Twitter:使用Netty 4来减少GC开销
在twitter,需要网络功能的核心模块使用的都是Netty。
比方说:
- - Finagle是我们的协议无关的RPC系统,它的传输层是在Netty之上构建的,许多内部的服务都是通过它来实现的,比如说搜索服务。
- - TFE(Twitter Front End,Twitter前端)是我们专门的填鸭式反向代理,它使用Netty支撑了大部分面向公众的HTTP及SPDY的流量。
- - Cloudhopper每个月都通过Netty向世界各地的数百个移动运营商发送数十亿的短消息。
可能有的人还没听说过Netty,它是一款开源的Java NIO框架,能让你更容易编写出高性能的网络服务器。前一个版本的Netty 3使用Java对象来表示IO事件。这样做比较简单,但会产生大量的垃圾,尤其是在我们这种规模下。最新的版本Netty 4中做了一些改进,短生命周期的事件对象已经不复存在了,而是通过生命周期较长的管道对象来处理IO事件。 同时还有一个专门的缓冲区分配器,它使用缓冲区池来进行实现。
我们非常关注Netty项目的性能,可用性以及可持续性,也和Netty社区紧密合作以便全方位的对它进行完善。这里我们特别会提到的是,我们是如何使用Netty 3的,以及项目移植到Netty 4后带来的性能提升。
减少GC压力以及内存带宽的开销
Netty 3存在一个问题是,它依赖于JVM的内存管理来进行缓冲区的分配。只要有接收到新的消息或者是用户要发送远程消息,Netty 3就会在堆里分配一个缓冲区。也就是说每分配一个缓冲区就有一次new byte[capacity]操作。这些缓冲区给GC带来了压力,并且吞噬着内存的带宽:分配一个新的缓冲区,为了安全性需要给数组填0,而这会消耗内存带宽。然而填0的字节数组一般都会被真实的数据所填充,这同样也会消耗内存带宽。如果JVM可以提供一种方式来创建无需填充0的字节数组的话,就可以省掉50%的带宽了,不过现在还没有这样的办法。
为了解决这个问题,我们在Netty 4中做了如下的改进。
去除事件对象
Netty 4使用不同的方法来处理不同类型的事件,而不是直接创建事件对象。在Netty 3中, ChannelHandler使用一个单独的方法来处理所有的事件对象。
class Before implements ChannelUpstreamHandler { void handleUpstream(ctx, ChannelEvent e) {
if (e instanceof MessageEvent) { ... }
else if (e instanceof ChannelStateEvent) { ... }
...
}
}
而Netty 4会为每种事件类型分配一个处理方法:
class After implements ChannelInboundHandler { void channelActive(ctx) { ... }
void channelInactive(ctx) { ... }
void channelRead(ctx, msg) { ... }
void userEventTriggered(ctx, evt) { ... }
...
}
注意,这个handler还有一个‘userEventTriggered’方法,也就是说还可以通过它来创建一个自定义的事件对象。
缓冲区池
Netty 4引入了一个新的接口,’ByteBufAllocator。它通过这个接口提供了一个缓冲池的实现,这是jemalloc的一个纯Java的实现版本,它提供了伙伴分配器以及SLAB分配器的实现。
既然Netty已经有了自己的缓冲区内存分配器,就不会再因为给缓冲区填0而造成内存带宽的浪费了。然而,这种方式又带来了另一件麻烦事——引用计数。因为我们不再依赖GC来将不用的缓冲区放回池里,我们得自己去注意内存泄露的问题。哪怕只有一个handler忘了释放缓冲区都会导致整个服务器的内存使用率无限制的增长。
这么大的改动值得吗?
由于以上的这些改动,因此Netty 4不再向下兼容Netty 3。这也意味着我们用Netty 3构建的项目,必须花上相当一段时间来进行迁移。这样做值得吗?
我们比较了两个echo协议的服务器,分别用Netty 3和Netty 4进行开发(echo协议非 简单,因此如果产生了任何垃圾,那肯定是Netty造成的,而和协议无关)。我用分布式的echo协议客户端对它们进行访问,有16384个并发的连接,同时在不停地发送256字节的随机负荷包,几乎能让千兆以太网满负载地工作。
从我们的测试结果来看,Netty 4:
1. GC暂停的频率低了5倍:45.5 vs. 9.2 times/min
2. 产生垃圾的速度也降低了5倍:207.11 vs 41.81 MiB/s
我还想确认下缓冲区池的性能是不是也足够快。下图的X轴和Y轴分别代表的是每次分配的缓冲区的大小以及分配缓冲所需要的时间。
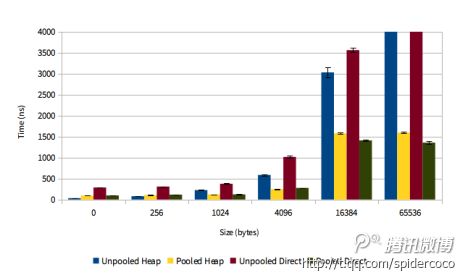
可以看到,随着缓冲区大小的增加,缓冲池的性能要比JVM更好。DirectBuffer的效果则更明显。然而,对于小的缓冲区而言,性能和JVM相比没有太大优势。这块我们还有不少工作要做。
尽管我们有些服务已经成功地迁移到Netty 4上了,但迁移是逐步来进行的,在这个过程中我们发现了一些问题,这阻碍了我们的迁移进度,希望在不久的将来这些问题能够得到解决:
1. 缓冲区泄露: Netty有一个简单的缓冲泄露报告机制,不过它提供的信息不够详细,难以迅速定位问题。
2. 核心功能足够简单:Netty是一个社区驱动的开源项目,因此核心功能越简单对使用者来说更好。而那些非核心的特性往往导致核心功能发生改动,这导致了Netty的核心功能的不稳定性。我们希望只有真正核心的特性才能留在核心库中,别的东西都通通闪开。
同时我们还希望能够加入以下的新特性:
- HTTP/2的实现
- 客户端HTTP和socks代理的支持
- 异步DNS解析
- Linux的本地扩展,这样可以直接通过JNI使用epoll
- 对连接划分优先级,确保严格的响应时间
加入我们
Netty有意思的一点就是来自全世界的不同的人,不同的公司都在使用它,而不仅仅是twiiter。它是一个独立地健康发展的开源项目,有许多的贡献者。如果你也对构建“未来的网络编程”兴趣的话,为什么不访问下项目的主页,关注@netty_project,打开GitHub上的源代码,甚至考虑下参与到改进Netty的工作中来呢?
鸣谢
Netty项目的创始人Trustin Lee,也在2011年加入我们,一起来进行Netty 4的完善工作。我们还要感谢来自TFE团队的Jeff Pinner,文中很多不错的想法都是他提出来的,并且他毫不犹豫的充当了我们的小白鼠。同样要感谢的还有,Norman Maurer,他是Netty代码的核心提交者之一,为了帮助我们把这些想法付诸实践,他付出了很多的努力 。还有许多人,他们积极体验了各种不稳定的版本,帮助我们试验了每一个改动的功能,这里没办法一一列举,里面特别要感谢的有:Berk Demir (@bd), Charles Yang (@cmyang), Evan Meagher (@evanm), Larry Hosken (@lahosken), Sonja Keserovic (@thesonjake), 以及Stu Hood (@stuhood)。
原创文章转载请注明出处: http://it.deepinmind.com
英文原文链接