上篇进行过Hive/Impala/集算器的分组计算的性能测试,本篇进行关联计算的性能测试及结果说明。
窄表的关联计算测试
数据样本
被关联表p_narrow。
列数:11
行数:5亿
文本状态下所占空间:120.6G。
数据结构: personid int,name string,sex int,cityid int,birthday int,degree int,col1 string,col2 int,col3
int,col4 int,col5 string
维表d_narrow
列数:9
行数:1000万行
文本状态下所占空间:563M。
数据结构:id int, parentid int, col1 int, col2 int, col3 int, col4 int, col5 int, col6 int, col7 int
说明:
1、被关联表:类似于SQL中Join左侧的表,行数较多。比如订单表。
2、维表:类似于SQL中join右侧的表,行数较少。比如客户ID-客户名表。
测试案例
Hive:select sum(p_narrow.col3), count(p_narrow.col5), sum(d_narrow.col7), d_narrow.id%10000 from p_narrow join d_narrow on d_narrow.id=p_narrow.col7 group by d_narrow.id%10000
Impala:select sum(p_narrow.col3), count(p_narrow.col5), sum(d_narrow.col7), d_narrow.id%10000 from p_narrow join d_narrow on d_narrow.id=p_narrow.col7 group by d_narrow.id%10000
集算器: 代码分为三部分,分别是:汇总机程序、节点机主程序、节点机子程序。
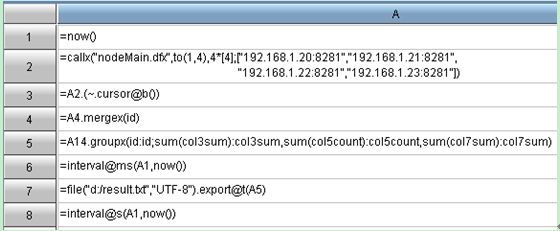

测试结果:

宽表的关联计算测试
数据样本
被关联表p
列数:106
行数:6000万行
文本状态下所占空间:127.9G。
数据结构:personid int,name string,sex int,cityid int,birthday int,degree int,col1 int,col2 int,col3 int,col4 int,col5 int,col6 int,col7 int,col8 int,col9 int,col10 int,col11 int,col12 int,col13 int,col14 int,col15 int,col16 int,col17 int,col18 int,col19 int,col20 int,col21 int,col22 int,col23 int,col24 int,col25 int,col26 int,col27 int,col28 int,col29 int,col30 int,col31 int,col32 int,col33 int,col34 int,col35 int,col36 int,col37 int,col38 int,col39 int,col40 int,col41 int,col42 int,col43 int,col44 int,col45 int,col46 int,col47 int,col48 int,col49 int,col50 int,col51 int,col52 int,col53 int,col54 int,col55 int,col56 int,col57 int,col58 int,col59 int,col60 int,col61 int,col62 int,col63 int,col64 int,col65 int,col66 int,col67 int,col68 int,col69 int,col70 int,col71 int,col72 int,col73 int,col74 int,col75 int,col76 int,col77 int,col78 int,col79 int,col80 int,col81 int,col82 int,col83 int,col84 string,col85 string,col86 string,col87 string,col88 string,col89 string,col90 string,col91 string,col92 string,col93 string,col94 string,col95 string,col96 string,col97 string,col98 string,col99 string,col100 string
维表d
列数:102
行数:1000万行
文本状态下所占空间:6.8G
数据结构:id int, parentid int,col1 int,col2 int,col3 int,col4 int,col5 int,col6 int,col7 int,col8 int,col9 int,col10 int,col11 int,col12 int,col13 int,col14 int,col15 int,col16 int,col17 int,col18 int,col19 int,col20 int,col21 int,col22 int,col23 int,col24 int,col25 int,col26 int,col27 int,col28 int,col29 int,col30 int,col31 int,col32 int,col33 int,col34 int,col35 int,col36 int,col37 int,col38 int,col39 int,col40 int,col41 int,col42 int,col43 int,col44 int,col45 int,col46 int,col47 int,col48 int,col49 int,col50 int,col51 int,col52 int,col53 int,col54 int,col55 int,col56 int,col57 int,col58 int,col59 int,col60 int,col61 int,col62 int,col63 int,col64 int,col65 int,col66 int,col67 int,col68 int,col69 int,col70 int,col71 int,col72 int,col73 int,col74 int,col75 int,col76 int,col77 int,col78 int,col79 int,col80 int,col81 int,col82 int,col83 int,col84 int,col85 int,col86 int,col87 int,col88 int,col89 int,col90 int,col91 int,col92 int,col93 int,col94 int,col95 int,col96 int,col97 int,col98 int,col99 int,col100 int
说明:
1、被关联表:类似于SQL中Join左侧的表,行数较多。比如订单表。
2、维表:类似于SQL中join右侧的表,行数较少。比如客户ID-客户名表。
测试案例
Hive:select sum(p.col3), count(p.col5), sum(d.col7), d.id%10000 from p join d on d.id=p.col7 group by
d.id%10000
Impala:select sum(p.col3), count(p.col5), sum(d.col7), d.id%10000 from p join d on d.id=p.col7 group by d.id%10000
集算器: 代码分为三部分,分别是:汇总机程序、节点机主程序、节点机子程序。
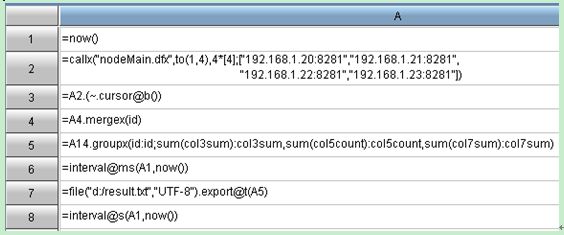
测试结果

小结
A、窄表的分组汇总
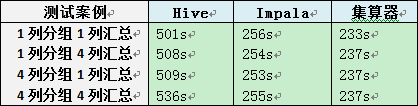
1、Impala、集算器的性能明显好于Hive,快一倍或更多。
2、Impala与集算器略有差异,但并不明显。
3、分组列数和汇总列数对三种解决方案的性能影响都不大。
B、宽表的分组汇总
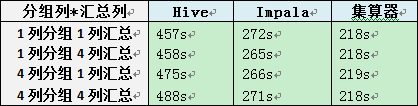
1、Impala、集算器的性能明显好于Hive,快一倍或更多。
2、Impala与集算器略有差异,但并不明显。
3、分组列数和汇总列数对三种解决方案的性能影响都不大。
4、与窄表相比,表的列数对性能影响不大,整表体积对性能有直接影响。Impala在宽表时性能略有下降而Hive和集算器则略有上升。
C、窄表的关联计算![]()
1、Impala、集算器性能明显强于Hive,接近3倍。
2、Implala比集算器略强,但差异并不明显。
D、宽表的关联计算![]()
1、Impala、集算器性能明显强于Hive,接近3倍。
2、Implala比集算器快1秒,基本可以认为两者性能一致。
测试结果解读
Hive的性能较差,是由于它的底层是MapReduce,而MapReduce是通过外存文件实现计算节点间的数据交换,这就导致大量的硬盘IO时间。Implala和集算器可以通过内存来直接交换中间计算结果,性能因此更好。
通过文件来交换数据并非没有好处,事实上在不稳定的大集群环境中,文件交换可以保证中间计算结果的安全。Impala只支持直接交换,Hive只支持文件交换,集算器两者皆可,由程序员自由决定。
分组汇总时集算器比Impala的性能略强,这主要是由于集算器除了支持HDFS,还支持直接读写本地硬盘。而Impala必须经过HDFS才能访问硬盘,多了一层控制自然会慢。
但在关联计算中,我们可以看到集算器和Impala的数据反过来了,Impala的性能等于或略强于集算器。这是因为Impala虽然要经过HDFS来访问硬盘,但是它也会生成本地代码来优化计算性能,比集算器使用的JAVA虚拟机性能要高。可以猜想,分组汇总时更强调数据读取,而关联计算时更强调计算,因此产生了关联计算时Impala反超集算器的现象。
分组列数和汇总列数对分组汇总的性能影响都不大,这是由于本案例的算法比较简单,时间大部分消耗在硬盘读写而不是数据计算上。不过Hive和Implala不是集算器这类过程性语言,太复杂的运算也难以支持,这种CPU空耗属于正常现象。
另外我们将计算结果限制为一万条,这是由于Impala对内存的依赖较大太,大的结果集会导致内存溢出。Hive只支持外存计算因此不存在内存限制。集算器修改算法后也可以实现外存计算,不过性能会有所下降。