用webmagic实现的网络爬虫
网络蜘蛛(网络爬虫)Web Spider是一个非常形象的比喻,如果我们的网络是一个蜘蛛网,每个节点就是一个网站,联系每个节点的蜘蛛丝就是我们网站的连接。网络爬虫的原理其实不难理解——通过网页的链接地址来寻找网页,从 网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
网络爬虫的实现:
之前我共享了一个例子,它实现了最基本的网络爬虫——将网站的数据经过简单解析输出到控制台;
http://448230305.iteye.com/admin/blogs/2145296
可是在现实中我们不可能只是把它输出到控制台:很多情况下我们还有更复杂的需求;
1. 需要将它们存储到数据库;
2. 需要将它们存储到redis、文件里;
3. 并且我们还需要我们的爬虫识别已经爬过的网站,避免我们的存储设备中出现重复;
4. 对于一些需要登录的网站,我们需要让它实现模拟登录;
5. 某些网站是用前端渲染的,这些网站的数据从源码中不能直接看到,如何处理?
知识储备:
要解决这一问题:
首先我们需要对以下知识有了解:
Spring
MyBatis
MyBatis-Spring(http://mybatis.github.io/spring/zh/)
当然,学习最快的方法就是在网上找一个demo,然后按照那个demo自己实现一个,我这里为大家提供一个获取招聘信息的爬虫demo:jobhunter:
https://github.com/webmagic-io/jobhunter
在认真看懂这个demo之后,我们需要做的就是自己去实现一个demo;
1、目录结构:
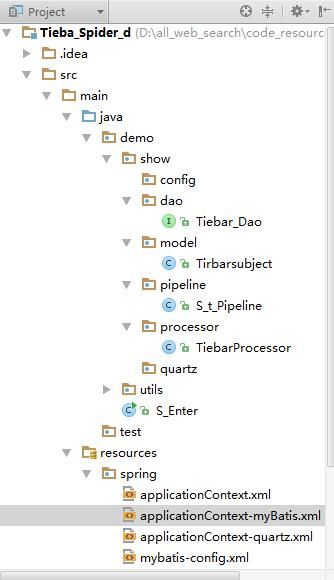
2、Resources:
Resources里存放着数据库连接的配置文件和spring-myBatis的配置文件:
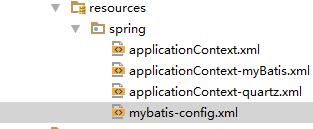
这些文件很多,我就不全部给大家看了~只给大家看一下数据库配置方面的:
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/search_show?characterEncoding=UTF-8" />
<property name="username" value="root" />
<property name="password" value="" />
</bean>
url、username、password分别对应数据库的地址、用户名、密码;
3、引用jar包:
我们这个工程使用的是idea+maven+git模式进行开发,没有用过这个模式的同学可自行脑补:
Idea:http://www.jetbrains.com/idea/
Maven:http://my.oschina.net/huangyong/blog/194583
Git:http://my.oschina.net/huangyong/blog/200075
顺便说一下:maven在配置环境变量时,最好配在系统变量里,第一次我配在环境变量里的时候就失败了。暂时还找不出原因……有知道的可以留言告诉我哦。
在maven中我们需要引用的jar包有:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!-- m2eclipse wtp 0.12+ enabled to configure contextRoot, add by w.vela -->
<m2eclipse.wtp.contextRoot>/</m2eclipse.wtp.contextRoot>
<spring-version>3.1.1.RELEASE</spring-version>
<spring-security-version>3.1.0.RELEASE</spring-security-version>
</properties>
<dependencies>
<dependency>
<groupId>us.codecraft</groupId>
<version>0.5.2</version>
<artifactId>webmagic-core</artifactId>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<version>0.5.2</version>
<artifactId>webmagic-extension</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>${spring-version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.1</version>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>2.5</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.18</version>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.7</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>${spring-version}</version>
<scope>test</scope>
</dependency>
4、Dao实现:
Dao是数据库交互的接口,sql语句就写在里面,我们看一下Tiebar_Dao,这里存放着对Tiebar主贴表的增删改查;
package demo.show.dao;
import demo.show.model.Tirbarsubject;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface Tiebar_Dao {
@Insert("insert into t_po_tieba (`TITLE`,`ADDRESS`,`DATETIME`,`CONTENT`,`HTS`,`USER`,`TB_TYPE`) values (#{title},#{address},#{dateTime},#{content},#{hts},#{user},#{tb_type})")
public int add(Tirbarsubject tir);
@Select("select PK_TIEBA_ID,ADDRESS from t_po_tieba")
public List<Tirbarsubject> get_resources();
@Select("select ADDRESS from t_po_tieba where ADDRESS=#{address}")
public Tirbarsubject get_resource(String Address);
}
当我们要使用这些操作时,直接调用这些方法就可以,逻辑里是看不到sql语句的;
5、Model:
细心的朋友可能会注意到,Tirbarsubject是我们定义在Model文件夹里的类,这个类就是我们数据库一个表的model;
package demo.show.model;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.model.AfterExtractor;
import us.codecraft.webmagic.model.annotation.Formatter;
import java.io.Serializable;
import java.util.Date;
/**
* Created by qxy on 2014-10-24.
*/
public class Tirbarsubject implements AfterExtractor,Serializable {
private int id;
private String title;
private String content;
@Formatter("yyyy-MM-dd HH:mm")
private Date dateTime;
private String address;
private int hts;
private String user;
private String tb_type;
public String toString() {
return "TiebaSubject{" +
"id=" + id +
", Title=" + title +
", DateTime=" + dateTime +
", Address='" + address + '\'' +
", Content='" + content + '\'' +
", Hts='"+hts+'\''+
", User='"+user+'\''+
'}';
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getTitle() {
return title;
}
…………………………
…………………………(中间的get和set方法我就不写了哈,篇幅有限)
public void setTb_type(String tb_type) {
this.tb_type = tb_type;
}
@Override
public void afterProcess(Page page) {
}
}
这里我们可以重写toString方法,如果不重写,它输出的是地址;
6、Process:
页面解析部分不是我们今天要讲的重点,不过我们这里提一下:
1、解析页面时解析的内容分为两部分:
我们需要爬的连接+我们需要解析的页面;我们需要解析的页面里包含着我们要爬的连接;不过也有可能存在我们需要爬出来的内容与我们需要爬的网页连接存在不同的页面(比如贴吧页面)
但是逻辑是一样的,一般情况下,我们要爬出来的页面的地址都是有相同规律的,在抓取连接时;我们可以使用Xpath对它的位置进行定位,过滤掉一些跟它结构相似但是放在网页不同位置的连接,接着使用正则表达式截取即可,在页面中加上一个if判断,满足条件即加入待抓取队列中:
if (page.getUrl().regex(URL_PAGE).match()){
System.out.println(page.getUrl().toString());
LB = page.getHtml().xpath("//div[@id='frs_list_pager']/").links().regex(URL_PAGE).all();
for(int i=0;i<LB.size();i++){
LB.set(i,"http://tieba.baidu.com"+LB.get(i));
}
page.addTargetRequests(LB);
NR = page.getHtml().links().regex(URL_CON).all();
page.addTargetRequests(NR);
}
接着我们将抓取的页面放入我们的数据库里:
首先是抓取:
else {
HT = page.getHtml().xpath("//li[@class='l_pager pager_theme_5 pb_list_pager']/").regex(URL_HUITIE).all();
for(int i=0;i<HT.size();i++){
HT.set(i,"http://tieba.baidu.com"+HT.get(i));
}
page.addTargetRequests(HT);
//解析页面
List<String> content_ht = new ArrayList<String>();
List<String> user_ht = new ArrayList<String>();
List<String> date_ht = new ArrayList<String>();
List<String> lc = new ArrayList<String>();
List<String> hufu_l = new ArrayList<String>();
String address_ht;
String address_zt=null;
List<Huitiesubject> huitiesubjects_l = new ArrayList<Huitiesubject>();
//主贴解析
String tb_type=page.getHtml().xpath("//*[@id=\"wd1\"]").regex("value=\"(.+?)\"").regex("[^value=\"].+[^\"]").toString();
String Title = page.getHtml().xpath("//div[@class='core_title core_title_theme_bright']/h1/text()").toString();
String Address = page.getUrl().toString();
String str_date = page.getHtml().xpath("//div[@id='j_p_postlist']/").regex(XEGEX_TIME).toString();
String Content = page.getHtml().xpath("//div[@id='j_p_postlist']/div[@class='l_post l_post_bright noborder']/div[@class='d_post_content_main d_post_content_firstfloor']/div[1]/cc/div/text()").toString();
String User = page.getHtml().xpath("//div[@id='j_p_postlist']/div[@class='l_post l_post_bright noborder']/div[@class='d_author']/ul/li[3]/a/text()").toString();
String Hts = page.getHtml().xpath("//*[@id='thread_theme_5']/div[1]/ul/li[2]/span[1]/text()").toString();
//回贴解析
content_ht = page.getHtml().xpath("//div[@id='j_p_postlist']//div[3]/div[1]/cc/div/text()").all();
user_ht = page.getHtml().xpath("//*[@id=\"j_p_postlist\"]/div/div[2]/ul/li[3]/a/text()").all();
date_ht = page.getHtml().xpath("//div[@id='j_p_postlist']/").regex(XEGEX_TIME).all();
lc = page.getHtml().xpath("//div[@id='j_p_postlist']/").regex("(post_no":\\d+)").regex("\\d+").all();
address_ht = Address;
String zhengz= "(.+/\\d*)";
Pattern p = Pattern.compile(zhengz);
Matcher m=p.matcher(Address);
接着,我们将他们存入数据库:
//主贴放入
tirbarsubject.setAddress(Address);
tirbarsubject.setTitle(Title);
tirbarsubject.setDateTime(Data_StrtoDate.ToYMDHM(str_date));
tirbarsubject.setContent(Content);
tirbarsubject.setUser(User);
tirbarsubject.setHts(Integer.parseInt(Hts));
tirbarsubject.setTb_type(tb_type);
//回帖放入
for (int i=0;i<user_ht.size();i++){
huitiesubject.setUser(user_ht.get(i));
huitiesubject.setContent(content_ht.get(i));
huitiesubject.setDateTime(Data_StrtoDate.ToYMDHM(date_ht.get(i)));
huitiesubject.setZt_address(address_zt);
huitiesubject.setAddress(address_ht);
huitiesubject.setLc(Integer.parseInt(lc.get(i)));
huitiesubjects_l.add(huitiesubject);
}
最后,将主贴的对象和回帖的对象放入page里:
page.putField("huifu_l", huitiesubjects_l);
page.putField("tir",tirbarsubject);
7、Pipeline:
Pipeline是将我们解析出来的数据存到数据库里的最后一步操作,代码比较少,也比较容易懂,我们就直接上代码吧:
package demo.show.pipeline;
import demo.show.dao.Huitie_Dao;
import demo.show.dao.Tiebar_Dao;
import demo.show.model.Huitiesubject;
import demo.show.model.Tirbarsubject;
import org.springframework.stereotype.Repository;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import javax.annotation.Resource;
import java.util.List;
@Repository("S_t_Pipeline")
public class S_t_Pipeline implements Pipeline {
@Resource
private Tiebar_Dao tiebar_dao;
@Resource
private Huitie_Dao huitiedao;
@Override
public void process(ResultItems resultItems, Task task) {
Tirbarsubject ts=resultItems.get("tir");
List<Huitiesubject> ht_l = resultItems.get("huifu_l");
Tirbarsubject Address = tiebar_dao.get_resource(ts.getAddress());
if(ts!=null&&Address==null&&ts.getUser()!=null) {
System.out.print("主题:"+ts.getTb_type()+"\n");
System.out.println("插入主贴 :" + tiebar_dao.add(ts));
}else{
System.out.println("ts is null");
}
for (int i=0;i<ht_l.size();i++){
if (ht_l!=null&&huitiedao.get_resource_addr(ht_l.get(i).getContent())==null){
// System.out.print("主贴地址:"+ht_l.get(i).getAddress()+"\n");
System.out.println("插入回帖 :" + huitiedao.add(ht_l.get(i)));
}
else {
System.out.println("huifu is null");
}
}
}
}
8、主函数:
package demo;
import demo.show.dao.Tiebar_Dao;
import demo.show.processor.TiebarProcessor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.stereotype.Controller;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.Pipeline;
import javax.annotation.Resource;
@Controller
public class S_Enter{
@Qualifier("S_t_Pipeline")
@Autowired(required = true)
private Pipeline S_t_Pipeline;
@Resource
private Tiebar_Dao tiebar_dao;
private String[] url_l = new String[3];
public String[] getUrl_l() {
return url_l;
}
public void setUrl_l(String[] url_l) {
this.url_l = url_l;
}
public void crawl(){
Spider.create(new TiebarProcessor()).addUrl(url_l).addPipeline(S_t_Pipeline).thread(5).run();
}
public static void main(String[] args) {
String[] url_l = new String[3];
url_l[0]="http://tieba.baidu.com/f?kw=湖南大学&pn=0";
url_l[1]="http://tieba.baidu.com/f?kw=古剑奇谭&pn=0";
url_l[2]="http://tieba.baidu.com/f?kw=暴走大事件&pn=0";
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("classpath:/spring/applicationContext*.xml");
S_Enter s_enter = applicationContext.getBean(S_Enter.class);
s_enter.setUrl_l(url_l);
s_enter.crawl();
}
}
结语:这就是使用webmagic框架实现的一个爬百度贴吧的爬虫,当然这个例子实现的只是对html的解析,对于那些使用js渲染的网页暂时还没有涉及,这些网页一般有两种方法,一个是使用浏览器模拟器,让爬虫将渲染好的页面下载下来,或者使用谷歌火狐浏览器中的审查元素功能去查看要爬的数据源。这也是比较麻烦的,所以爬虫也是一个非常考验人耐心的事情哦~~
<!--EndFragment-->