN 7698 22-2月 -81 1250 500 30 30 SALES CHICAGO
已选择14行。
部门一共有四个,但是现在只返回了三个部门的信息,缺少40部门,因为在雇员表之中没有一条记录是属于40部门的,所以现在不会显示40部门的信息,即:现在的查询以emp表为参考,那么如果说现在非要显示40部门呢?就必须改变这种参考的方向,就需要用使用左、右连接。
SELECT * FROM emp e, dept d WHERE e.deptno(+)=d.deptno;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO DEPTNO DNAME LOC
---------- ---------- --------- ---------- -------------- ---------- ---------- ---------- ---------
7782 CLARK MANAGER 7839 09-6月 -81 2450 10 10 ACCOUNTING NEW YORK
7839 KING PRESIDENT 17-11月-81 5000 10 10 ACCOUNTING NEW YORK
7934 MILLER CLERK 7782 23-1月 -82 1300 10 10 ACCOUNTING NEW YORK
7369 SMITH CLERK 7902 17-12月-80 800 20 20 RESEARCH DALLAS
7876 ADAMS CLERK 7788 23-5月 -87 1100 20 20 RESEARCH DALLAS
7902 FORD ANALYST 7566 03-12月-81 3000 20 20 RESEARCH DALLAS
7788 SCOTT ANALYST 7566 19-4月 -87 3000 20 20 RESEARCH DALLAS
7566 JONES MANAGER 7839 02-4月 -81 2975 20 20 RESEARCH DALLAS
7499 ALLEN SALESMAN 7698 20-2月 -81 1600 300 30 30 SALES CHICAGO
7698 BLAKE MANAGER 7839 01-5月 -81 2850 30 30 SALES CHICAGO
7654 MARTIN SALESMAN 7698 28-9月 -81 1250 1400 30 30 SALES CHICAGO
7900 JAMES CLERK 7698 03-12月-81 950 30 30 SALES CHICAGO
7844 TURNER SALESMAN 7698 08-9月 -81 1500 0 30 30 SALES CHICAGO
7521 WARD SALESMAN 7698 22-2月 -81 1250 500 30 30 SALES CHICAGO
40 OPERATIONS BOSTON
已选择15行。
现在发现40部门出现了,所以发现参考的方向已经改变了,而“(+)”就用于左、右连接的更改,这种符号有以下两种使用情况:
- (+)=:放在了等号的左边,表示的是右连接;
- =(+):放在了等号的右边,表示的是左连接;
但是不用去刻意的区分是左还是右,只是根据查询结果而定,如果发现有些需要的数据没有显示出来,就使用此符号更改连接方向。
范例:查询每个雇员的姓名和领导的姓名
SELECT e.ename, e.job, m.ename FROM emp e, emp m WHERE e.mgr=m.empno(+);
可是这种符号是Oracle数据库自己所独有的,其他数据库不能使用。
三、SQL:1999语法
除了以上的表连接操作之外,在SQL语法之中,也提供了另外一套用于表连接的操作SQL,格式如下:
SELECT table1.column,table2.column FROM table1 [CROSS JOIN table2]| [NATURAL JOIN table2]| [JOIN table2 USING(column_name)]| [JOIN table2 ON(table1.column_name=table2.column_name)]| [LEFT|RIGHT|FULL OUTER JOIN table2 ON(table1.column_name=table2.column_name)];
以上实际上是属于多个语法的联合,下面分块说明语法的使用。
1、交叉连接(CROSS JOIN):用于产生笛卡尔积
SELECT * FROM emp CROSS JOIN dept;
笛卡尔积本身并不是属于无用的内容,在某些情况下还是需要使用的。
2、自然连接(NATURAL JOIN):自动找到匹配的关联字段,消除掉笛卡尔积
SELECT * FROM emp NATURAL JOIN dept;
但是并不是所有的字段都是关联字段,设置关联字段需要通过约束指定;
3、JOIN…USING子句:用户自己指定一个消除笛卡尔积的关联字段
SELECT * FROM emp JOIN dept USING(deptno);
4、JOIN…ON子句:用户自己指定一个可以消除笛卡尔积的关联条件
SELECT * FROM emp JOIN dept ON(emp.deptno=dept.deptno);
5、连接方向的改变:
- 左(外)连接:LEFT OUTER JOIN…ON;
- 右(外)连接:RIGHT OUTER JOIN…ON;
- 全(外)连接:FULL OUTER JOIN…ON; --> 把两张表中没有的数据都显示
SELECT * FROM emp RIGHT OUTER JOIN dept ON(emp.deptno=dept.deptno);
在Oracle之外的数据库都使用以上的SQL:1999语法操作,所以这个语法还必须会一些(如果你一直使用的都是Oracle就可以不会了)。
再次强调:多表查询的性能肯定不高,而且性能一定要在大数据量的情况下才能够发现。
四、统计函数及分组查询
1、统计函数
在之前学习过一个COUNT()函数,此函数的功能可以统计出表中的数据量,实际上这个就是一个统计函数,而常用的统计函数有如下几个:
- COUNT():查询表中的数据记录;
- AVG():求出平均值;
- SUM():求和;
- MAX():求出最大值;
- MIN():求出最小值;
范例:测试COUNT()、AVG()、SUM()
统计出公司的所有雇员,每个月支付的平均工资及总工资。
SELECT MAX(sal),MIN(sal) FROM emp;
注意点:关于COUNT()函数
COUNT()函数的主要功能是进行数据的统计,但是在进行数据统计的时候,如果一张表中没有统计记录,COUNT()也会返回数据,只是这个数据是“0”。
SELECT COUNT(ename) FROM BONUS;
如果使用的是其他函数,则有可能返回null,但是COUNT()永远都会返回一个具体的数字,这一点以后在开发之中都会使用到。
2、分组查询
在讲解分组操作之前首先必须先明确一点,什么情况下可能分组,例如:
- 公司的所有雇员,要求男性一组,女性一组,之后可以统计男性和女性的数量;
- 按照年龄分组,18岁以上的分一组,18岁以下的分一组;
- 按照地区分组:北京人一组,上海人一组,四川一组;
这些信息如果都保存了数据库之中,肯定在数据的某一列上会存在重复的内容,例如:按照性别分组的时候,性别肯定有重复(男和女),按照年龄分组(有一个范围的重复),按照地区分组有一个地区的信息重复。
所以分组之中有一个不成文的规定:当数据重复的时候分组才有意义,因为一个人也可以一组(没什么意义)。
SELECT [DISTINCT] *|分组字段1 [别名] [,分组字段2 [别名] ,…] | 统计函数 FROM 表名称 [别名], [表名称 [别名] ,…] [WHERE 条件(s)] [GROUP BY 分组字段1 [,分组字段2 ,…]] [ORDER BY 排序字段 ASC | DESC [,排序字段 ASC | DESC]];
范例:按照部门编号分组,求出每个部门的人数,平均工资
SELECT deptno, COUNT(empno), AVG(sal) FROM emp GROUP BY deptno;
范例:按照职位分组,求出每个职位的最高和最低工资
SELECT job, MAX(sal), MIN(sal) FROM emp GROUP BY job;
但是现在一旦分组之后,实际上对于语法上就会出现了新的限制,对于分组有以下要求:
- 分组函数可以在没有分组的时候单独用使用,可是却不能出现其他的查询字段;
| 分组函数单独使用: |
SELECT COUNT(empno) FROM emp; |
| 错误的使用,出现了其他字段: |
SELECT empno,COUNT(empno) FROM emp; |
- 如果现在要进行分组的话,则SELECT子句之后,只能出现分组的字段和统计函数,其他的字段不能出现:
| 正确做法: |
SELECT job,COUNT(empno),AVG(sal) FROM emp GROUP BY job; |
| 错误的做法: |
SELECT deptno,job,COUNT(empno),AVG(sal) FROM emp GROUP BY job; |
- 分组函数允许嵌套,但是嵌套之后的分组函数的查询之中不能再出现任何的其他字段。
范例:按照职位分组,统计平均工资最高的工资
1、先统计出各个职位的平均工资
SELECT job,AVG(sal) FROM emp GROUP BY job;
2、平均工资最高的工资
SELECT MAX(AVG(sal)) FROM emp GROUP BY job;
范例:查询出每个部门的名称、部门的人数、平均工资
1、确定所需要的数据表:
- dept表:每个部门的名称;
- emp表:统计出部门的人数、平均工资;
2、确定已知的关联字段:emp.deptno=dept.deptno;
范例:将dept表和emp表的数据关联
SELECT d.dname,e.empno,e.sal FROM dept d, emp e WHERE d.deptno=e.deptno;
DNAME EMPNO SAL
-------------- ---------- ----------
ACCOUNTING 7782 2450
ACCOUNTING 7839 5000
ACCOUNTING 7934 1300
RESEARCH 7369 800
RESEARCH 7876 1100
RESEARCH 7902 3000
RESEARCH 7788 3000
RESEARCH 7566 2975
SALES 7499 1600
SALES 7698 2850
SALES 7654 1250
SALES 7900 950
SALES 7844 1500
SALES 7521 1250
已选择14行。
此时的查询结果中,可以发现在dname字段上显示出了重复的数据,按照之前对分组的理解,只要数据重复了,那么就有可能进行分组的查询操作,但是此时与之前的分组不太一样,之前的分组是针对于一张实体表进行的分组(emp、dept都属于实体表),但是对于以上的数据是通过查询结果显示的,所以是一张临时的虚拟表,但是不管是否是实体表还是虚拟表,只要是有重复,那么就直接进行分组。
SELECT d.dname,COUNT(e.empno),AVG(e.sal) FROM dept d, emp e WHERE d.deptno=e.deptno GROUP BY d.dname;
但是这个分组并不合适,因为部门一共有四个部门(因为现在已经引入了dept表,dept表存在了四个部门的信息),所以应该通过左右连接改变查询的结果。
SELECT d.dname,COUNT(e.empno),NVL(AVG(e.sal),0) FROM dept d, emp e WHERE d.deptno=e.deptno(+) GROUP BY d.dname;
之前的所有操作都是针对于单个字段分组的,而实际上分组操作之中也可以实现多字段分组。
范例:要求显示每个部门的编号、名称、位置、部门的人数、平均工资
1、确定所需要的数据表:
- dept表:每个部门的名称;
- emp表:统计出部门的人数、平均工资;
2、确定已知的关联字段:emp.deptno=dept.deptno;
范例:将emp表和dept表关联查询
SELECT d.deptno,d.dname,d.loc,e.empno,e.sal FROM dept d,emp e WHERE d.deptno=e.deptno(+);
DEPTNO DNAME LOC EMPNO SAL
---------- -------------- ------------- ---------- ----------
10 ACCOUNTING NEW YORK 7782 2450
10 ACCOUNTING NEW YORK 7839 5000
10 ACCOUNTING NEW YORK 7934 1300
20 RESEARCH DALLAS 7369 800
20 RESEARCH DALLAS 7876 1100
20 RESEARCH DALLAS 7902 3000
20 RESEARCH DALLAS 7788 3000
20 RESEARCH DALLAS 7566 2975
30 SALES CHICAGO 7499 1600
30 SALES CHICAGO 7698 2850
30 SALES CHICAGO 7654 1250
30 SALES CHICAGO 7900 950
30 SALES CHICAGO 7844 1500
30 SALES CHICAGO 7521 1250
40 OPERATIONS BOSTON
已选择15行。
此时存在了重复数据,而且这个重复的数据平均在了三列上(deptno,dname,loc),所以在分组上的GROUP BY子句中就可以写上三个字段:
SELECT d.deptno,d.dname,d.loc,COUNT(e.empno),NVL(AVG(e.sal),0) FROM dept d,emp e WHERE d.deptno=e.deptno(+) GROUP BY d.deptno,d.dname,d.loc;
以上就是多字段分组,但是不管是单字段还是多字段,一定要有一个前提,存在了重复数据。
范例:要求统计出每个部门的详细信息,并且要求这些部门的平均工资高于2000;
在以上程序的基础上完成开发,在之前唯一所学习的限定查询的语法只有WHERE子句,所以下面先使用WHERE完成要求。
SELECT d.deptno,d.dname,d.loc,COUNT(e.empno) mycount,NVL(AVG(e.sal),0) myavg FROM dept d,emp e WHERE d.deptno=e.deptno(+) AND AVG(e.sal)>2000 GROUP BY d.deptno,d.dname,d.loc;
现在出现了如下的错误提示:
WHERE d.deptno=e.deptno(+) AND AVG(e.sal)>2000
*
第 3 行出现错误:
ORA-00934: 此处不允许使用分组函数
本错误提示的核心意思就是在WHERE子句之中不能使用统计函数,之所以在WHERE子句之中不能使用,实际上跟WHERE子句的主要功能有关,WHERE的主要功能是从全部的数据之中取出部分数据。
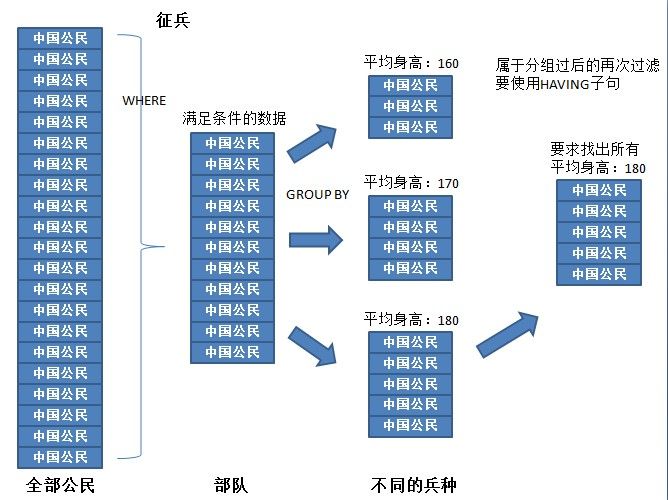
此时如果要对分组后的数据再次进行过滤,则使用HAVING子句完成,那么此时的SQL语法格式如下:
SELECT [DISTINCT] *|分组字段1 [别名] [,分组字段2 [别名] ,…] | 统计函数 FROM 表名称 [别名], [表名称 [别名] ,…] [WHERE 条件(s)] [GROUP BY 分组字段1 [,分组字段2 ,…]] [HAVING 分组后的过滤条件(可以使用统计函数)] [ORDER BY 排序字段 ASC | DESC [,排序字段 ASC | DESC]];
下面使用HAVING进行过滤。
SELECT d.deptno,d.dname,d.loc,COUNT(e.empno) mycount,NVL(AVG(e.sal),0) myavg FROM dept d,emp e WHERE d.deptno=e.deptno(+) GROUP BY d.deptno,d.dname,d.loc HAVING AVG(sal)>2000;
注意点:WHERE和HAVING的区别
- WHERE:是在执行GROUP BY操作之前进行的过滤,表示从全部数据之中筛选出部分的数据,在WHERE之中不能使用统计函数;
- HAVING:是在GROUP BY分组之后的再次过滤,可以在HAVING子句中使用统计函数;
思考题:显示非销售人员工作名称以及从事同一工作雇员的月工资的总和,并且要满足从事同一工作的雇员的月工资合计大于$5000,输出结果按月工资的合计升序排列:
第一步:查询出所有的非销售人员的信息
SELECT * FROM emp WHERE job<>'SALESMAN';
第二步:按照职位进行分组,并且使用SUM函数统计
SELECT job,SUM(sal) FROM emp WHERE job<>'SALESMAN' GROUP BY job;
第三步:月工资的合计是通过统计函数查询的,所以现在这个对分组后的过滤要使用HAVING子句完成
SELECT job,SUM(sal) FROM emp WHERE job<>'SALESMAN' GROUP BY job HAVING SUM(sal)>5000;
第四步:按照升序排列
SELECT job,SUM(sal) sum FROM emp WHERE job<>'SALESMAN' GROUP BY job HAVING SUM(sal)>5000 ORDER BY sum ASC;
以上的题目就融合分组操作的大部分语法的使用,而且以后遇到问题,要慢慢分析。
五、子查询
子查询 = 简单查询 + 限定查询 + 多表查询 + 统计查询的综合体;
在之前强调过多表查询不建议大家使用,因为性能很差,但是多表查询最有利的替代者就是子查询,所以子查询在实际的开发之中使用的相当的多;
所谓的子查询指的就是在一个查询之中嵌套了其他的若干查询,嵌套子查询之后的查询SQL语句如下:
SELECT [DISTINCT] *|分组字段1 [别名] [,分组字段2 [别名] ,…] | 统计函数 ,( SELECT [DISTINCT] *|分组字段1 [别名] [,分组字段2 [别名] ,…] | 统计函数 FROM 表名称 [别名], [表名称 [别名] ,…] [WHERE 条件(s)] [GROUP BY 分组字段1 [,分组字段2 ,…]] [HAVING 分组后的过滤条件(可以使用统计函数)] [ORDER BY 排序字段 ASC | DESC [,排序字段 ASC | DESC]]) FROM 表名称 [别名], [表名称 [别名] ,…] ,( SELECT [DISTINCT] *|分组字段1 [别名] [,分组字段2 [别名] ,…] | 统计函数 FROM 表名称 [别名], [表名称 [别名] ,…] [WHERE 条件(s)] [GROUP BY 分组字段1 [,分组字段2 ,…]] [HAVING 分组后的过滤条件(可以使用统计函数)] [ORDER BY 排序字段 ASC | DESC [,排序字段 ASC | DESC]]) [WHERE 条件(s) ( SELECT [DISTINCT] *|分组字段1 [别名] [,分组字段2 [别名] ,…] | 统计函数 FROM 表名称 [别名], [表名称 [别名] ,…] [WHERE 条件(s)] [GROUP BY 分组字段1 [,分组字段2 ,…]] [HAVING 分组后的过滤条件(可以使用统计函数)] [ORDER BY 排序字段 ASC | DESC [,排序字段 ASC | DESC]])] [GROUP BY 分组字段1 [,分组字段2 ,…]] [HAVING 分组后的过滤条件(可以使用统计函数)] [ORDER BY 排序字段 ASC | DESC [,排序字段 ASC | DESC]];
理论上子查询可以出现在查询语句的任意位置上,但是从个人而言,子查询出现在WHERE和FROM子句之中较多;
以下的使用特点为个人总结,不是官方声明的:
- WHERE:子查询一般只返回单行列、多行单列、单行多列的数据;
- FROM:子查询返回的一般是多行的数据,当作一张临时表出现。
范例:要求查询出工资比SMITH还要高的全部雇员信息
要想完成本程序,首先必须要知道SMITH的工资是多少:
SELECT sal FROM emp WHERE ename='SMITH';
由于此时返回的是单列的数据,所以这个子句查询可以在WHERE中出现。
SELECT * FROM emp WHERE sal>( SELECT sal FROM emp WHERE ename='SMITH');
范例:要求查询出高于公司平均工资的全部雇员信息
公司的平均工资应该使用AVG()函数求出。
SELECT AVG(sal) FROM emp;
此时数据的返回结果是单行单列的数据,在WHERE之中出现。
SELECT * FROM emp WHERE sal>( SELECT AVG(sal) FROM emp);
以上所返回的是单行单列,但是在子查询之中,也可以返回单行多列的数据,只是这种子查询很少出现。
范例:子查询返回单行多列数据
SELECT * FROM emp WHERE (job,sal)=( SELECT job,sal FROM emp WHERE ename='ALLEN');
如果现在的子查询返回的是多行单列数据的话,这个时候就需要使用三种判断符判断了:IN、ANY、ALL;
1、 IN操作符:用于指定一个子查询的判断范围
这个操作符的使用实际上与之前讲解的IN是一样的,唯一不同的是,里面的范围由子查询指定了。
SELECT * FROM emp WHERE sal in ( SELECT sal FROM emp WHERE job='MANAGER');
但是在使用IN的时候还要注意NOT IN的问题,如果使用NOT IN操作,在子查询之中,如果有一个内容是null,则不会查询出任何的结果。
2、 ANY操作符:与每一个内容想匹配,有三种匹配形式
- =ANY:功能与IN操作符是完全一样的;
SELECT * FROM emp WHERE sal=ANY ( SELECT sal FROM emp WHERE job='MANAGER');
- >ANY:比子查询中返回记录最小的还要大的数据;
SELECT * FROM emp WHERE sal>ANY ( SELECT sal FROM emp WHERE job='MANAGER');
- <ANY:比子查询中返回记录的最大的还要小;
SELECT * FROM emp WHERE sal<ANY ( SELECT sal FROM emp WHERE job='MANAGER');
3、 ALL操作符:与每一个内容相匹配,有两种匹配形式:
- >ALL:比子查询中返回的最大的记录还要大
SELECT * FROM emp WHERE sal>ALL ( SELECT sal FROM emp WHERE job='MANAGER');
- <ALL:比子查询中返回的最小的记录还要小
SELECT * FROM emp WHERE sal<ALL ( SELECT sal FROM emp WHERE job='MANAGER');
以上的所有子查询都是在WHERE子句中出现的,那么下面再来观察在FROM子句中出现的查询,这个子查询一般返回的是多行多列的数据,当作一张临时表的方式来处理。
范例:查询出每个部门的编号、名称、位置、部门人数、平均工资
- 回顾:最早的时候使用的是多字段分组统计完成的:
SELECT d.deptno,d.dname,d.loc,COUNT(e.empno),AVG(e.sal) FROM emp e,dept d WHERE e.deptno(+)=d.deptno GROUP BY d.deptno,d.dname,d.loc;
这个时候实际上是产生了笛卡尔积,一共产生了56条记录;
- 新的解决方案:通过子查询完成,所有的统计查询只能在GROUP BY中出现,所以在子查询之中负责统计数据,而在外部的查询之中,负责将统计数据和dept表数据相统一。
SELECT d.deptno,d.dname,d.loc,temp.count,temp.avg FROM dept d,( SELECT deptno dno,COUNT(empno) count,AVG(sal) avg FROM emp GROUP BY deptno) temp WHERE d.deptno=temp.dno(+);
现在的程序中所操作的数据量:
- 子查询中统计的记录是14条记录,最终统计的显示结果是3条记录;
- dept表之中一共有4条记录;
- 如果现在产生笛卡尔积的话只有12条记录,再加上雇员的14条记录,一共才26条记录;
通过如上的分析,可以发现,使用子查询的确要比使用多表查询更加节省性能,所以在开发之中子查询出现是最多的,而且在给出一个不成文的规定:大部分情况下,如果最终的查询结果之中需要出现SELECT子句,但是又不能直接使用统计函数的时候,就在子查询中统计信息,即:有复杂统计的地方大部分都需要子查询。