在进行文本处理时,经常会遇到对大文件进行集合运算的情况,比如找出两个文件不同的行数据。用命令行的grep\cat命令处理此类问题时,写法很简单,但效率太低,用高级语言处理此类问题虽然可以获得较高的运行效率,但代码编写复杂度确相当高。
用集算器来进行大文件的集合运算和多线程并行计算,不仅代码简洁,而且性能优异。
文件file1.txt和file2.txt存储着大量的字符串,找出两者共同的行数据(交集)。部分数据如下:

两个大文件
两个文件都超出内存时,可以使用集算器的游标归并来实现交集运算,代码如下:

A1、B1:以游标的形式打开文件。函数cursor并不会将数据全部读入内存,而是以游标(流)的方式打开文件,因此不会占据内存空间。函数cursor使用了默认参数,即:以tab为列分割符读入全部的字段,自动命名为_1、_2、_3…_n。对于本案例来说,只有一个字段_1。
A2=[A1.sortx(_1),B1.sortx(_1)].merge@xi(_1)
使用归并算法找出两者共同的行数据,也就是求交集。归并算法要求数据有序,因此要先用sortx函数对游标进行排序,即A1.sortx(_1)和A2.sortx(_1),这里的_1是文件默认字段名。函数merge表示对多组数据进行归并(本案例是两组),没有参数选项时,可以对内存中的集合进行归并,使用参数选项@x表示对游标进行归并,使用参数选项@i表示归并的结果是交集。
注意,A2的运算结果仍然是游标,仍然不会占据内存空间。只有遇到export/fetch/groups等函数时,集算器引擎才会分配合适的内存缓冲区,并将前面的游标计算自动转化为内存计算。
A3=file("E:\\result.txt").export(A2)
将游标A2写入文件。函数export既支持将内存数据写入文件,也支持将游标写入文件。这里使用了默认参数,即:无列名,列分割符为Tab,覆盖文件而不是追加,写成文本文件而不是二进制。打开result.txt,可以看到部分数据如下:

值得注意的是,前面的集算器代码是分步计算,事实上可以将它们合为一句:A1=file("e:\\result.txt").export([file("E:\\file1.txt").cursor().sortx(_1),file("E:\\file2.txt").cursor().sortx(_1)].merge@xi(_1)).
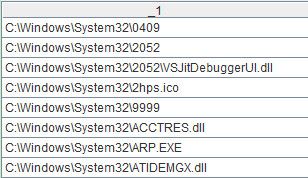
另外,本案例只实现了交集,其实还有并集、合集、差集,只需要修改单元格A2中函数merge的选项即可。比如,将file1.txt和file2.txt合并,并去除两者重复的成员(并集)。求并集应当使用函数选线@u,代码是:[A1.sortx(_1),B1.sortx(_1)].merge@xu(_1),并集的结果如下:
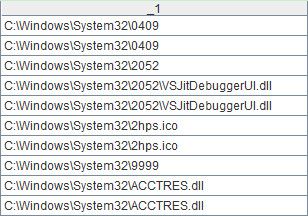
如果不去除重复成员(和集),则代码是:[A1.sortx(_1),B1.sortx(_1)].merge@x(_1),这也是归并的本意,计算结果如下:
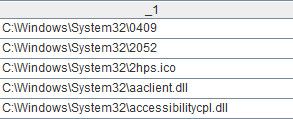
如果想找到在file1.txt,但不在file2.txt中的数据(差集),则应当使用函数选项@d,代码是[A1.sortx(_1),B1.sortx(_1)].merge@xd(_1),计算结果如下:

注意:差集不满足交换律,所以想获得在file2.txt,但不在file1.txt的数据时,应当使用代码[B1.sortx(_1),A1.sortx(_1)].merge@xd(_1),计算结果如下:

文件一大一小
如果只有一个文件超出内存,那就可以将小文件读入内存,再用Hash查找的方法来进行集合运算,这样可以显著提高效率。集算器代码如下:
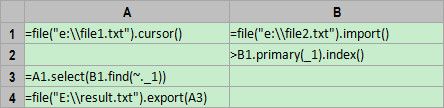
A1:用游标的方式打开文件。
A2=file("e:\\file2.txt").import(),这句代码直接将小文件file2.txt读入内存。函数import和cursor类似,默认的字段名也是_1、_2。在IDE中点击B1可以看到当前格的计算结果:
B2>B1.primary(_1).index()
上述代码用来给B1设置主键,并建立Hash索引,这样可以大大提高查询速度。B1和B2可以合为一句:B1=file("E:\\ file2.txt").import().primary(_1).index().
A3=A1.select(B1.find(~._1))
这句代码用来查询出游标A1和B1相同的数据,即求交集。函数select用来执行查询,符合条件的数据将被取出。函数select内可以使用~来代表当前记录。
查询条件是B1.find(~._1),这表示从B1中找到A1中当前记录的_1字段。
注意,这句代码的计算结果仍然是游标。
A4=file("E:\\result.txt").export(A3),这句代码将最终计算结果写入文件。
计算差集时,可以将A3单元格中的代码改成A1.select(!B1.find(~._1)),也就是从A1中找出不在B1里的那些行数据。
计算file1和file2的并集时,可以先计算出file1和file2的差集,再和file2做合并。

A4格的表达式[A3,B1.cursor()].conj@x(),函数conj可以进行多个集合的合并(合集),比如[[1,2,3],[2,3],[]]=[1,2,3,2,3]。函数选项@x可以合并多个游标里的数据。由于B1不是游标,因此要用函数cursor将B1变换为游标,即B1.cursor(),这要比从文件里再读一遍来得快。
一大一小文件并行计算
前面的算法是串行,改成并行可以进一步提高性能,具体做法是用多个线程并行读取文件,每个线程都用游标访问文件的一部分,并同时进行集合计算,最后再将每个游标的结果合并。
在相同的硬件环境下对2.77G大文件和39.93M的小文件进行测试,串行时平均耗时85秒,并行时平均耗时47秒,性能提高接近一倍。由于集合运算的复杂度较小,瓶颈会产生在硬盘读取上,如果进一步加大运算的复杂度,性能提升的幅度将会更大。
集算器并行计算的代码如下:
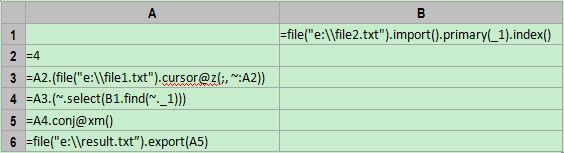
B1:将小文件读入内存,设置主键并创建索引。
A2=4,A2是分段数量,即将文件分成4段。分段数量不宜过多,一般不能超过CPU的核数,否则会排队等待,而没有实质提速效果。具体的最大并行数可以在环境选项中配置。
A3=A2.(file("e:\\file1.txt").cursor@z(;, ~:A2))
上面的代码按照分段数量生成4个游标。其中A2.(express)表示按照括号内的表达式依次计算A2的成员,括号内可用“~”来表示当前成员。A2一般是集合,比如["file1", " file2"]或[2,3],A2如果是从1开始的连续数字,比如[1,2,3,4],则可以简写成4.( express),案例中的代码就是这种情况。
括号内的表达式是file("e:\\file1.txt").cursor@z(;, ~:A2),其中函数cursor使用了选项@z,这表示将文件分段,用游标取其中的某一段。~:A2,这表示文件会被大致分为4段(A2=4),“~”是A2的当前成员,因此每个游标依次对应第1、第2、第3、第4段文件。
另外,之所以是“大致分”,是因为精确分会出现半行数据的情况,而集算器会去头补位,自动取出整行数据。JAVA要实现这种处理要麻烦得多。
A4=A3.(~.select(B1.find(~._1))),这句代码针对A3中的每个游标计算交集,计算结果是游标的集合。
A5=A4.conj@xm(),将A4中的多个游标进行并行合并。
A6=file("e:\\result.txt”).export(A5),将计算结果输出到文件中。到此为止,交集已经计算完成,差集和并集的计算可以参考之前的案例。
集算器可以独立使用,也可以和JAVA集成。下面通过JDBC将集算器脚本集成在JAVA里。JAVA代码如下:
//建立esProc jdbc连接
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
//调用esProc,其中test.dfx是脚本文件名
st =(com.esproc.jdbc.InternalCStatement)con.prepareCall("call test()");
st.execute();//执行esProc存储过程,也可以传入参数并传出计算结果。
对于第一个案例中的简单脚本,可以嵌入JAVA代码中直接执行,而不必编写脚本文件(text.dfx)。相应的JAVA代码如下:
ResultSet set=st.executeQuery("file(\"e:\\result.txt\").export([file(\"E:\\file1.txt\").cursor().sortx(_1),file(\"E:\\file2.txt\").cursor().sortx(_1)].merge@xi(_1))");